Clear Sky Science · ar
تقييم أداء محول مدرّب مسبقًا مولّد على امتحان الترخيص البيطري الوطني في اليابان
لماذا تهم امتحانات الطب البيطري الأذكى الجميع
خلف كل زيارة إلى مستشفى الحيوانات سنوات من التدريب الصارم وامتحان وطني عالي المخاطر. في اليابان، يجب على الراغبين في أن يصبحوا أطباء بيطريين اجتياز امتحان الترخيص البيطري الوطني (NVLE)، الذي يختبر كل شيء من علم الأحياء الأساسي إلى الحكم السريري المعقد. طرحت هذه الدراسة سؤالًا في الوقت المناسب: هل يمكن لنماذج اللغة المتقدمة الحالية، ذات النوعية التي تشغّل الدردشات الآلية الشهيرة، حل هذا الامتحان الصعب باللغة اليابانية — وماذا قد يعني ذلك للتعليم البيطري ورعاية الحيوانات؟
اختبار الذكاء الاصطناعي في امتحان ترخيص بيطري حقيقي
ركز الباحثون على ثلاثة أجيال من نماذج اللغة الكبيرة من OpenAI: GPT‑4o و o1 و o3. صُممت هذه الأنظمة لقراءة النصوص وإنتاج نصوص شبيهة بالبشر، لكنها لم تُدرّب خصيصًا على الطب البيطري. لاختبارها، استخدم الفريق الامتحان الوطني البيطري الياباني الـ74 (2023) كمرجع قياس. ينقسم الامتحان إلى خمس أقسام، بما في ذلك أسئلة نصية فقط وأسئلة تحتوي على صور تعرض صور أشعة أو صورًا أو رسومات بيانية. جميع الأسئلة اختيار من متعدد بخمس خيارات، تمامًا مثل الامتحان الحقيقي الذي يخوضه الطلاب. تم تزويد النماذج بكل سؤال عبر نص برمجي موحّد، وطُلب منها الرد فقط برقم الخيار المختار، دون فرصة "لشرح" أو التفاوض للحصول على رصيد.
أي نموذج ذكاء اصطناعي تصدّر النتائج؟
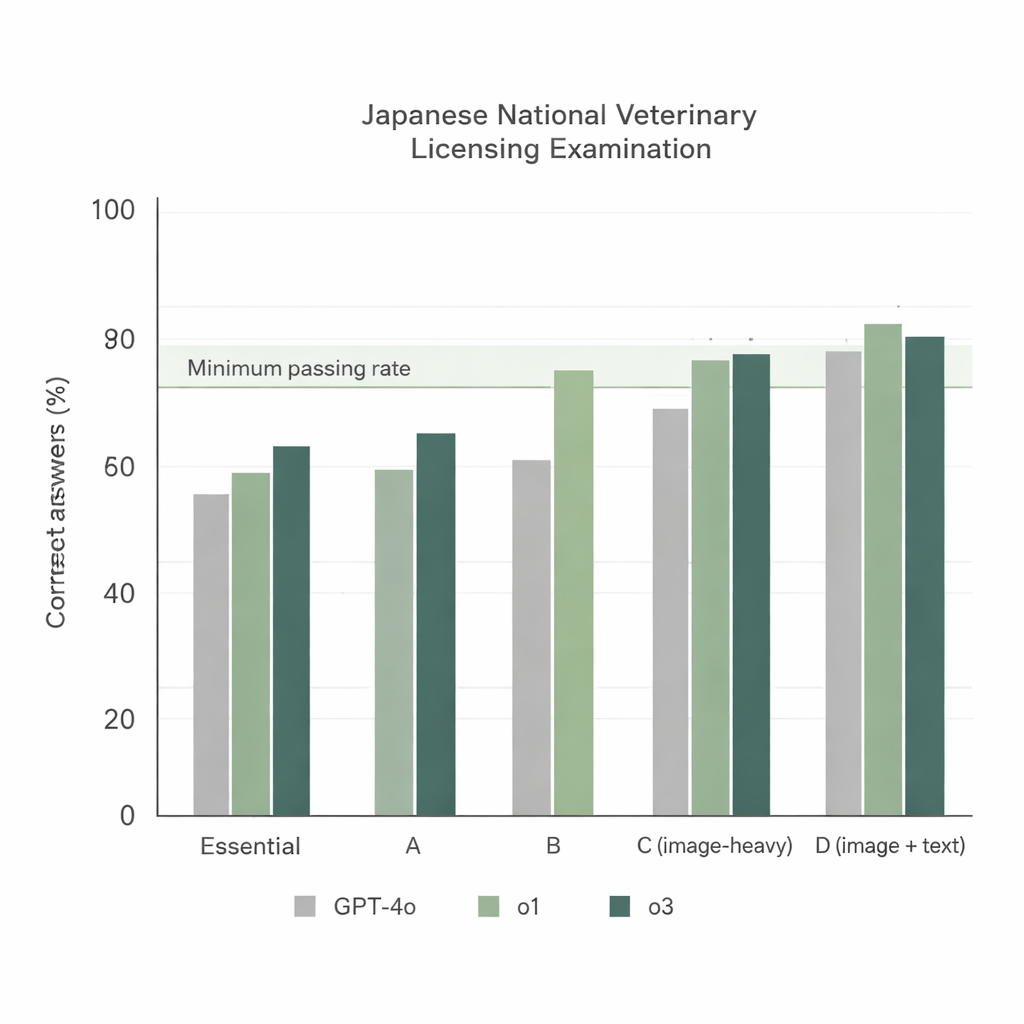
عندما واجهت النماذج الثلاثة الامتحان الـ74 باستخدام الإعداد الأبسط — أسئلة يابانية وتوجيه بسيط — برز اتجاهان واضحان. أولًا، أدّت جميع النماذج أداءً قويًا في الأقسام النصية، لكن o1 و o3 تفوّقا باستمرار على GPT‑4o. ثانيًا، انخفض الأداء في الأقسام الغنية بالصور، ومع ذلك ظل o1 و o3 فوق معدل النجاح الرسمي، في حين أخفق GPT‑4o في أحد هذه الأقسام. إجماليًا أجاب GPT‑4o بشكل صحيح على نحو 78% من الأسئلة، بينما بلغ أداء o1 نحو 92% وo3 نحو 93%. وبما أن o3 تفوّق قليلًا على o1 في المجموع الكلي، اختار الباحثون o3 لباقي التجارب.
هل التفاغير في التعليمات أو الترجمة مفيدة فعلاً؟
كُتب الكثير عن "هندسة المطالبات" — صياغة تعليمات معقدة لاستخراج إجابات أفضل من الذكاء الاصطناعي — وعن ترجمة أسئلة الامتحانات المحلية إلى الإنجليزية لمواءمة بيانات تدريب النماذج. اختبرت الدراسة هذه الأفكار مباشرة مع نموذج o3، بمقارنة مطالبة حل أساسية مقابل مطالبة مُحسّنة ومفصّلة، والأسئلة اليابانية الأصلية مقابل نسخ ترجمت إلى الإنجليزية أولًا بواسطة نفس النموذج. من المدهش أن أياً من هذه التغييرات لم يحدث فرقًا ذا دلالة: نجح o3 بشكل مريح في جميع التركيبات الست، وكانت أبسط طريقة (النص الياباني الأصلي مع المطالبة الأساسية) تعمل بنفس جودة الإعدادات الأكثر تعقيدًا. يشير ذلك إلى أن النماذج الأحدث تفهم اليابانية بشكل موثوق ولا تتطلب مطالبات معقّدة لأداء عالٍ في هذه الأسئلة البيطرية.
ما مدى استقرار الأداء على الامتحانات الأحدث؟
لمعرفة ما إذا كانت النتائج القوية صدفية، اختبر الفريق بعد ذلك o3 على الامتحانين الـ75 (2024) والـ76 (2025)، مجددًا باستخدام الأسئلة اليابانية الأصلية فقط والمطالبة العادية. حقق النموذج درجات إجمالية تزيد على 92% في كلا الامتحانين وتجاوز عتبة النجاح في كل قسم، بما في ذلك مجالات الصور الثقيلة. حصلت معظم الأسئلة على نفس الإجابة عبر ثلاث محاولات مستقلة، ما يدل على أن استجابات o3 كانت عامةً مستقرة حتى عند السماح ببعض العشوائية. عند فحص الأخطاء عن كثب، وجد الباحثون أن الأخطاء تتركّز في مجالين: المعرفة البيطرية العملية (مثل القوانين البيطرية اليابانية) والطب السريري، وهما مجالان يتطلبان قواعد خاصة بكل بلد وتفكيرًا متعدد المراحل بدلًا من استدعاء حقائق بسيطة.
ماذا يعني هذا — وماذا لا يعني
تخلص الدراسة إلى أن نماذج على غرار GPT المتطورة تستطيع الآن اجتياز امتحان الترخيص البيطري في اليابان باللغة اليابانية، دون حيل الترجمة أو المطالبات المعقدة. بالنسبة لكليات الطب البيطري والطلاب، يفتح هذا الباب لاستخدام الذكاء الاصطناعي كشريك دراسي، أو مولّد أسئلة، أو مفسّر لموضوعات الامتحان. وللجمهور، يشير ذلك إلى أن الذكاء الاصطناعي يتحول إلى أداة قوية لتنظيم ومشاركة المعرفة البيطرية. مع ذلك، يؤكد المؤلفون أن هذه الأنظمة ليست جاهزة لاستبدال الأطباء البيطريين أو لاتخاذ قرارات طبية بمفردها. لا تزال النماذج قد تُسيء فهم الصور، وتواجه صعوبة في الحكم السريري الدقيق، وأحيانًا تختلق حقائق. عند استخدامها بحذر، قد تصبح مساعدين قيّمين في التعليم البيطري ودعم المعلومات — لكن تظل مسؤولية صحة الحيوان بيد البشر بشكل قاطع.
الاستشهاد: Kako, T., Kato, D., Iguchi, T. et al. Performance evaluation of generative pre-trained transformer on the National Veterinary Licensing Examination in Japan. Sci Rep 16, 4306 (2026). https://doi.org/10.1038/s41598-026-37300-9
الكلمات المفتاحية: امتحانات ترخيص الطب البيطري, نماذج اللغة الكبيرة, الذكاء الاصطناعي في الطب, أداء GPT, التعليم البيطري الياباني