Clear Sky Science · ar
تحسين تمثيل المعرفة الطبية في نماذج اللغة الكبيرة عبر تحسين الرموز السريرية
لماذا يهم أن تقرأ الآلات الطبية بذكاء أكبر
خلف كل مساعد ذكاء اصطناعي طبي تكمن مهارة بسيطة لكنها حاسمة: كيف يقوم بتقسيم النص إلى أجزاء يمكنه فهمها. عندما يفشل هذا ‘‘التقطيع’’ — لا سيما للمصطلحات الطبية الصينية المعقدة — قد يفوت النظام أفكاراً أساسية في ملاحظات الأطباء أو في أسئلة المرضى. توضح هذه الورقة كيف أن تغييرًا صغيرًا ومحدّدًا في تلك الخطوة الأولى يمكن أن يجعل نماذج اللغة الكبيرة أفضل في القراءة والاستدلال والإجابة على الأسئلة المتعلقة بالبيانات الطبية الصينية، دون الحاجة لبناء نظام جديد بالكامل.
تقسيم النص إلى أجزاء بالطريقة الصحيحة
نماذج اللغة الحديثة لا تقرأ الحروف أو الكلمات مباشرة؛ بل تحول النص أولاً إلى وحدات قصيرة تُسمى رموزًا (tokens). بالنسبة للإنجليزية، ينجح هذا إلى حد بعيد لأن المسافات تحدد حدود الكلمات. أما الصينية فالأمر أعقد: لا توجد مسافات والعديد من التعبيرات الطبية عبارة عن عبارات طويلة ومتخصصة. تميل أدوات التقطيع القياسية، المصممة أساسًا للإنجليزية، إلى تقطيع هذه العبارات إلى شظايا عشوائية متعددة. عندما يرى النموذج اسم مرض أو فحص مختبري مقسّمًا إلى عدة قطع متفرقة، يصعب عليه تعلم معنى المصطلح الحقيقي، وقد تصبح إجاباته على الأسئلة الطبية غامضة أو غير دقيقة.
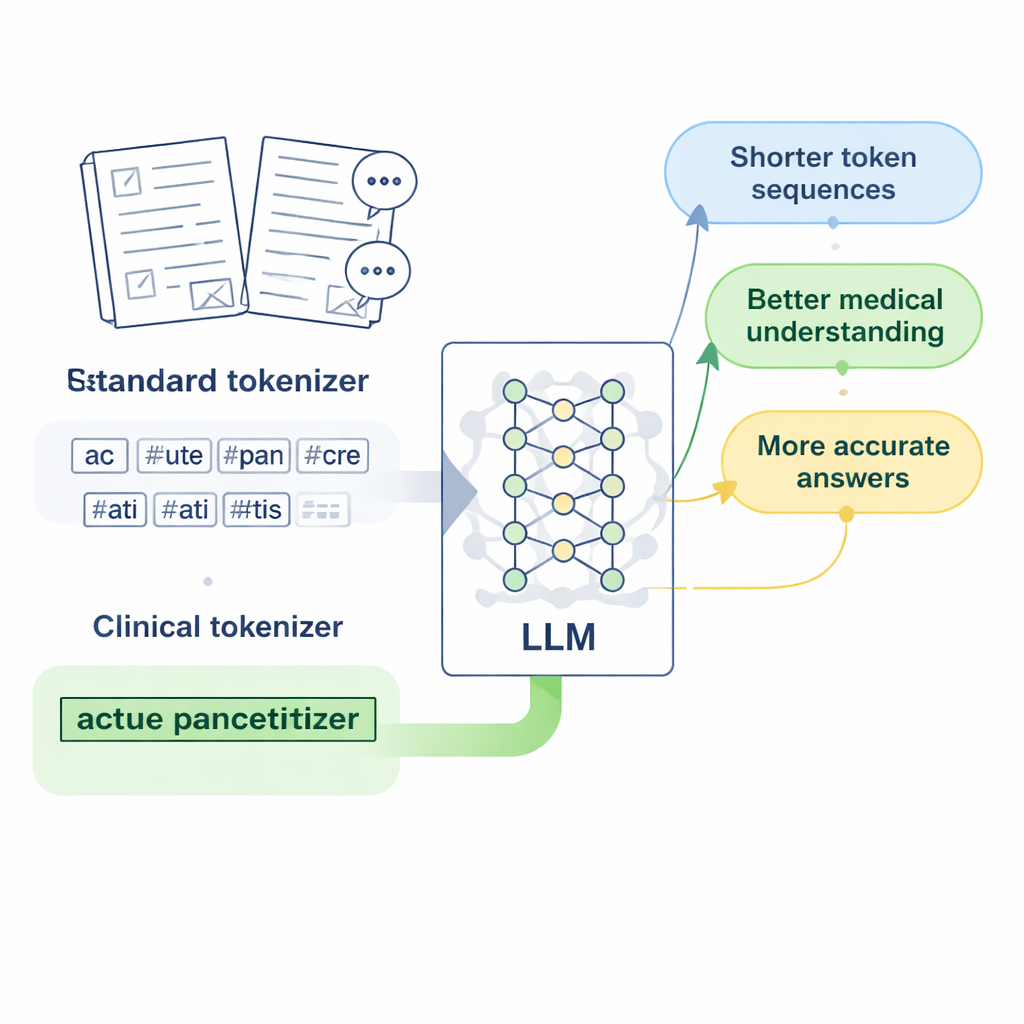
تصميم "رموز سريرية" للطب الصيني
ركز الباحثون على LLaMA2، وهو نموذج لغة كبير مفتوح المصدر شائع، وتساءلوا: ماذا لو علمنا ببساطة مُجزِّئه مفردات طبية أغنى؟ جمعوا مجموعات كبيرة من النصوص الطبية الصينية، بما في ذلك قواعد بيانات الطب الصيني التقليدي المحررة بعناية، وآلاف السجلات السريرية، وزوّار من أزواج الأسئلة والأجوبة بين الطبيب والمريض. باستخدام نسخة على مستوى البايت من خوارزمية الدمج بالزوج الأكثر تكرارًا (Byte Pair Encoding) المنفّذة عبر أداة SentencePiece، دربوا مُجزِّئًا جديدًا يتعلّم الحفاظ على التعابير الطبية الشائعة كوحدات مفردة. ثم دمجوا هذه الوحدات الجديدة، التي أطلق عليها المؤلفون اسم "الرموز السريرية"، في مفردات LLaMA2 الأصلية، فوسّعوا نطاقها لتغطي اللغة الطبية الصينية بشكل أفضل دون التخلص مما يعرفه النموذج بالفعل.
من رموز أفضل إلى نموذج طبي أفضل
إضافة رموز جديدة هي خطوة أولى فقط؛ يجب على النموذج أن يتعلم تمثيلات جيدة لها. عدّل الفريق طبقة التضمين الداخلية في LLaMA2 حتى تستطيع تخزين متجهات للمفردات الموسّعة واختبر طريقتين لتهيئة هذه المتجهات الجديدة. إحدى الطريقتين تحسب متوسط متجهات القطع الفرعية الأقدم لكل كلمة؛ أما الأخرى فتعتمد قيمًا عشوائية مُقاسة بعناية. وبشكل معاكس للحدس، أدت الطريقة العشوائية إلى أداء أفضل، ربما لأنها تتجنب قفل النموذج في تقدير أولي ضعيف لمعنى كل مصطلح. ثم واصل المؤلفون تدريب النموذج على نصوص طبية، ودوّبّوا نموذجه بأسلوب تعليمات Q&A طبية باستخدام طريقة فعّالة في الموارد تسمى LoRA، منتجين نسخة متخصصة أطلقوا عليها اسم Medical-LLaMA.
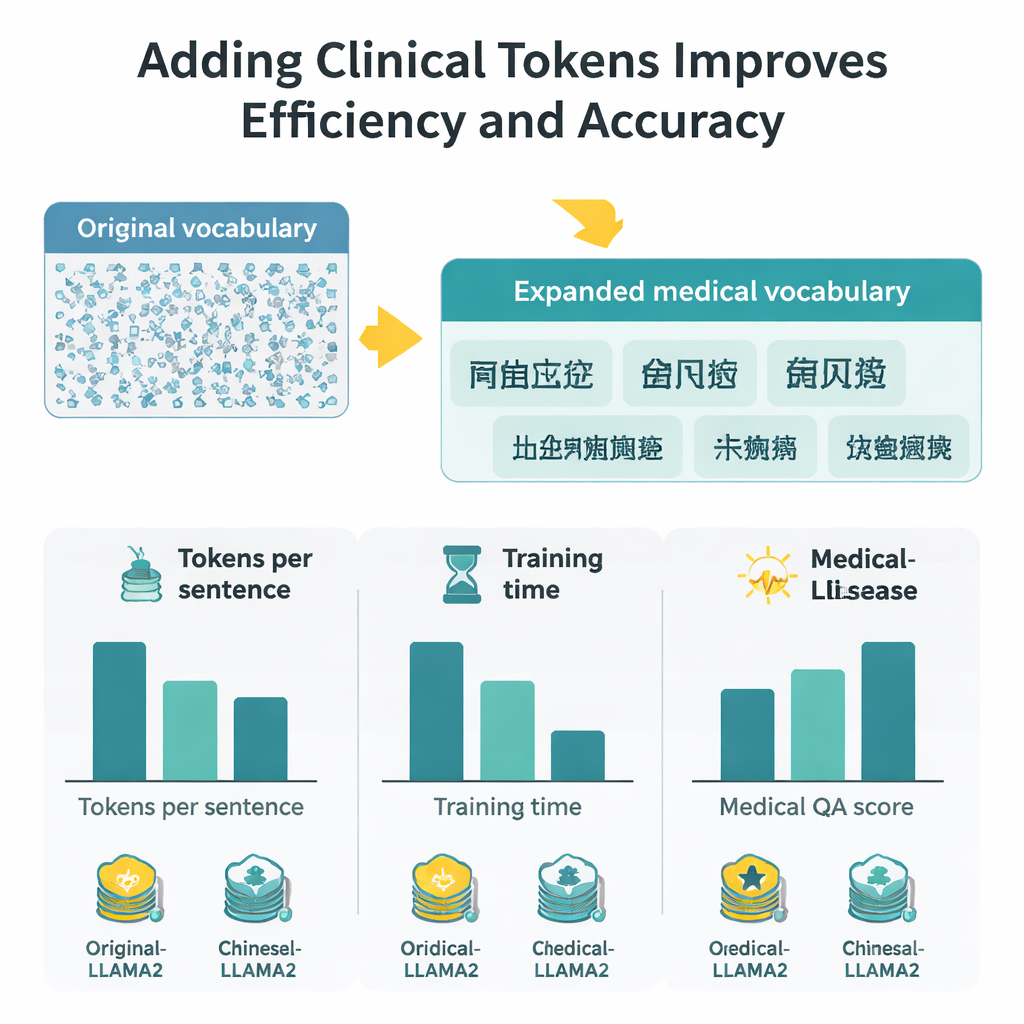
قياس المكاسب في السرعة والسياق والدقة
بفضل توسيع المفردات، يتطلب كل حرف صيني الآن نحو نصف عدد الرموز السابق، مما يعني أن النموذج يمكنه معالجة مقاطع أطول ضمن نافذة رموز ثابتة. عمليًا، يتضاعف طول السياق الفعّال للصينية تقريبًا، ويُختصر وقت الضبط الدقيق على مجموعة كبيرة من أسئلة وأجوبة طبية بنحو النصف. لتقييم جودة الإجابات، جمع المؤلفون استراتيجيتين للتقييم: BERTScore، التي تقيس مدى قرب إجابة مولدة من المرجع دلاليًا، ونموذج تقييم متقدّم (DeepSeek-R1) يقيس الصلة والدقة والشمول والطلاقة. عبر هذه المقاييس، يتفوق Medical-LLaMA باستمرار على كل من LLaMA2 الأصلي ونسخة مهيأة للصينية لم تتضمن رموزًا طبية خاصة. كما يظهر تحسينات صغيرة لكن متسقة في مهام ذات صلة مثل التعرف على الكيانات الطبية وتصنيف النصوص السريرية، مع الحفاظ على الأداء في الأسئلة العامة غير الطبية.
ماذا يعني هذا لمستقبل الذكاء الاصطناعي الطبي
بالنسبة لغير المتخصصين، الرسالة الأساسية هي أن "نظارات قراءة" أذكى للذكاء الاصطناعي — هنا، طريقة أفضل لتقسيم اللغة الطبية — يمكن أن تحسّن بشكل ملحوظ مدى فهمه وإجابته عن الأسئلة الصحية. عبر إدراج رموز سريرية مُختارة بعناية في مفردات نموذج قائم، يعزز المؤلفون كلًا من الفعالية والدقة دون الحاجة إلى دورات تدريبية جديدة ضخمة أو بُنى معمارية جديدة تمامًا. ومع أن العمل محدود بنموذج من 7 مليارات معامل ونصوص طبية صينية، إلا أنه يشير إلى وصفة عملية: خصّص الطبقة الأولى من معالجة اللغة للمجال، ثم أعد تدريبها بشكل خفيف. قد تساعد هذه الإستراتيجية أدوات الذكاء الاصطناعي الطبي المستقبلية لتصبح شركاء أكثر موثوقية للأطباء والمرضى، خصوصًا في اللغات والتخصصات التي تكافح النماذج القياسية في قراءتها.
الاستشهاد: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
الكلمات المفتاحية: نماذج اللغة الطبية, النصوص السريرية الصينية, التقطيع إلى رموز, المفردات السريرية, الإجابة على الأسئلة الطبية