Clear Sky Science · ar
تأثير اختيار K في التحقق المتقاطع K‑fold على الانحياز والتباين في نماذج التعلم الموجّه
لماذا يهم أن تختبر نموذجك مرتين فعلاً
من التشخيص الطبي إلى تقييم الائتمان، تعتمد العديد من القرارات الآن على نماذج التعلم الآلي المدربة على بيانات سابقة. ولكن كيف نعرف ما إذا كان نموذج يبدو جيدًا على شاشة حاسوبنا سيتصرف جيدًا مع حالات جديدة لم تُرَ من قبل؟ طريقة شائعة "لاختبار" النماذج هي التحقق المتقاطع k‑fold، حيث تُقسّم البيانات مرارًا إلى أجزاء للتدريب والاختبار. تطرح هذه الدراسة سؤالًا بسيطًا مخادعًا لكنه حاسم: كم عدد الأجزاء — ما حجم k المناسب — وكيف يشكّل هذا الاختيار بهدوء موثوقية أداء النموذج المبلغ عنه؟
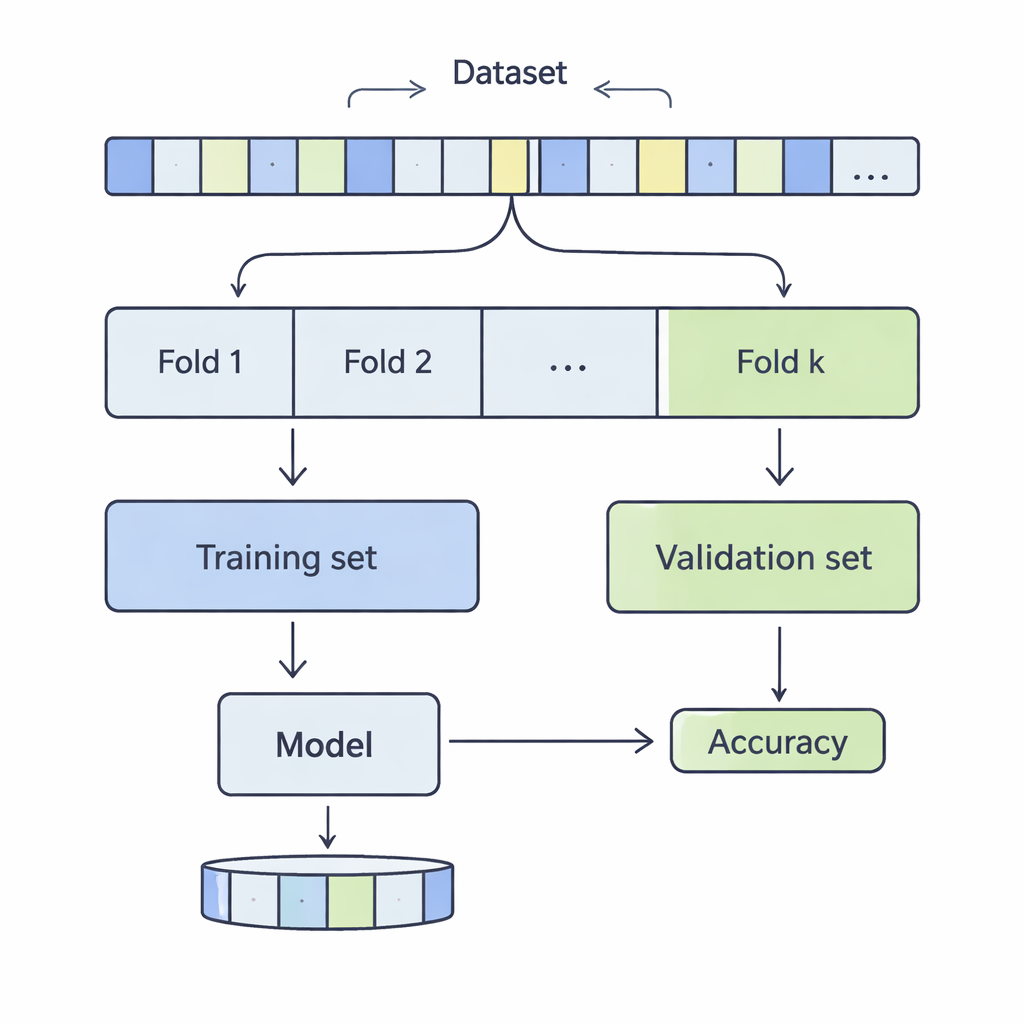
كيف تُقسَم البيانات للتحقق من الواقع
في التحقق المتقاطع k‑fold، تُخلط مجموعة البيانات وتقسم إلى k أجزاء متساوية، أو طيات. يُدرّب النموذج على k‑1 من هذه الطيات ويُقَيّم على الطية المتبقية؛ وتتكرر هذه العملية حتى تأخذ كل طية دورها كجزء اختبار. فحص المؤلفون قيم k من 3 إلى 20، عبر 12 مجموعة بيانات من العالم الحقيقي تتراوح من بضعة آلاف إلى أكثر من نصف مليون سجل، وتغطي مجالات مثل توقع الدخل، والنتائج الطبية، والهجمات السيبرانية، والألعاب، وجودة النبيذ. طبقوا أربعة طرق تصنيف شائعة — آلات الدعم الناقل (SVM)، أشجار القرار، الانحدار اللوجستي، والجيران الأقرب k‑Nearest Neighbours — وقاسوا بعناية كيف يؤثر اختيار k على جانبي الأداء الرئيسيين: الانحياز والتباين.
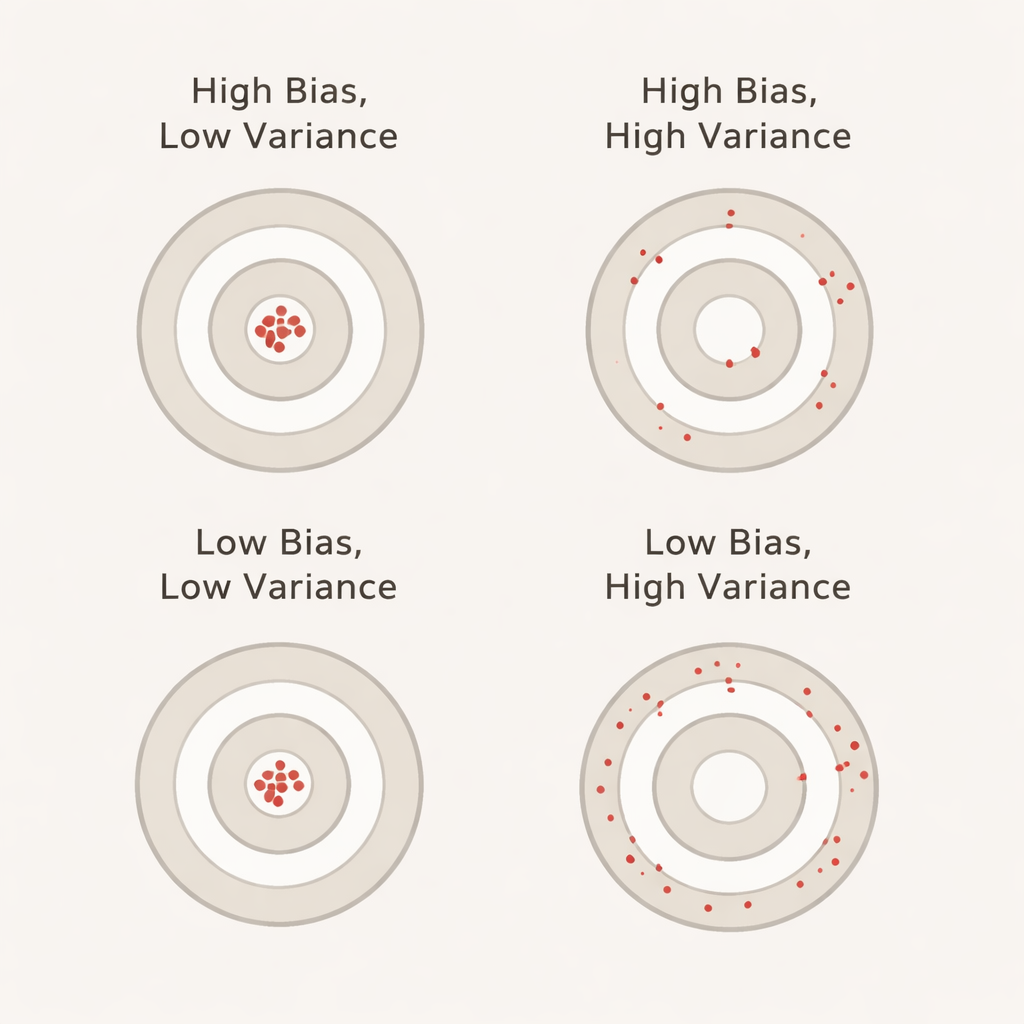
ما المقصود بالانحياز والتباين بمصطلحات يومية
الانحياز، في هذا السياق، يعكس إلى أي مدى يبدو النموذج أنه يعمل بشكل أفضل أثناء التحقق المتقاطع عما هو عليه فعليًا على مجموعة اختبار منفصلة لم تُلمس. الانحياز الإيجابي الكبير يعني أن النموذج يبدو متفائلًا بشكل مفرط أثناء التحقق — مثل طالب يحرز درجة مثالية في الاختبارات التدريبية لكنه يتعثر في الامتحان الحقيقي. يعكس التباين مقدار تقلب أداء النموذج من طية إلى أخرى: التباين المنخفض يعني أن الدرجات ثابتة عبر شرائح البيانات المختلفة، بينما التباين العالي يعني أنها تتقلب صعودًا وهبوطًا. من المثالي أن نريد كلًا من الانحياز والتباين منخفضين حتى تكون الدقة المبلغ عنها واقعية ومستقرة.
ماذا يحدث عندما نزيد عدد الطيات
عبر جميع المجموعات الاثنتي عشرة وكل الخوارزميات الأربع، برز نمط واحد بقوة: مع زيادة k ارتفع التباين في الغالب. بعبارة أخرى، جعل استخدام طيات أكثر الدقة المبلغ عنها أقل استقرارًا من طية لأخرى. هذا يتعارض مع الاعتقاد الشائع أن المزيد من الطيات يعطي تقديرات أفضل وأكثر موثوقية تلقائيًا. السبب أن عندما تكون k كبيرة، تصبح كل شريحة تحقق صغيرة جدًا وأقل تمثيلاً، فتصبح النتائج أكثر حساسية لخصائص عشوائية في البيانات. في الوقت نفسه، تصرّف الانحياز كان أقل انتظامًا. بالنسبة إلى خوارزميات الجيران الأقرب وآلات الدعم الناقل، اتجه الانحياز عادةً للارتفاع مع زيادة k، ما يعني أن هذه النماذج غالبًا ما بدت أكثر دقة في التحقق المتقاطع مما كانت عليه في مجموعة الاختبار المحتفظ بها. أظهرت أشجار القرار أنماطًا متوازنة تقريبًا، وجاء الانحدار اللوجستي في المنتصف، مع تغيّرات انحياز مختلطة لكنها أكثر اعتدالًا.
لماذا قد تكون "الإعدادات القياسية" مضللة
تقترح معظم الأدلة العملية ببساطة استخدام خمس أو عشر طيات، بغض النظر عن مجموعة البيانات أو خوارزمية التعلم. يُظهر تحليل المؤلفين أن مثل هذه النصيحة الموحدة قد تكون مضللة. في بعض مجموعات البيانات ولأجل بعض النماذج، ضخت قيم k الأعلى انطباعات متفائلة مفرطة عن الأداء؛ وعلى جميعها، جلبت المزيد من الطيات مزيدًا من التباين في التقديرات. هذا مقلق بشكل خاص في مجالات عالية المخاطر مثل الرعاية الصحية والتمويل والبنية التحتية، حيث يمكن أن يؤدي الثقة الزائفة في دقة نموذج إلى تبعات في العالم الحقيقي. تجادل الدراسة بأن آثار k تعتمد على طبيعة البيانات (صغيرة مقابل كبيرة، ضوضاء مقابل أنقى) وعلى كيفية تعلم الخوارزمية المحددة من مجموعات تدريب متكررة متقاربة جدًا.
الخلاصة لكل من يستخدم التعلم الآلي
الدرس المركزي هو أن عدد الطيات في التحقق المتقاطع ليس تفصيلًا تقنيًا غير مؤذ — إنه يشكل مباشرة مدى موثوقية أرقام الدقة لديك. في هذه التجارب، جعلت الطيات الأكثر النتائج أكثر تقلبًا باستمرار وغالبًا جعلت بعض النماذج تبدو أفضل مما كانت فعلاً. بدلًا من اختيار k=5 أو k=10 بعشوائية، يوصي المؤلفون بالتعامل مع k كمقبض ضبط: تفحص كيف تتغير النتائج عبر نطاق صغير من قيم k وانظر، حيثما أمكن، إلى أكثر من مقياس أداء واحد. للممارسين والقراء المهتمين على حد سواء، الرسالة واضحة: عندما يتعلق الأمر بتقييم نماذج التعلم الآلي، طريقة تقطيع البيانات يمكن أن تهم تقريبًا بقدر أهمية النموذج نفسه.
الاستشهاد: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
الكلمات المفتاحية: التحقق المتقاطع k-fold, مقايضة الانحياز والتباين, تقييم النموذج, تحقق صحة التعلم الآلي, التصنيف الموجّه