Clear Sky Science · ar
بنية شبكة عصبية التفافية خفيفة لاكتشاف العنف في تسلسلات الفيديو
مراقبة الحشود ليقوم البشر بذلك نيابة عنهم
من الحفلات الموسيقية والمدارج الرياضية إلى محطات المترو ومراكز التسوق، تشاهد الكاميرات الآن كل مساحة مزدحمة تقريبًا. ومع ذلك، لا تزال معظم هذه البثوث تُراقَب بواسطة أعين بشرية متعبة يمكنها بسهولة أن تفشل في التقاط العلامات المبكرة لشجار أو تدافع. تستعرض هذه الورقة كيف أن شكلاً رشيقًا وسريعًا من الذكاء الاصطناعي يمكنه فحص الفيديو المباشر بحثًا عن سلوكيات عنف في الوقت الفعلي، حتى على أجهزة منخفضة التكلفة، لمساعدة فرق الأمن على الاستجابة بسرعة قبل أن تخرج المواقف عن السيطرة.
لماذا من الصعب كشف العنف في الفيديو
للوهلة الأولى، قد يبدو طلب من الحاسوب التمييز بين «شجار» و«لا شجار» بسيطًا: اكتشاف الأشخاص الذين يضربون بعضهم البعض. في الواقع، المشكلة معقدة. قد يكون الإضاءة ضعيفة أو تتغير فجأة، ويمكن أن تحجب الحشود الرؤية، وتُركب الكاميرات بزوايا متنوعة. يبدو حفل روك مزدحم فوضويًا حتى عندما لا يحدث شيء خطير، بينما تبدو مباراة ملاكمة عنيفة لكنها طبيعية تمامًا داخل الحلبة. كانت أنظمة الرؤية التقليدية تنظر إلى أنماط الحركة المصممة يدويًا والحواف إطارًا بإطار، وبينما نجحت في المختبر، كانت غالبًا بطيئة جدًا أو غير دقيقة بما يكفي لشبكات المراقبة الحقيقية والمزدحمة.
عقل أرفع لتغذية الكاميرات
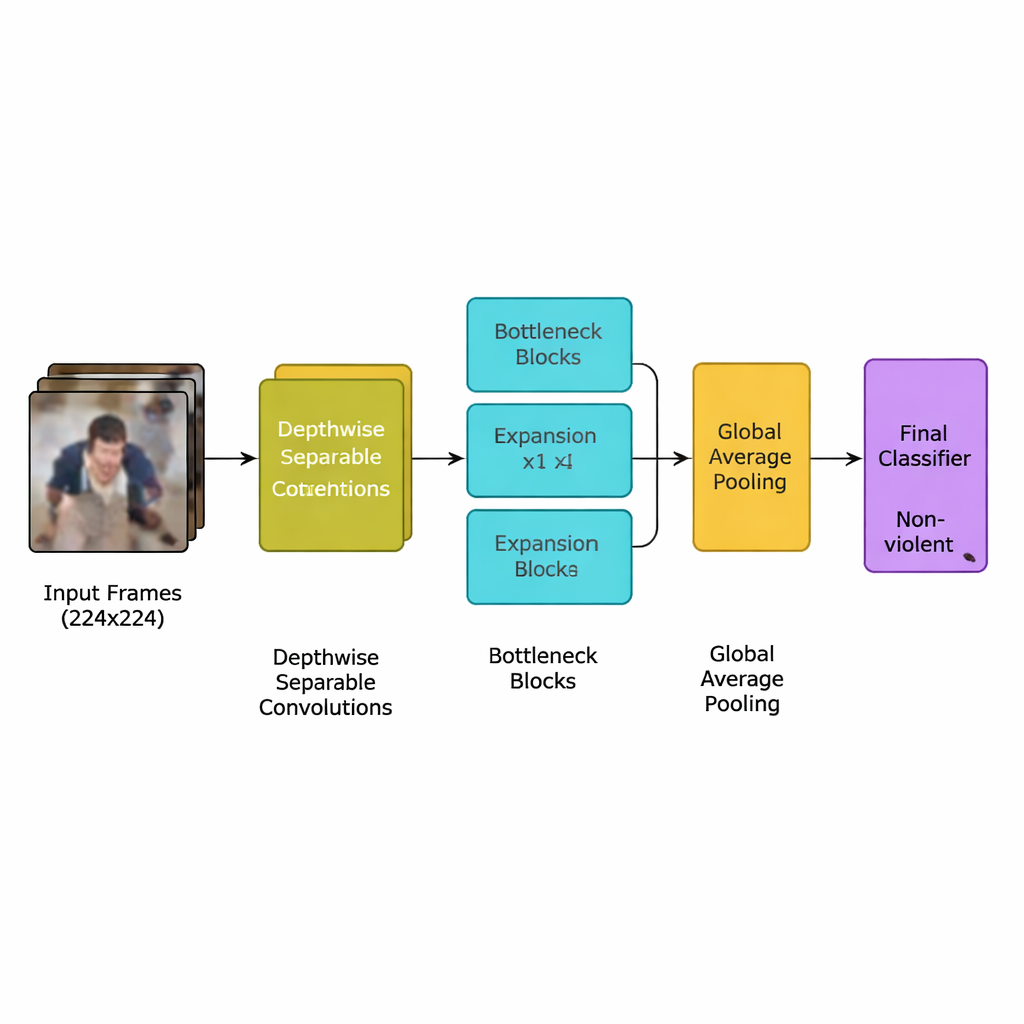
يقدم المؤلفون نموذج تعلم عميق جديد مصمم خصيصًا لهذه المهمة: شبكة عصبية التفافية خفيفة الوزن (CNN) مشتقة من عائلة فعالة من النماذج تُعرف باسم MobileNetV2. بدلًا من استخدام العديد من الطبقات الثقيلة التي تتطلب معالجات رسومية قوية، تعتمد الشبكة على الالتفافات القابلة للفصل حسب العمق—حسابات صغيرة ومحددة تقلل بشكل كبير من عدد العمليات الحسابية. كما تستخدم كتل "قنينة مقلوبة"، التي توسع المعلومات مؤقتًا ثم تضغطها للاحتفاظ بإشارات الحركة المهمة بينما تُسقط التكرار غير الضروري. وعلى هذا يضيف الفريق آلية انتباه تُدعى الضغط والتنشيط (squeeze-and-excitation)، التي تساعد الشبكة على التركيز على أنماط الحركة في المكان والزمان الأكثر دلالة على حوادث عنف، مع تجاهل تفاصيل الخلفية المشتتة.
من الفيديو الخام إلى تنبيهات العنف
يتبع النظام الكامل خط أنابيب واضحًا. أولًا، تُقسم البثوث الفيديوية إلى إطارات، ويُحتفظ فقط بكل إطار خامس لإزالة التكرارات القريبة مع الحفاظ على الحركات المفاجئة التي غالبًا ما تشير إلى شجار. تُعاد تحجيم الإطارات إلى معيار 224×224 بكسل، وتُطمس بلطف لتقليل ضوضاء الخلفية، ثم تُقلب أو تُدوَّر عشوائيًا أثناء التدريب حتى يتعلم النموذج التكيف مع زوايا كاميرا مختلفة. تدخل هذه الصور المحضرة إلى الشبكة الخفيفة، التي تحوّل تدريجيًا البيكسلات الخام إلى أنماط أعلى مستوى لسلوك الحشد. بعد خطوة تجميع نهائية تلخّص كل إطار، يخرج مصنّف صغير قرارًا بسيطًا: عنيف أم غير عنيف. وبما أن النموذج يستخدم نحو 1.94 مليون معلمة فقط—أقل من أسلافه MobileNet وMobileNetV2—يمكنه العمل في الوقت الحقيقي على أجهزة متواضعة موضوعة قرب الكاميرات بدلًا من مركز بيانات بعيد.
اختبار النظام عمليًا
لاختبار ما إذا كان هذا التصميم المدمج يمكنه منافسة الشبكات الأثقل، دربه الباحثون وقَيَّمُوه على مجموعتين معياريتين مستخدَمتين على نطاق واسع. يحتوي مجموعة بيانات حالات العنف في الحياة الواقعية على 2000 مقطع قصير مُجمَع من يوتيوب تظهر مشاهد يومية وشجارات حقيقية في مواقع متنوعة. وتقدم مجموعة بيانات شجارات الهوكي 1000 مقطع لمباريات هوكي محترفة، مقسمة بين اللعب العادي والمشاجرات على الجليد. على هاتين المجموعتين، صنَّف النموذج المقترح بشكل صحيح نحو 97 بالمئة من المقاطع في السيناريوهات الواقعية و94 بالمئة في لقطات الهوكي، موازيًا أو متفوقًا على شبكات CNN أكبر مثل InceptionV3 وVGG-19 مع استخدام حسابي أقل بكثير. أظهر الاختبار المتقاطع بين المجموعتين—التدريب على إحداهما والاختبار على الأخرى—أن النظام لا يزال يقدم أداءً معقولًا، ما يشير إلى أنه يلتقط أنماط حركة عامة بدلًا من حفظ بيئة واحدة فقط.
ماذا يعني هذا للسلامة اليومية
بالنسبة لغير المتخصصين، الخلاصة أنَّه أصبح بإمكاننا الآن بناء أنظمة كاميرات تضع علامات تلقائية على العنف المحتمل بسرعة وبثمن زهيد، دون الحاجة إلى خوادم ضخمة أو مراقبة بشرية دائمة. تُظهر الدراسة أن شبكة عصبية مُحَفَّفة ومضبوطة بعناية يمكنها مراقبة العديد من البثوث في آن واحد، وإرسال إنذارات عند اكتشاف سلوك خطير، والعمل على أجهزة منخفضة الاستهلاك مناسبة لمحاور النقل العام والمدارس والمستشفيات وشوارع المدينة. وبينما تظل تحديات قائمة—مثل التعامل مع المشاهد شديدة الظلام، والازدحام الكثيف، أو إضافة مؤشرات صوتية—يشير العمل إلى مستقبل تتصرف فيه الكاميرات الذكية كحساسات إنذار مبكر لا تكل، لمساعدة فرق الأمن على حماية الناس بشكل أكثر فعالية مع تقليل العبء على المراقبين البشريين.
الاستشهاد: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
الكلمات المفتاحية: اكتشاف العنف, مراقبة بالفيديو, شبكة عصبية التفافية خفيفة, MobileNetV2, السلامة العامة