Clear Sky Science · ar
تلخيص زمني مبتكر لتصنيف الفيديوهات المعقدة
لماذا تهم ملخّصات الفيديو الأذكى
من كاميرات المراقبة إلى منصّات البث، يسجل العالم المزيد من الفيديوهات أكثر مما يستطيع البشر أو الحواسيب معالجته بسهولة. كل ثانية من اللقطات تحتوي على عشرات الإطارات، ومع ذلك فإن العديد من هذه الإطارات متشابهة إلى حد كبير. تستكشف هذه الورقة طريقة لتقليص الفيديوهات الطويلة إلى اللحظات الأكثر دلالة، بحيث تظل الحواسيب قادرة على تمييز أفعال مثل الطهي أو ممارسة الرياضة أو المشي مع كلب—مع استخدام وقت وذاكرة وطاقة أقل بكثير. يمكن لمثل هذه التقدّمات أن تساعد في إتاحة تحليلات فيديو قوية للأجهزة اليومية، من الروبوتات المنزلية إلى الكاميرات القابلة للارتداء.

من الإطارات التي لا تنتهي إلى اللحظات الرئيسة
تحاول أنظمة تصنيف الفيديو التقليدية التعرف على ما يحدث في مقطع—مثل تقطيع الخضروات أو رمي كرة السلة—عن طريق إدخال تسلسلات طويلة من الإطارات إلى نماذج تعلم عميق ثقيلة. تحتاج هذه النماذج إلى التعامل مع كل من المظهر (كيف تبدو الأشياء) والتوقيت (كيف تتحرك عبر الزمن). يؤدي معالجة كل الإطارات إلى مجموعات بيانات ضخمة، ومتطلبات تخزين عالية، وحسابات بطيئة تستهلك طاقة كبيرة. يجادل المؤلفون بأن العديد من هذه الإطارات زائدة عن الحاجة: إذا لم يتغير شيء كبير من إطار لآخر، فإن النظام لا يكسب الكثير من تحليل كلاهما. الفكرة المركزية في الورقة هي انتقاء مجموعة أصغر بكثير من “الإطارات الرئيسية” التي تظل تلتقط التغيّرات المهمة في المشهد.
قياس التغيّر بين الإطارات
للعثور على تلك اللحظات الرئيسية، يصمّم الباحثون ويقارنون عدة طرق لقياس مدى اختلاف إطار عن آخر. بدلاً من الاعتماد فقط على مسافة إقليدية تقارن جميع البكسلات بصورة متساوية، يجربون بدائل أكثر حساسية للتغيّرات البنيوية. الاقتراح الرئيسي لهم، المسمى «معيار مجموع طول الصفوف» (Norm of Rows)، يركز على أكبر فرق عبر كل صف من البكسلات ثم يأخذ الصفّ الأبرز كمقياس للتغيّر بين إطارين. كما يستكشفون مسافات مبنية على الأعمدة وطرق تعتمد على القيم الذاتية لمصفوفات تُلخّص كيف تتوزّع فروق البكسلات. تهدف كل هذه المقاربات إلى اكتشاف الحركة أو التغيّرات المشهدية ذات الدلالة بشكل أفضل، مثل امتداد يد نحو أداة مطبخ أو قفز لاعب.
كيف يعمل خط أنابيب التلخيص
تبدأ عملية التلخيص بالإطار الأول من الفيديو، الذي يُعامل كإطار رئيسي مبدئي. يقارن النظام بعد ذلك هذا الإطار الرئيسي مع كل إطار لاحق باستخدام أحد مقاييس المسافة. كلما ارتفعت المسافة فوق عتبة محددة، يُعلّم الإطار المقابل كإطار رئيسي جديد، مشيراً إلى أن شيئاً بصرياً هاماً قد تغيّر. ثم تتكرر العملية باستخدام هذا الإطار الرئيسي الجديد كمرجعية، تمشي عبر الفيديو وتجمع سلسلة من اللقطات التمثيلية. عبر ضبط العتبة، يمكن للطريقة الاحتفاظ بما يصل إلى 20 بالمئة فقط أو إلى 80 بالمئة من الإطارات الأصلية، ما يوازن بين الضغط والتفاصيل. تُمرَّر هذه التسلسلات المُلخّصة بعد ذلك إلى مصنّف تعلم عميق قياسي يجمع شبكة صور قوية (ResNet-50) مع وحدة حسّاسة للتوقيت مثل LSTM.
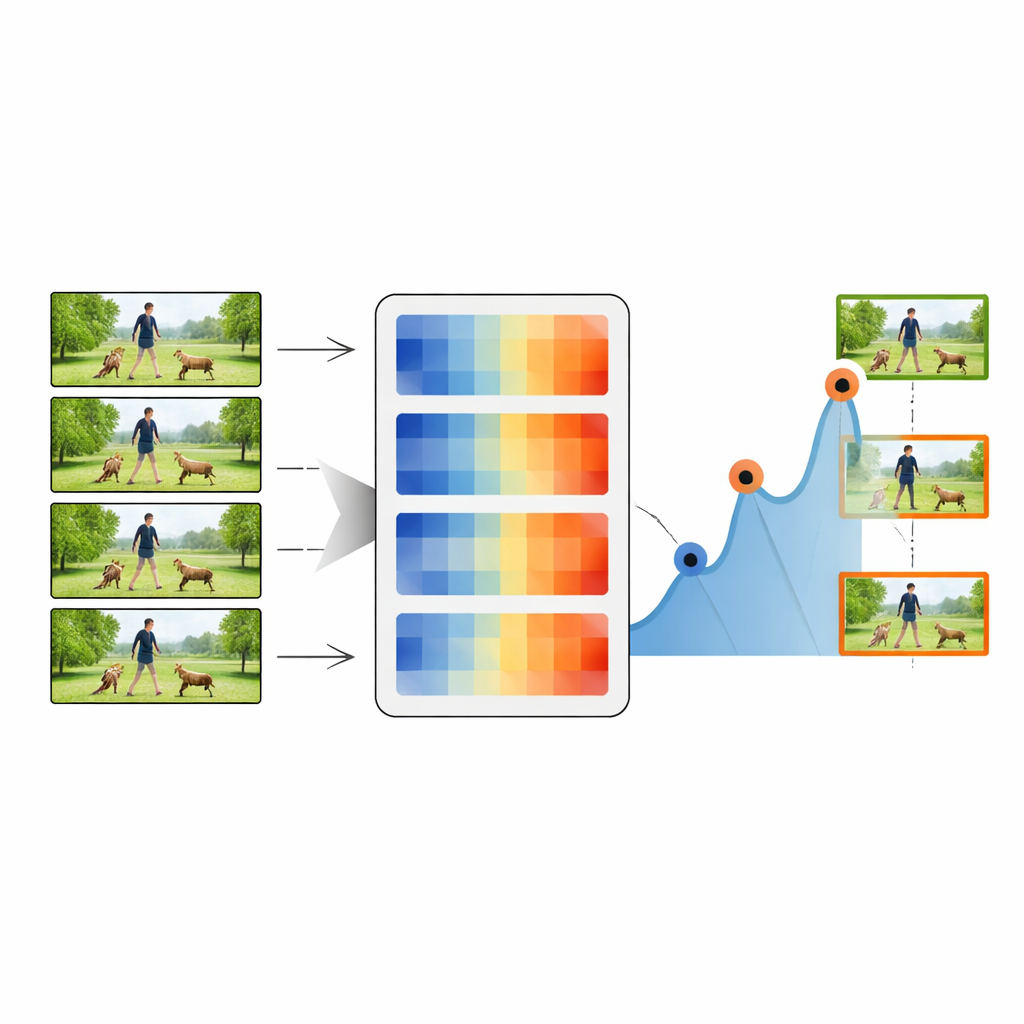
وضع الطريقة على محك الاختبار
يقيم المؤلفون منهجهم بدقة على أربع مجموعات فيديو معروفة: أنشطة مطبخ يومية (MMAC)، والرياضات والأفعال العامة (UCF101 وUCF11)، ومقاطع أكثر تنوعاً وتحدياً (HMDB51). عبر هذه المعايير، يقدّم مقياس مجموع طول الصفوف توازناً ثابتاً بين السرعة والدقة. مع الاحتفاظ بنحو نصف الإطارات فقط، يصل نظامهم إلى دقّات تصنيف تتجاوز 90 بالمئة على عدة مجموعات بيانات—غالباً ما يضاهي أو يتفوق على طرق أكثر تعقيداً تستخدم الفيديوهات كاملة غير المُخلّصة. كما يقيسون مدى تغطية الملخّصات للمحتوى الأصلي، وكمية التكرار في الإطارات المختارة، ومدى تنوّع اللحظات الملتقطة. يحقق المقياس المقترح تغطية عالية مع تكرار منخفض، ما يعني أنه يحافظ على سرد الفيديو دون تكرار إطارات مشابهة.
قرارات أسرع للفيديو الواقعي
عن طريق تقليل عدد الإطارات تقريباً إلى النصف، تكاد الطريقة تقلص زمن المعالجة إلى النصف على أجهزة الحاسوب القياسية ولا تزال توفر تسريعات ملحوظة حتى على بطاقات الرسوميات الحديثة. للأنظمة الواقعية التي يجب أن تتصرف في الزمن الحقيقي—مثل المراقبة، والروبوتات الذاتية، أو التطبيقات المحمولة—يعد خفض عبء العمل هذا أمراً حاسماً. تُظهر الدراسة أن مقياس مسافة مصمَّماً بعناية يمكن أن يعمل كحارس ذكي، يختار الإطارات التي تستحق الانتباه وتسمح بتخطي ما يمكن تجاهله بأمان.
خلاصة للاستخدام اليومي
بعبارات بسيطة، تُبيّن هذه الدراسة أن الحواسيب لا تحتاج إلى مشاهدة كل إطار لفهم ما يحدث في فيديو. من خلال التركيز على اللحظات التي يتغير فيها المشهد فعلاً وتجاهل النسخ الشبه متطابقة، تحتفظ التقنية المقترحة بجوهر الفعل مع تقليص كمية البيانات. يجعل هذا الفهم عالي الجودة للفيديو أكثر عملية على عتاد محدود ويفتح الباب لأدوات أسرع وأكثر كفاءة لتحليل الطوفان المتزايد من المعلومات البصرية في حياتنا اليومية.
الاستشهاد: Khan, A., Rahnama, A., Islam, A. et al. Innovative temporal summarization for complex video classification. Sci Rep 16, 7970 (2026). https://doi.org/10.1038/s41598-026-37111-y
الكلمات المفتاحية: تصنيف الفيديو, تلخيص الفيديو, اختيار الإطارات الرئيسية, التعرّف على الأفعال, كفاءة رؤية الحاسوب