Clear Sky Science · ar
اختيار ميزات بسيط، سريع وفعال موجه بتجميع ضبابي تكيفي لبيانات الميكروأرايه البيوانفورماتية ثنائية التصنيف عالية البُعد وغير المتوازنة بشدة
لماذا هذا مهم لأبحاث الجينات
يمكن لاختبارات التعبير الجيني الحديثة قياس عشرات الآلاف من الجينات في عينة مريض واحدة. هذا الكم الهائل من البيانات يوعد بتشخيص مبكر للسرطان وخيارات علاجية أفضل، لكنه يخلق أيضًا مشكلة: معظم هذه الجينات صاخبة أو مكررة أو مرتبطة أساسًا بالحالات الشائعة لا النادرة والخطيرة منها. تقدم هذه الورقة طريقة جديدة لتصفية مجموعات بيانات التعبير الجيني الضخمة بحيث تتمكن الحواسيب من اكتشاف المرضى المنتمين إلى مجموعة أقلية صغيرة يصعب الكشف عنها باستخدام مجموعة صغيرة ومختارة بعناية من الجينات.
تحدي وجود جينات كثيرة ومتشابهة جدًا
تتبع تجارب الميكروأرايه غالبًا آلاف مستويات نشاط الجينات لعدد محدود من المرضى فقط. عادةً، يفوق أحد التصنيفين (مثل نوع فرعي شائع من السرطان) الآخر بفارق كبير، ما يخلق بيانات شديدة عدم التوازن. في هذا الإطار، يتصرف الكثير من الجينات بطرق متشابهة جدًا، وقد تتداخل أنماط الحالات الأساسية والأقلية. تميل طرق التعلم القياسية إلى التركز على صنف الغالبية وتشتت بسبب الجينات المكررة، ما يؤدي إلى فرط التكيّف وضعف كشف الأنواع الفرعية النادرة. كما أن طرق خفض البُعد التقليدية إما تفقد القابلية للفهم عبر بناء ميزات مختلطة جديدة، أو تختار جينات دون فحص دقيق لمدى مساعدتها للمصنف في التعرف على حالات الأقلية.
خارطة طريق جديدة لاختيار جينات أذكى
يقدم المؤلفون AFCG‑SFE، نموذج اختيار ميزات تكيفي صُمم خصيصًا لبيانات التعبير الجيني عالية البُعد وغير المتوازنة. تبدأ الطريقة من بحث بسيط "بوكيلَة واحدة" يفعّل أو يوقف الجينات ويختبر مدى دعمها للتصنيف، ثم تغني ذلك بعدة خطوات مستندة إلى البيانات. أولًا، تجمّع الجينات بناءً على مدى تشابه سلوكها، ثم تسمح بانتماء الجينات لأكثر من مجموعة لتعكس الواقع البيولوجي الذي قد يشارك فيه الجين في مسارات متعددة. داخل كل مجموعة، تُصنَّف الجينات حسب مدى المعلومات التي تقدمها عن وسم المرض وتُحتفظ فقط ببعض الممثلين الرئيسيين، مما يقلص التكرار بشكل حاد قبل أن يبدأ البحث الرئيسي حتى. 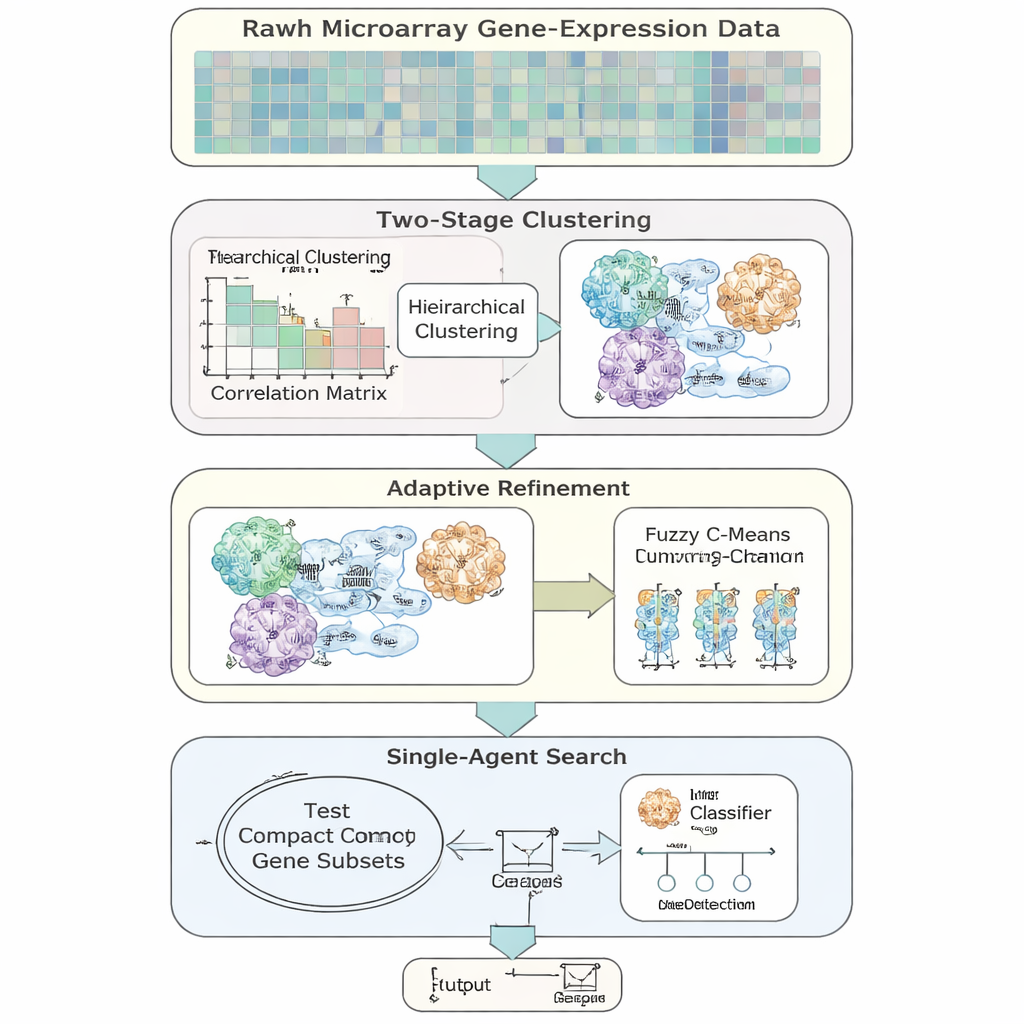
جعل الحاسوب يولي اهتمامًا للمرضى النادرين
بدلاً من التركيز على الدقة البسيطة، يستخدم AFCG‑SFE درجة ملاءمة تُعطي وزنًا لمقاييس مناسبة للبيانات المنحرفة، بما في ذلك التوازن بين التعرف الصحيح على حالات الأقلية والغالبية والأداء عبر جميع عتبات القرار. تتضمن دالة الملاءمة أيضًا عقوبات لاختيار عدد كبير جدًا من الجينات أو العديد من الجينات من نفس العنقود، ومكافأة للجينات التي تحمل تبعية قوية مع وسم المرض. والأهم أن قوة هذه العقوبات والمكافآت تُضبط تلقائيًا من خصائص مجموعة البيانات—مثل عدد الجينات لكل مريض ومدى تداخل التصنيفين—بدلاً من ضبط يدوي. هذا يجعل الطريقة أكثر متانة وأسهل في النقل بين الدراسات.
التكيف مع صعوبة المشكلة
فكرة أساسية هي أن الخوارزمية لا ينبغي أن تهدف دائمًا إلى أصغر مجموعة جينات ممكنة. عندما يكون فصل التصنيفين صعبًا جدًا أو متداخلًا بشدة، ترفع الطريقة تلقائيًا حدًا أدنى لعدد الجينات التي يجب الاحتفاظ بها، لضمان عدم التخلص من إشارات نادرة لكنها مهمة. ومع تقدم البحث، يضيق AFCG‑SFE تدريجيًا حدًا لكل عنقود على عدد الجينات التي يمكن أن تنجو من كل مجموعة، مع احترام هذا الحد الأدنى. النتيجة هي لوحة جينات مدمجة ومتنوعة تلتقط بنية البيانات دون أن تهيمن عليها نمط مكرر واحد. 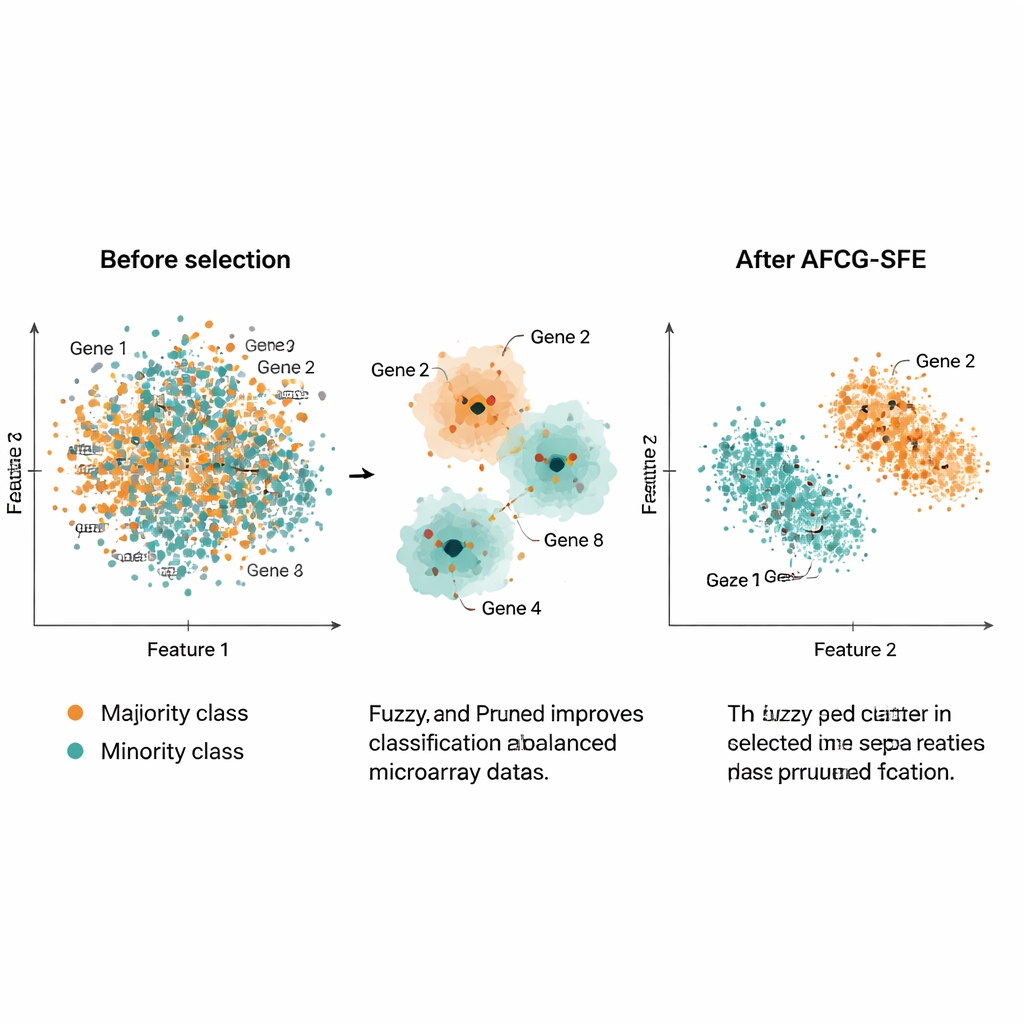
ماذا أظهرت التجارب
اختبر المؤلفون AFCG‑SFE على 20 مجموعة بيانات ميكروأرايه سرطانية عامة، كل منها تحتوي على آلاف الجينات لكن حوالي 100–200 عينة فقط وبانحياز تصنيفي قوي. قارنوا طريقتهم بعدة قواعد بحث تطورية، ومرشحات بسيطة، ونهج مدمجة تدمج اختيار الميزات داخل المصنف. عبر مجموعة من المقاييس—بما في ذلك مقياس F، والدقة المتوازنة، والمساحة تحت منحنى ROC، ومقياس فرط التكيّف—كان AFCG‑SFE الأفضل أو متساويًا مع الأفضل على جميع مجموعات البيانات. عادة كان يختار أقل من 25 جينًا (غالبًا 6–8)، مقلصًا أكثر من 99% من الميزات الأصلية مع الحفاظ على أو تحسين أداء التصنيف. كما خفّض مؤشر التعقيد الذي يلتقط مقدار تداخل التصنيفين في فضاء الميزات، مشيرًا إلى فصل أوضح بعد الاختيار.
الخلاصة لغير المتخصصين
عمليًا، تقدم هذه الدراسة طريقة لتقليص ملفات التعبير الجيني الهائلة والمشحونة بالضوضاء إلى مجموعات صغيرة جدًا من الجينات الإعلامية التي تتيح للحواسيب التعرف بدقة على مجموعات المرضى النادرة. من خلال تجميع الجينات المشابهة بذكاء، ومكافأة تلك التي تتتبع المرض فعليًا، والحماية الصريحة من الانحياز لصنف الغالبية، يوفر AFCG‑SFE كلًا من تنبؤ أفضل ولوحات جينية أبسط بكثير. يمكن لهذا المزيج أن يساعد الباحثين على التركيز على مؤشرات حيوية محتملة، وتصميم اختبارات تشخيصية أكثر قابلية للتفسير، وفي النهاية تحسين كيفية عمل أدوات الطب الدقيق مع بيانات بيولوجية حقيقية وغير مثالية.
الاستشهاد: Tye, Y.W., Chew, X., Yusof, U.K. et al. Adaptive fuzzy cluster-guided simple, fast, and efficient feature selection for high-dimensional and highly imbalanced binary-class bioinformatics microarray data. Sci Rep 16, 6650 (2026). https://doi.org/10.1038/s41598-026-37086-w
الكلمات المفتاحية: تعبير الجينات, اختيار الميزات, البيانات غير المتوازنة, الميكروأرايه, أنواع السرطان الفرعية