Clear Sky Science · ar
الاستعادة عالية الدقة للوجوه الواقعية اعتمادًا على الشبكات التنافسية التوليدية وشبكات محاذاة الوجوه
وجوه أكثر وضوحًا من صور ضبابية
أي شخص حاول تكبير وجه من تسجيل قديم لكاميرا مراقبة أو من صورة صغيرة على وسائل التواصل الاجتماعي يعرف الإحباط: كلما كبرت الصورة، تحول الوجه إلى ضبابية وكتل بكسلية. يعرض هذا البحث نهجًا جديدًا في الذكاء الاصطناعي يمكنه تحويل مثل هذه صور الوجوه منخفضة الجودة في العالم الحقيقي إلى صور أكثر وضوحًا بكثير، مع الحفاظ بشكل أفضل على هوية الشخص وتعبيره. لذلك له آثار واضحة على كاميرات المراقبة، وتحليل الصور الجنائي، وحتى تطبيقات تحسين الصور اليومية.
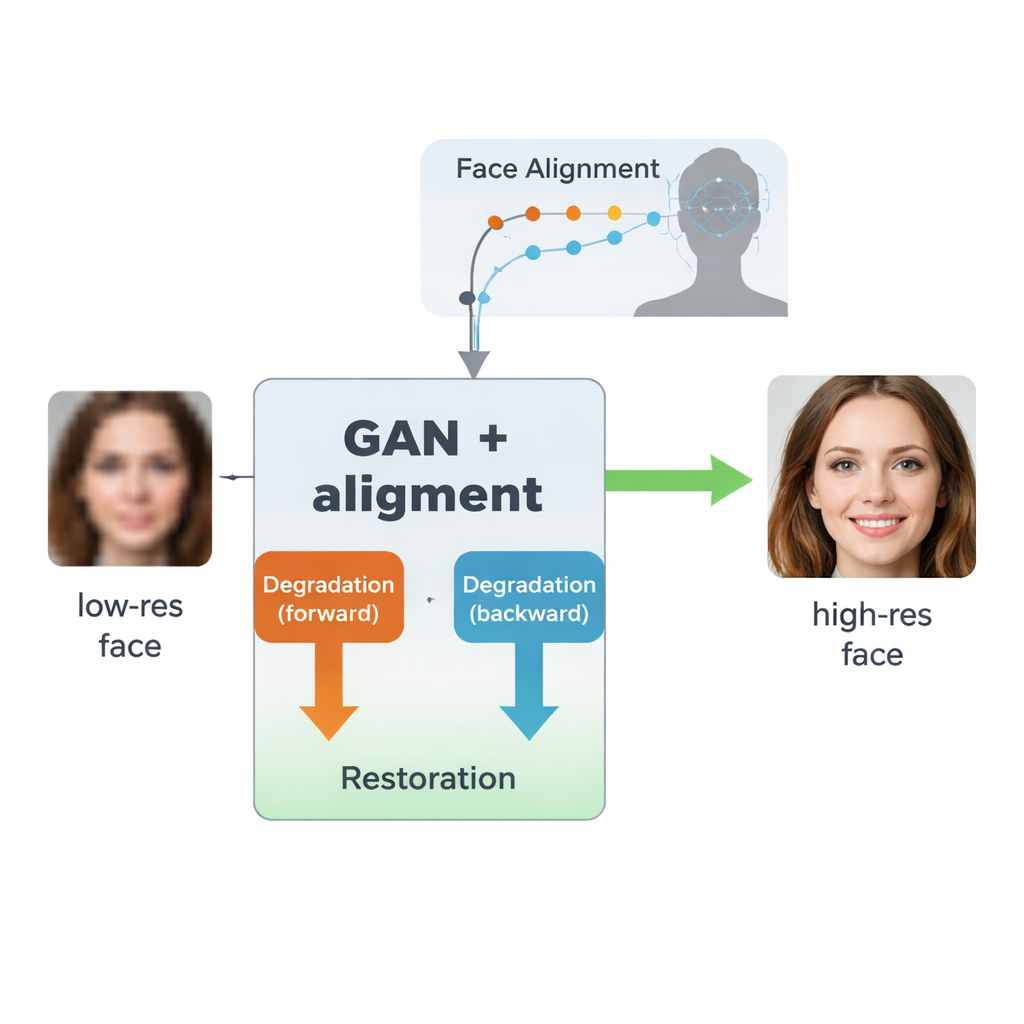
لماذا من الصعب إصلاح الوجوه الضبابية
جعل صورة وجه صغيرة وضبابية تبدو حادة ليس مجرد مسألة «إضافة بكسلات». اعتمدت الطرق التقليدية على قواعد مصممة يدويًا أو أنماط بسيطة، وتقنيات التعلم العميق الحديثة غالبًا ما تدربت على صور مُفسدة اصطناعيًا: خذ وجهًا واضحًا عالي الدقة، اقلله وطمسه، ثم علّم شبكة أن تعكس هذه العملية. المشكلة أن الصور الواقعية—مثل تلك من كاميرات المراقبة أو الفيديو المضغوط—تتعرض للتلف بطرق فوضوية وغير متوقعة. الضباب، والضوضاء، وتشوهات الضغط نادرًا ما تتطابق مع الأمثلة الاصطناعية المنظمة المستخدمة في التدريب، لذا النماذج التي تبدو رائعة في المختبر غالبًا ما تفشل على لقطات العالم الحقيقي. والأسوأ أنها قد تُنتج وجوهًا تبدو معقولة لكن لم تعد تشبه الشخص الأصلي.
حلقة تعلم ذات اتجاهين للصور الواقعية
يبني المؤلفون على نوع من الذكاء الاصطناعي يسمى الشبكة التنافسية التوليدية (GAN)، التي تتعلم إنشاء صور واقعية بمواجهة شبكتين عصبيتين لبعضهما: إحداهما تولّد الصور، والأخرى تقيم مدى واقعيتها. التصميم، المستلهم من نموذج سابق اسمه SCGAN، يستخدم بنية «نصف حلقيّة» مع حلقتين متكاملتين. في الحلقة الأمامية، تُفسد وجوه عالية الدقة حقيقية عمدًا بواسطة فرع واحد لإنتاج نسخ منخفضة الدقة اصطناعية، ثم تُستعاد بواسطة فرع استعادة مشترك. في الحلقة العكسية، تُحسّن وجوه العالم الحقيقي منخفضة الجودة بالفعل بواسطة نفس فرع الاستعادة ثم تُفسد مرة أخرى بواسطة فرع آخر لتشبه الصور منخفضة الدقة الحقيقية. عبر فرض الاتساق في كلا الاتجاهين—إفساد ثم استعادة، أو استعادة ثم إفساد—يتعلم النظام نموذجًا واقعيًا لكيفية تلف الوجوه في الممارسة، وكيفية عكس تلك العملية دون الحاجة مطلقًا إلى أزواج مطابقة تمامًا من صور منخفضة وعالية الجودة من العالم الحقيقي.
تعليم الشبكة كيف يبدو الوجه فعليًا
ابتكار رئيسي في هذا العمل هو تعليم النظام ليس فقط أن يجعل الصور تبدو أكثر وضوحًا، بل احترام البنية الأساسية للوجه البشري. لتحقيق ذلك، يدمج المؤلفون شبكة محاذاة وجوه منفصلة، صُممت في الأصل لتحديد المعالم مثل زوايا العينين، طرف الأنف، ومحاذير الفم. تتنبأ شبكة المحاذاة هذه بـ«خرائط حرارة» تبرز مكان كل معلم. أثناء التدريب، يقارن النموذج خرائط الحرارة من الصورة المستعادة بتلك الخاصة بوجه عالي الدقة حقيقي لنفس الشخص ويعاقب الاختلافات. والأهم أن ذلك يستخدم نموذج محاذاة مُدرّبًا مسبقًا ولا يتطلب وسوم معالم يدوية لكل صورة تدريب. النتيجة هي نوع من الإرشاد الهندسي: يتم دفع شبكة التحسين لوضع العيون والأنف والفم في المواقع والأشكال الصحيحة، بدلًا من مجرد طلاء الضباب بقوالب نسيجية شبيهة بالوجه.
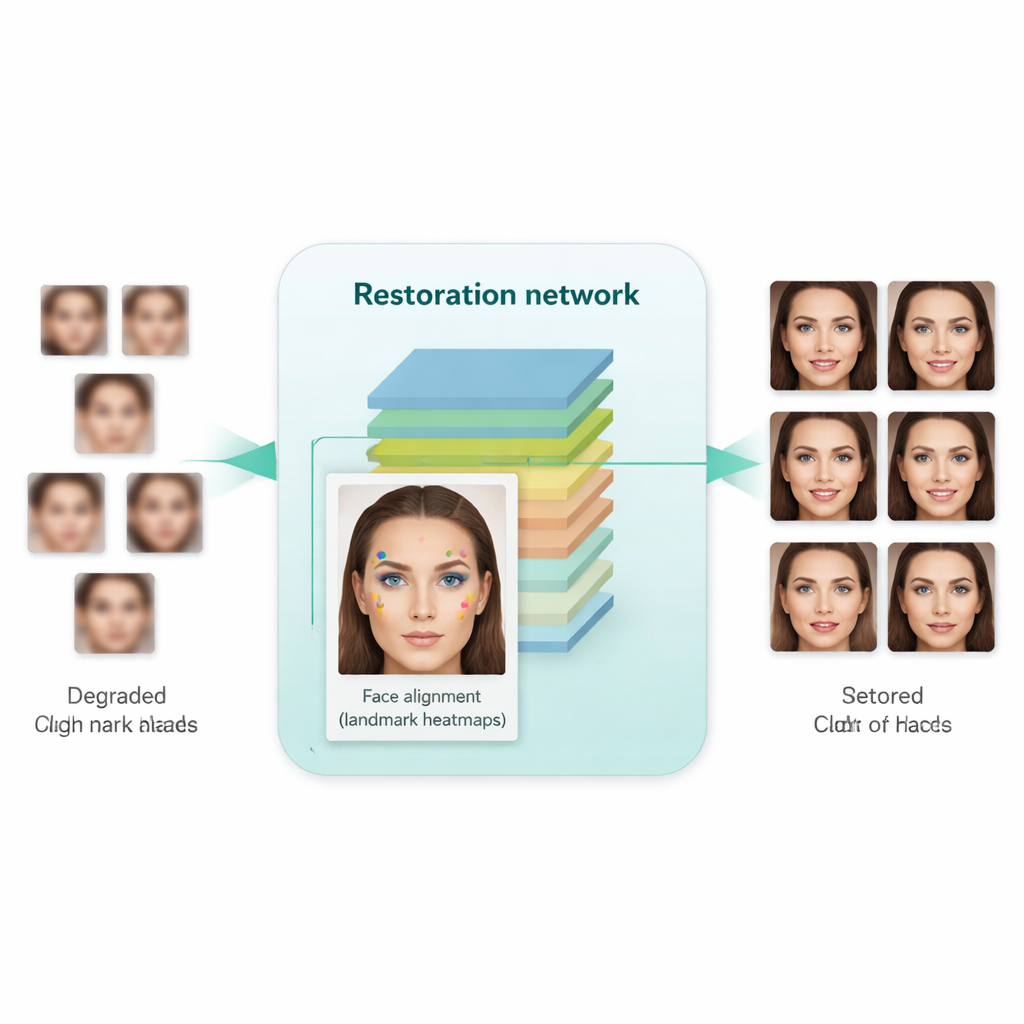
ما مدى فاعلية الطريقة عمليًا؟
درّب الباحثون نظامهم على مجموعة كبيرة من الوجوه عالية الجودة ومجموعة منفصلة من الوجوه منخفضة الجودة الحقيقية من مجموعات بيانات واقعية. ثم اختبروه على معايير تركيبية (حيث تتوفر صور أرضية نظيفة) وعلى صور العالم الحقيقي (حيث يمكن استخدام الواقعية البصرية والقياسات الإحصائية فقط). بالمقارنة مع طرق أقدم—بما في ذلك أدوات معروفة مثل Real-ESRGAN وGFPGAN وSCGAN الأصلي—أنتج النهج الجديد صورًا لم تبدُ فقط أكثر طبيعية وأقل تشوهًا، بل أدت أيضًا إلى أداء أفضل في مهام عملية. عندما أُدخلت الصور المحسّنة إلى مكتشفات الوجوه النموذجية ونموذج مشهور للتعرف على الوجوه (FaceNet)، تحسنت دقة الكشف والتحقق بشكل ملحوظ، ما يشير إلى أن تفاصيل متعلقة بالهوية حُفظت بشكل أفضل. في الوقت نفسه، أشارت مقاييس الجودة الآلية إلى أن الوجوه المولّدة كانت أقرب توزيعيًا إلى الصور الحقيقية عالية الدقة.
ماذا يعني هذا للاستخدام اليومي
بعبارات بسيطة، يُظهر هذا العمل أنه يمكنك الحصول على وجوه أداة أوثوقية أكبر وأكثر وضوحًا من صور منخفضة الجودة عن طريق دمج فكرتين: تعلم نموذج واقعي لكيفية تلف الصور في العالم الحقيقي، واستخدام معلومات معالم الوجه للحفاظ على بنية الوجه. بدلًا من «التخمين» ببساطة عن وجه أجمل، يُوجَّه النظام لإعادة إنشاء الشخص الصحيح بعيون وفم وشكل عام أوضح. هذا يجعل الطريقة واعدة بصورة خاصة لتطبيقات مثل الأمن، والطب الشرعي، والاستعادة الأرشيفية، حيث تكون كل من الوضوح البصري والهوية الصحيحة حاسمتين، وغالبًا لا تتوفر نسخ عالية الجودة من الصور الأصلية.
الاستشهاد: Fathy, H., Faheem, M.T. & Elbasiony, R. Real-world face super-resolution based on generative adversarial and face alignment networks. Sci Rep 16, 7492 (2026). https://doi.org/10.1038/s41598-026-37573-0
الكلمات المفتاحية: إعادة تكبير الوجوه, الشبكات التنافسية التوليدية, محاذاة الوجوه, التعرف على الوجوه, استعادة الصور