Clear Sky Science · ar
تعزيز الاسترجاع عبر الأنماط عبر تحسين شبكة التسميات ودوال الفقد الهجينة
البحث بذكاء أكبر عبر الصور والكلمات
نقوم يومياً بالتمرير عبر محيط من الصور ومقاطع الفيديو والنصوص. العثور على ما نريد بالضبط — على سبيل المثال كل الصور التي تطابق التسمية المختصرة — يعتمد على مدى قدرة الحواسيب على ربط الصور باللغة. تستكشف هذه الورقة طريقة جديدة لجعل ذلك الرابط أدق، لا سيما في المشاهد العالم-حقيقي الفوضوية حيث تظهر العديد من الأفكار والأشياء معاً. النتيجة هي أدوات بحث أكثر ذكاءً تفهم ما نعنيه بشكل أفضل، لا فقط ما نكتبه.
لماذا تهم تعدد المعاني في صورة واحدة
نادراً ما تعرض الصورة مفهوماً واحداً فقط. قد تتضمن صورة لحوت يخرج من الماء المحيط والسماء والأمواج والرياح والحياة البرية في آن واحد. عند وسم مثل هذه الصورة عادةً ما نرفق عدة تسميات تكون مترابطة بطرق دقيقة. أنظمة البحث الحالية تعامل هذه التسميات في الغالب كما لو كانت مربعات اختيار منفصلة غير مرتبطة. هذا التبسيط يتجاهل دلائل مفيدة: إذا كان "الحوت" يظهر غالباً مع "البحر"، فوجود أحدهما يجب أن يرفع احتمال الآخر. يركز هذا العمل على التقاط تلك الروابط الخفية بين التسميات بحيث يبحث طلب عن فكرة واحدة ويظل قادراً على العثور على الصور والنصوص التي تعبّر عن أفكار قريبة ذات صلة.

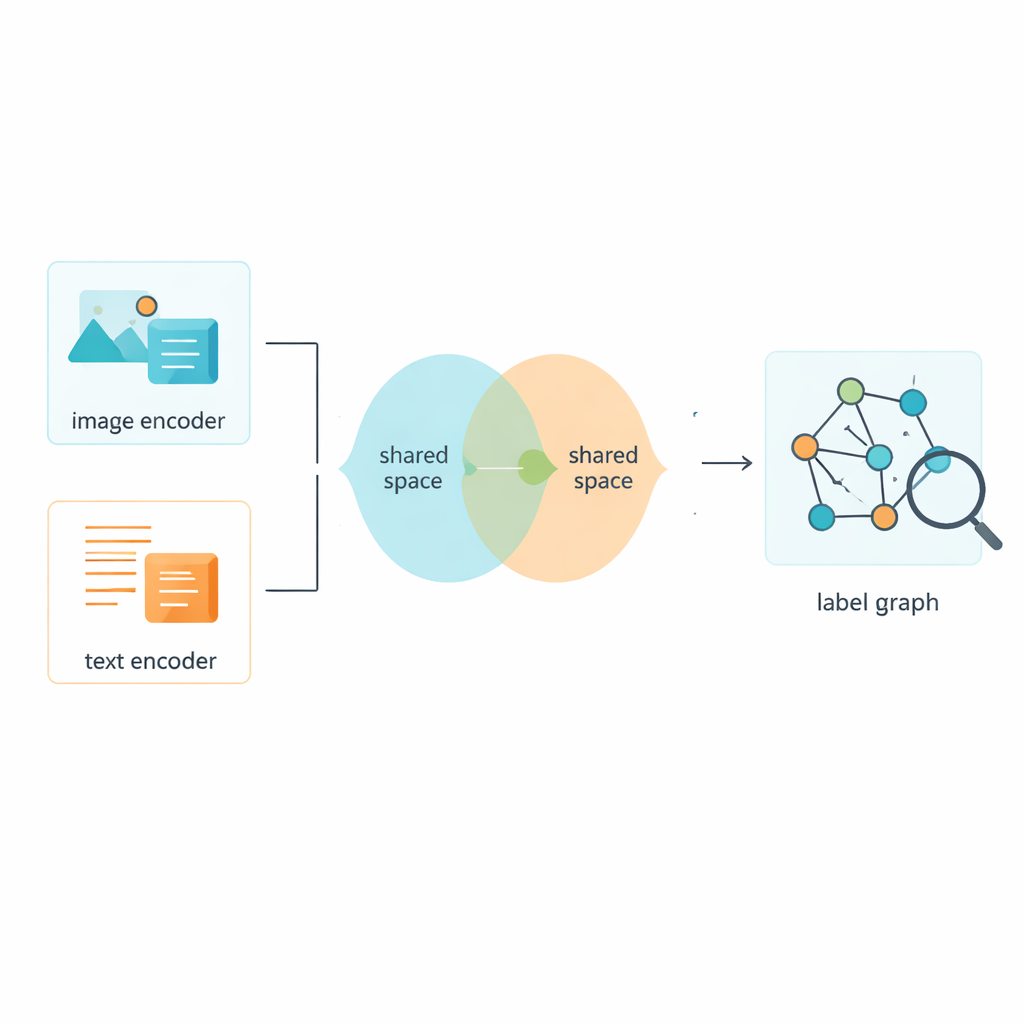
بناء شبكة من التسميات المترابطة
يقدّم المؤلفون تقنية تسمى شبكة الالتفاف الرسومية ذات طبقتين، أو L2-GCN، لنمذجة كيفية ارتباط التسميات ببعضها. ببساطة، تُعامل كل تسمية (مثل "السماء" أو "الحوت") كنقطة في شبكة، وتعبّر الحواف بين النقاط عن مدى تكرار ظهور تلك التسميات معاً. تتيح الطريقة لكل تسمية "الاستماع" مراراً إلى جيرانها، ودمج معلومات من التسميات ذات الصلة مع الحفاظ على هويتها الخاصة. بعد هذه العملية، يحصل النظام على أوصاف أغنى للتسميات تعكس بشكل أفضل كيف تُبنى المشاهد الحقيقية، من الأفكار المتوازية ("البحر" و"الشاطئ") إلى الهرمية منها ("حيوان" و"حوت").
تعليم الصور والنصوص مشاركة فضاء مشترك
بالطبع، التسميات ليست القصة الكاملة؛ يحتاج النظام أيضاً إلى التعلم من الصور والنصوص نفسها. يستخدم الإطار أدوات معروفة لتحويل البكسلات والكلمات الخام إلى ميزات رقمية، ثم يدفع كلا نوعي البيانات إلى فضاء مشترك يمكن مقارنة معانيهما فيه مباشرة. وحدة عدائية — مستوحاة بشكل فضفاض من ديناميكية الشبكات التوليدية العدائية — تمنع النموذج من التعلّق بخصوصيات الصور أو النصوص منفردة. يساعد ذلك الفضاء المشترك على التركيز على المحتوى بدل الشكل، بحيث تقترب صورة لشارع مزدحم وتسمية قصيرة تصفه من بعضهما في هذا الخريطة المشتركة للمعنى.
استراتيجية تدريب هجينة لتقسيمات أكثر وضوحاً
يتطلب تدريب مثل هذا النظام أكثر من قاعدة تعلم واحدة. صمم المؤلفون دالة فقد مشتركة، أطلقوا عليها Circle-Soft، تمزج فكرتين تكميليتين. جزء يشجع الأمثلة من نفس الفئة على التكتّل بإحكام بينما يدفع الفئات المختلفة بعيداً بطريقة مرنة وتكيفية. الجزء الآخر يركّز على مدى محاذاة الصور والنصوص التي تصف نفس المشهد عبر الصيغ. وزن قابل للضبط يوازن بين هذين الهدفين حتى لا يفرط النموذج في التوافق مع حدود الفئات المنظمة أو المحاذاة عبر الأنماط وحدها. خسائر تصنيفية وعدائية إضافية تشجّع كذلك الاتساق بين التسميات المنقّحة وميزّات الصورة-النص المشتركة.
ما مقدار التحسين في البحث؟
لاختبار ما إذا كانت هذه الأفكار تتحول إلى بحث أفضل، اختبر المؤلفون طريقتهم على ثلاث مجموعات شائعة من أزواج صورة-نص في العالم الحقيقي: MIRFlickr وNUS-WIDE وMS-COCO. تحتوي هذه المجموعات على آلاف إلى مئات الآلاف من الصور مع وسوم أو تسميات نصية، تغطي مشاهد يومية من شوارع المدن إلى الحياة البرية. عبر المعايير الثلاثة، تفوّق النهج الجديد باستمرار على مجموعة واسعة من الطرق المنافسة، بما في ذلك أنظمة متقدمة أخرى تستخدم بالفعل نمذجة التسميات القائمة على الرسوم البيانية. قد تبدو المكاسب — نحو نصف نقطة مئوية إلى نقطة مئوية كاملة في نتيجة استرجاع صارمة — متواضعة، لكن في معايير متقدمة حتى التحسينات الطفيفة تشير إلى فهم أدق للمحتوى. عملياً، يعني هذا أنه عندما يدخل المستخدم استعلاماً نصياً قصيراً أو يقدّم صورة، فالنظام أكثر احتمالاً أن يعرض أهم مطابقات عبر الأنماط في أعلى نتائج البحث.
ماذا يعني هذا للمستخدمين اليوميين
لغير المتخصصين، الرسالة الأساسية هي أن التعامل الأذكى مع التسميات وقواعد التدريب يمكن أن يحسّن بوضوح كيفية ربط الآلات بين الصور والكلمات. بمعاملة التسميات كشبكة مترابطة بدل وسمات معزولة، ومن خلال تشكيل لقاء المعلومات البصرية والنصية في فضاء مشترك بعناية، يجعل هذا الإطار البحث عبر الأنماط أكثر موثوقية في المشاهد المعقدة متعددة المواضيع. مع مرور الوقت، قد تمكّن تقنيات كهذه مكتبات صور أكثر فهماً، ومنصات وسائط أفضل، ومساعدين أذكياء يجدون ما نعنيه — حتى حين لا تطابق كلماتنا الصور تماماً.
الاستشهاد: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
الكلمات المفتاحية: استرجاع صورة-نص, بحث متعدد النماذج, شبكات عصبية رسومية, تسميات دلالية, تعلم الآلة