Clear Sky Science · ar
AE-LFOG-YOLO: كشف خوذات الأمان المتين عبر مِرَسات تكيّفية وتعلّم مقاوم للتغيّر في الإضاءة
لماذا تهم فحوصات الخوذة الذكية
في مشاريع البناء الكبيرة وفي الأنفاق تحت الأرض، قد تكون خوذة الأمان البسيطة الفارق بين حادث بسيط وإصابة تغير الحياة. ومع ذلك، في فوضى مواقع العمل الواقعية ينسى الناس أو يتجاهلون ارتداء الخوذ، ولا يستطيع المشرفون البشريون مراقبة كل زاوية في كل الأوقات. تستكشف هذه الدراسة كيفية بناء نظام كاميرا آلي يكتشف بثقة مَن يرتدي خوذة ومَن لا يرتديها، حتى عندما يكون النفق خافت الإضاءة، أو مكتسحًا بتوهّج المصابيح، أو مكتظًا بالعمال على مسافات مختلفة من الكاميرا.
تحديات الرؤية تحت إضاءات نفقية قاسية
مواقع بناء الأنفاق أماكن بصرية متطرفة. المصابيح الساطعة تخلق توهّجًا بينما تخفي جيوب الظل العميق التفاصيل. يتحرك الناس قربًا وبعدًا عن الكاميرا، لذا تظهر خوذهم بأحجام مختلفة كثيرًا. غالبًا ما تفشل كواشف الذكاء الاصطناعي القياسية في هذه الظروف: تفوّت الخوذ في المناطق المظلمة، وتخلط بين أجسام مستديرة أخرى والخوذ، أو تعاني مع العمال الصغار جدًا أو البعيدين. تحاول أنظمة كثيرة إصلاح ذلك بتفتيح الصور أو تنظيفها قبل الكشف، أو بتعديل بعض مكوّنات نماذج اكتشاف الأشياء الشهيرة مثل YOLO. لكن لأن هذه الخطوات عادةً ما تكون حلولاً مُلحقة بدل أن تكون جزءًا من عملية تعلم موحدة، فإنها تترك أداءً غير مستغل ولا تكون متينة عندما تتغير الإضاءة أو تخطيط المشهد.
طريقة جديدة لتعليم الكاميرات تجاهل الإضاءة السيئة
يقترح المؤلفون نظامًا محسنًا يدعى AE‑LFOG‑YOLO، مبنيًا على كاشف YOLOv8 واسع الاستخدام. الفكرة الأساسية الأولى هي وحدة مقاومة للإضاءة، وهي وحدة صغيرة تُضاف داخل الشبكة تتعلم فصل «ما تفعله الإضاءة» عن «كيف تبدو الأشياء فعلاً». تقسم خريطة المميزات الواردة إلى جزء يعكس أنماط الإضاءة بشكل أساسي وجزء يلتقط الشكل والملمس الأكثر ثباتًا، مثل الحافة المنحنية للخوذة. باستخدام عمليات بوّابة خاصة وفرع يركّز على الحواف والزوايا، تقلل الوحدة من أثر تقلبات السطوع وتبرز الهندسة الثابتة. وبما أن هذا يحدث داخل الكاشف بدلاً من خطوة معالجة مسبقة منفصلة، يمكن تدريب النظام بأكمله تدريبًا نهائيًا موحّدًا للبقاء مركزًا على الخوذ نفسها بدل أن يضلّه بقع التوهّج أو العتمة.
ترك النموذج يطوّر عادات رؤيته بنفسه
الفكرة الرئيسية الثانية تستهدف كيفية تخمين الكاشف لمواقع ظهور الأشياء. يبدأ كثير من الكواشف من مجموعة ثابتة من «مربعات المرساة» التي تقترح أحجامًا وأشكالًا محتملة للأجسام؛ عادةً ما تُختار هذه مرة واحدة من بيانات التدريب ولا تُحدّث. في الأنفاق، مع ذلك، يمكن أن يتغير الحجم الظاهر للخوذة بشكل كبير مع مسافة الكاميرا وزاوية المشاهدة. يستبدل AE‑LFOG‑YOLO المراسي الثابتة بعملية دينامية تُسمى التوليد التكيفي التطوري المحسّن بحقل الإضاءة. في نهاية كل جولة تدريب، يزعزع النظام مراسه قليلاً، يقيس مدى ملاءمتها مع الخوذ الحقيقية بأحجام مختلفة، ويفحص أيضًا ما إذا كانت أبعادها منطقية بالاستناد إلى بصريات الكاميرا الأساسية—كم يجب أن يظهر حجم خوذة حقيقي على المستشعر عند مسافات عمل نموذجية. مجموعات المراسي التي تحقق درجات أفضل تبقى للجولة التالية. مع مرور الوقت، ‘‘يتطور’’ الكاشف إلى مراسي تناسب البيانات وتراعي أيضًا كيفية تصوير الكاميرات للعالم فعليًا.
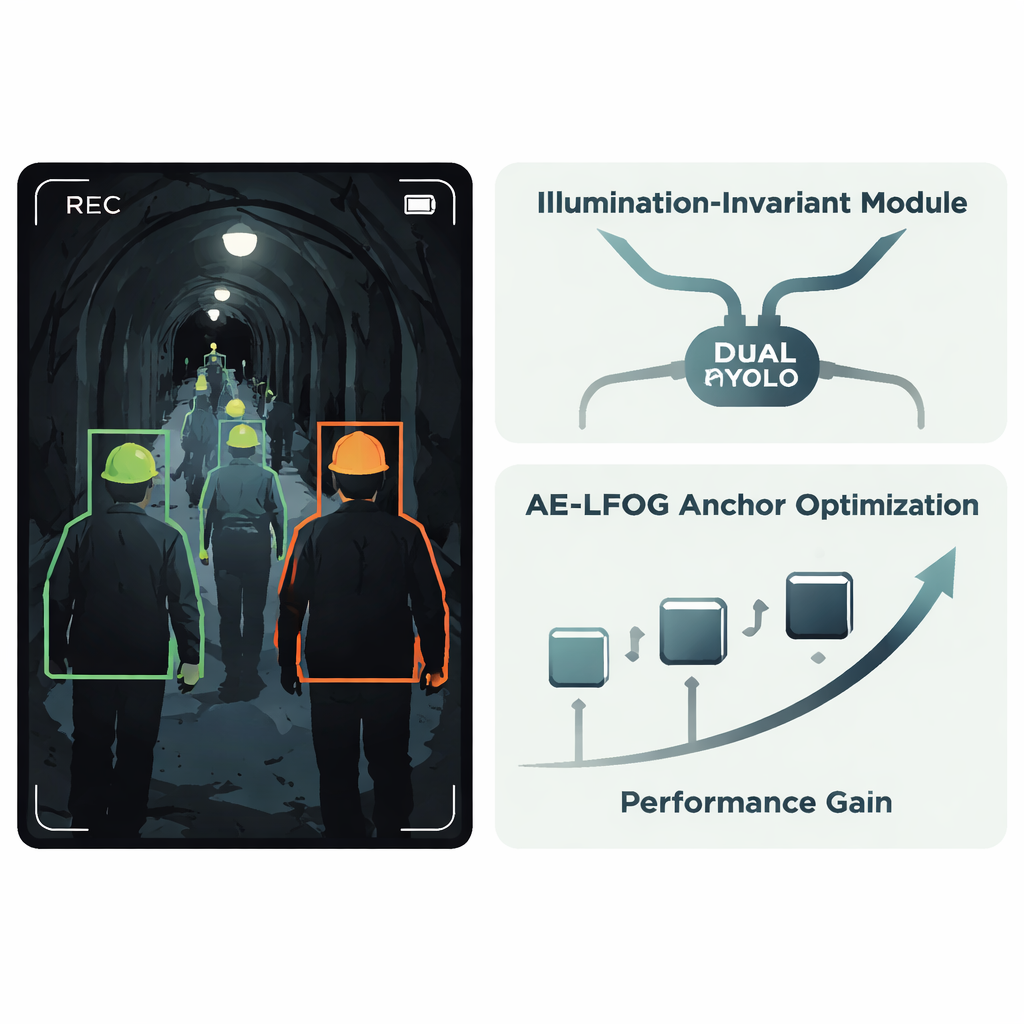
تكييف التدريب مع جودة الصور الواقعية
بعيدًا عن تغيير ما يبحث عنه النموذج، يغيّر المؤلفون أيضًا طريقة تعلّمه. يقدمون استراتيجية تدريب تولي اهتمامًا أكبر لتحديد مواقع الخوذ بدقة عندما تكون جودة الصورة سيئة، واهتمامًا أكبر لوضع العلامة الصحيحة خوذة مقابل لا‑خوذة عند تحسن الظروف. يخبر النظام نتيجة قائمة على قواعد فيزيائية، مشتقة مرة أخرى من مبادئ تصوير الكاميرا، بمدى موثوقية الصور في كل مرحلة. إذا كانت الإضاءة أو التركيز سيئين، ترفع عملية التدريب أهمية الحصول على مربعات التحديد الصحيحة تلقائيًا؛ وإذا تحسنت الظروف، تنتقل الثقل نحو التصنيف. يخلق هذا حلقة رد فعل يجعل النموذج يضبط أولوياته باستمرار ليتناسب مع البيئة الفيزيائية التي سيواجهها في الأنفاق الحقيقية.
ماذا تُظهر الاختبارات عمليًا
يختبر الباحثون منهجهم على مجموعة بيانات حقيقية لكشف خوذات الأنفاق ويقارنونه بعدة طرق متقدمة مبنية على YOLO. يكشف AE‑LFOG‑YOLO الخوذ بدقة عالية جدًا، محددًا نحو 95 بالمئة من الخوذ عند عتبة تداخل معيارية ومتفوّقًا على خط الأساس YOLOv8 العادي في كل من الدقّة والاسترجاع. يعمل بسرعة كافية للاستخدام في الوقت الحقيقي ويظهر قوة خاصة عندما تُعدّل الإضاءة بشكل كبير لمحاكاة ظلام متطرف أو تعرّض مفرط. تحت هذه الظروف الصعبة، يحافظ النموذج الجديد على ثقة أعلى، يكتشف المزيد من العمال الصغار والبُعيدين، ويعمل عبر نطاق سطوع أوسع بنسبة تزيد على الثلث مقارنة بالخط الأساس، مما يعني أنه يظل موثوقًا في مجموعة أكبر من المشاهد الواقعية.
كيف يساعد هذا في حماية العمال
لغير المتخصصين، الخلاصة واضحة: من خلال تعليم نظام الذكاء الاصطناعي لفهم ليس فقط البكسلات ولكن أيضًا فيزياء كيفية رؤية الكاميرات في بيئات صعبة، يقدم هذا العمل مراقبًا أذكى وأكثر موثوقية على جدران الأنفاق. يستطيع AE‑LFOG‑YOLO تجاهل الإضاءات المضللة والتكيّف مع تغيرات المنظور بشكل أفضل، ما يقلل حالات الفشل في الكشف والتنبيهات الكاذبة. عند نشره لعدة أشهر على خط نقل بالسكك العاملة، أظهر بالفعل أنه يمكنه دعم فرق السلامة في التأكد من ارتداء العمال لخوذهم، موفّرًا خطوة عملية نحو مواقع بناء أكثر أمانًا ومراقبة أدق.
الاستشهاد: Liu, S., Wang, J. AE-LFOG-YOLO: robust safety helmet detection via adaptive anchors and illumination invariant learning. Sci Rep 16, 6402 (2026). https://doi.org/10.1038/s41598-026-37326-z
الكلمات المفتاحية: كشف خوذات الأمان, بناء الأنفاق, رؤية حاسوبية, تصوير منخفض الإضاءة, YOLOv8