Clear Sky Science · ar
نظام تعيين الخبراء قائم على معالجة اللغة الطبيعية لبرامج ماري سكودوفسكا-كوري
لماذا يهم اختيار الخبير المناسب فعلاً
عندما تتنافس آلاف المقترحات البحثية على تمويل محدود، يتوقف كل شيء على من يقوم بتقييمها. إذا لم يفهم الخبراء المعينون موضوع المقترح فعلياً، فقد تُساء فهم الأفكار الواعدة أو تُتغاضى عنها. تستعرض هذه المقالة كيف يمكن للذكاء الاصطناعي، وخصوصاً أنظمة معالجة اللغة الحديثة، أن يساعد في مطابقة المقترحات مع أفضل الخبراء الممكنين بدقة وعدالة أكثر من أدوات القوائم المعتمدة على الكلمات المفتاحية الحالية.
مشكلة قوائم الكلمات المفتاحية
حتى الآن، اعتمد تعيين الخبراء في برامج التمويل الأوروبية الكبرى مثل منح ما بعد الدكتوراه في ماري سكودوفسكا-كوري بشكل كبير على الكلمات المفتاحية. يقوم النظام الحالي بمسح أوصاف المقترحات وملفات المراجعين للعثور على المصطلحات المطابقة، ثم يقترح ثلاثة خبراء بالإضافة إلى بدائل. لكن النواب الرئيسيين — العلماء الكبار المسؤولين عن الإشراف على العملية — يغيرون حوالي 40% من هذه التعيينات. هذا المستوى من التصحيح اليدوي يجعل النظام مجهدًا للعمالة وبطيئًا وغامضًا إلى حد ما، خاصة مع وصول ما يصل إلى 10,000 مقترح سنوياً، غالبًا في مجالات ناشئة تؤدي فيها قوائم الكلمات الثابتة أداءً ضعيفًا.
قراءة البحث كإنسان، وبمقياس واسع
طور المؤلفون نظام تعيين جديد يحاول "قراءة" البحث كما يفعل الخبير البشري. بدلاً من الاعتماد على تصنيفات، يجمع النظام منشورات كل خبير عبر ORCID، وهو نظام معرف عالمي للباحثين، ويبني قاعدة بيانات تضم أكثر من 2800 ملخص للمقالات. تُعالَج كل من مستخلصات المقترحات ومستخلصات المنشورات بواسطة GALACTICA، وهو نموذج لغوي كبير تدرب خصيصًا على النصوص العلمية. يحول GALACTICA كل ملخص إلى بصمة رقمية تلتقط معناه، وليس مجرد عباراته. بمقارنة هذه البصمات، يمكن للنظام تقدير مدى توافق محتوى المقترح مع أعمال كل خبير السابقة.
ثلاث طرق لحساب الخبرة
تتمثل إحدى التحديات في أن لدى الخبراء عشرات المنشورات. يحتاج النظام إلى درجة واحدة لكل خبير ومقترح، لذا اختبر المؤلفون ثلاث طرق بسيطة لدمج التشابهات. استراتيجية المجموع تضيف كل درجات التشابه، مُكافِئةً الاتساع والتكرار في الصلة. استراتيجية الضرب تضاعفها، معطيةً أهمية للتشابه المستمر عبر العديد من المنشورات لكنها تعاقب بشدة أي تطابق ضعيف. استراتيجية القيمة العظمى تحتفظ بأقوى تطابق فردي فقط، بافتراض أن ورقة واحدة ذات صلة وثيقة قد تكفي لتبرير التعيين. تُستخدم هذه الدرجات لترتيب 48 خبيرًا مرشحًا لكل من 181 مقترحًا، وتُقارن الترتيبات مع اختيارات الخبراء النهائية التي أجرَها النواب الرئيسيون.
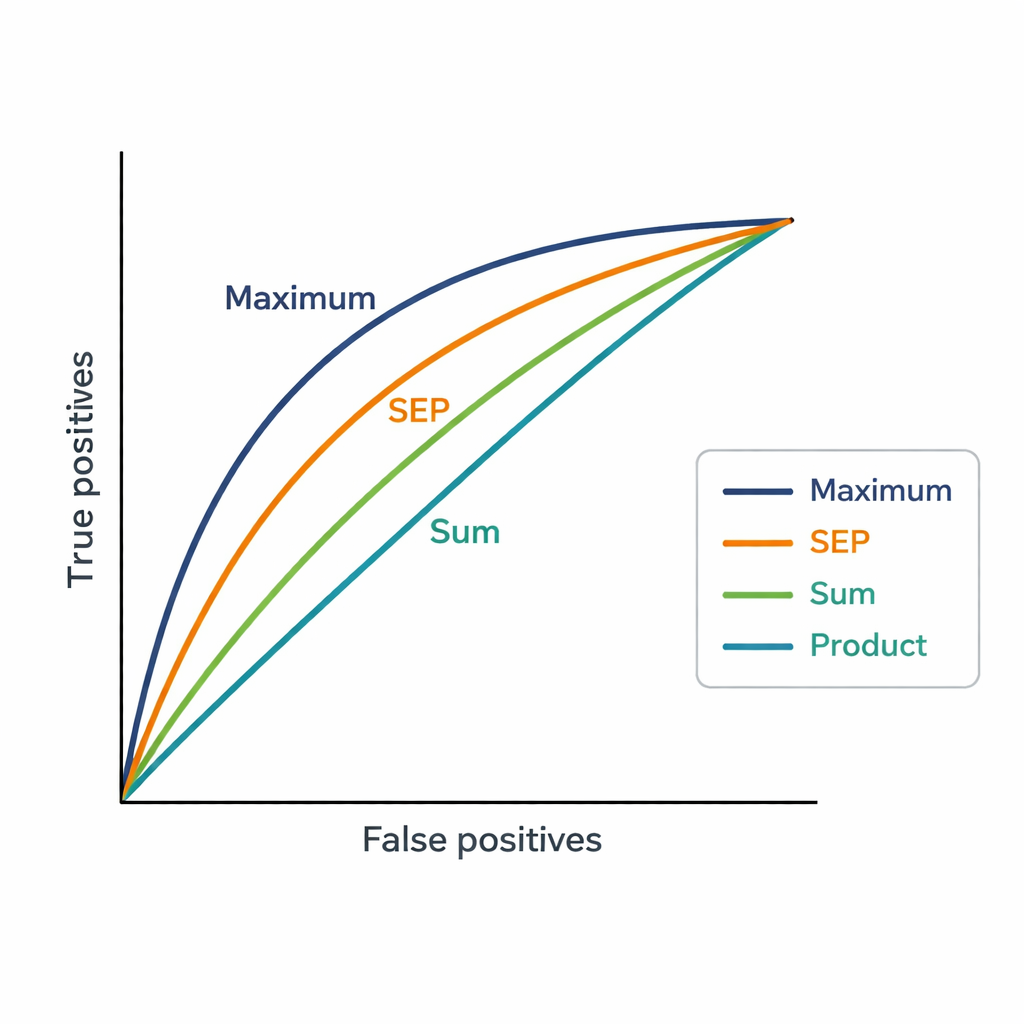
ما تكشفه الأرقام عن اختيارات البشر
طابِقَت استراتيجية القيمة العظمى قرارات النواب الرئيسيين بأكبر قدر، محققةً مساحة تحت منحنى (AUC) تبلغ 0.82، أفضل من النظام الحالي القائم على الكلمات المفتاحية (AUC 0.75) ومن طرق التجميع الأخرى. في الواقع، كان الخبير الذي يختاره النواب عادةً يظهر ضمن أفضل أربعة اقتراحات التي ولَّدتها استراتيجية القيمة العظمى. يشير هذا إلى أنه عند تعيين المراجعين، يركّز الناس غالبًا على ما إذا كان هناك على الأقل رابط قوي واحد بين أعمال الخبير السابقة والمقترح، بدلاً من المطالبة بأن تتوافق كل منشورات الخبير. كما تولد الطريقة الجديدة درجات أكثر تفصيلاً بكثير من مستويات "الألفة" الخشنة في المنصة، مما يسمح بتمييز أوضح بين الخبراء ذوي الترتيب المتقارب.
ماذا يعني هذا لمراجعات المنح المستقبلية
بالنسبة للقارئ العادي، الخلاصة واضحة: باستخدام ذكاء اصطناعي يفهم اللغة العلمية، يمكن لوكالات التمويل مطابقة المقترحات مع الخبراء المناسبين بشكل أفضل، وتقليل التصحيحات اليدوية، وجعل العملية أكثر اتساقًا وشفافية. بينما تُبرز أساليب مختلفة لدمج الأدلة من المنشورات جوانب مختلفة من الخبرة، يبدو أن قاعدة "أفضل تطابق فردي" البسيطة تعكس إلى حد كبير كيفية اتخاذ البشر للقرار فعليًا. ومع اختبار هذه الأنظمة على نطاق أوسع ومع نماذج لغوية أحدث، قد تصبح جزءًا أساسيًا من تقييم البحث الأعدل والأكفأ على مستوى العالم.
الاستشهاد: Álvarez-García, E., García-Costa, D., De Waele, I. et al. Expert assignment system based on natural language processing for Marie Sklodowska-Curie actions. Sci Rep 16, 6396 (2026). https://doi.org/10.1038/s41598-026-37115-8
الكلمات المفتاحية: مراجعة الأقران, مطابقة الخبراء, تمويل البحث, معالجة اللغة الطبيعية, نماذج لغوية كبيرة