Clear Sky Science · ar
نموذج لغوي كبير مرتكز على المعرفة لتوليد خطط تدريب رياضي مخصصة
خطط تمرين أذكى للناس العاديين
تعد معظم تطبيقات اللياقة بتقديم تدريب مخصص، لكن العديد منها لا يزال يعتمد على قوالب عامة تتجاهل الحالة الفعلية لجسمك. يقدم هذا البحث LLM-SPTRec، نظامًا جديدًا يستخدم نفس نوع النماذج اللغوية الكبيرة التي تقف وراء برامج الدردشة الحديثة، مع معرفة موثقة في علوم الرياضة وبيانات الأجهزة القابلة للارتداء، لبناء خطط تمرين أكثر أمانًا وفعالية. لأي شخص تساءل لماذا يستمر تطبيقه في اقتراح التمارين الخاطئة — أو قلق ما إذا كانت نصائح الصحة المنتجة بواسطة الذكاء الاصطناعي آمنة فعلاً — يوضح هذا العمل كيف يمكن جعل التدريب الرقمي أكثر تخصيصًا وعلمية.
لماذا تفشل تطبيقات اللياقة التقليدية
محركات التوصية التقليدية، مثل تلك التي تقترح أفلامًا أو منتجات، تواجه صعوبة عندما تُطبّق على التمارين. غالبًا ما تكرّر وتعيد استخدام قوالب قياسية، وتواجه صعوبة في التعامل مع بيانات محدودة للمستخدمين الجدد، ونادرًا ما تنظر إلى كيفية تغيّر جسمك من يوم لآخر. والأسوأ أنها غير مصممة لقرارات عالية المخاطر التي تكون فيها السلامة مهمة. النماذج اللغوية العامة جيدة في الحديث عن التمارين، لكن لأنها مدرَّبة على نصوص واسعة من الإنترنت، قد تُنتج "هلوسات" ونصائح محفوفة بالمخاطر أو تتجاهل أيام الراحة المهمة. يجادل المؤلفون أنه بالنسبة لتخطيط التمرين — حيث يمكن أن يسبب الإرشاد السيئ إصابة أو فرط تدريب — يجب أن يكون الذكاء الاصطناعي مؤسَّسًا على علوم رياضية مُتحقَّق منها ويجب أن يتتبّع حالة الشخص المتغيرة مع الزمن.
بناء صورة غنية عن الفرد
في جوهر LLM-SPTRec توجد وحدة تنشئ لقطة مفصّلة لكل مستخدم. بدلاً من تخزين العمر أو الجنس أو مستوى الخبرة فقط، يجمع النظام بين ثلاثة أنواع من المعلومات: السمات الثابتة (مثل تاريخ التدريب)، الإشارات الديناميكية (مثل معدل ضربات القلب، تباين معدل ضربات القلب، درجة النوم، والتمارين السابقة من الأجهزة والسجلات)، والأهداف المكتوبة بنص حر من المستخدم. نموذج قائم على المحول — مرتبط بتقنية النماذج اللغوية الحديثة — يتعلم أنماطًا في هذه البيانات الزمنية، مثل كيف يؤثر تمرين شاق بالأمس على الاستعداد اليوم. بعد ذلك، يوزن آلية الانتباه أي الإشارات هي الأهم في لحظة معينة، ويجمعها في تمثيل رقمي واحد لحالة المستخدم الحالية.
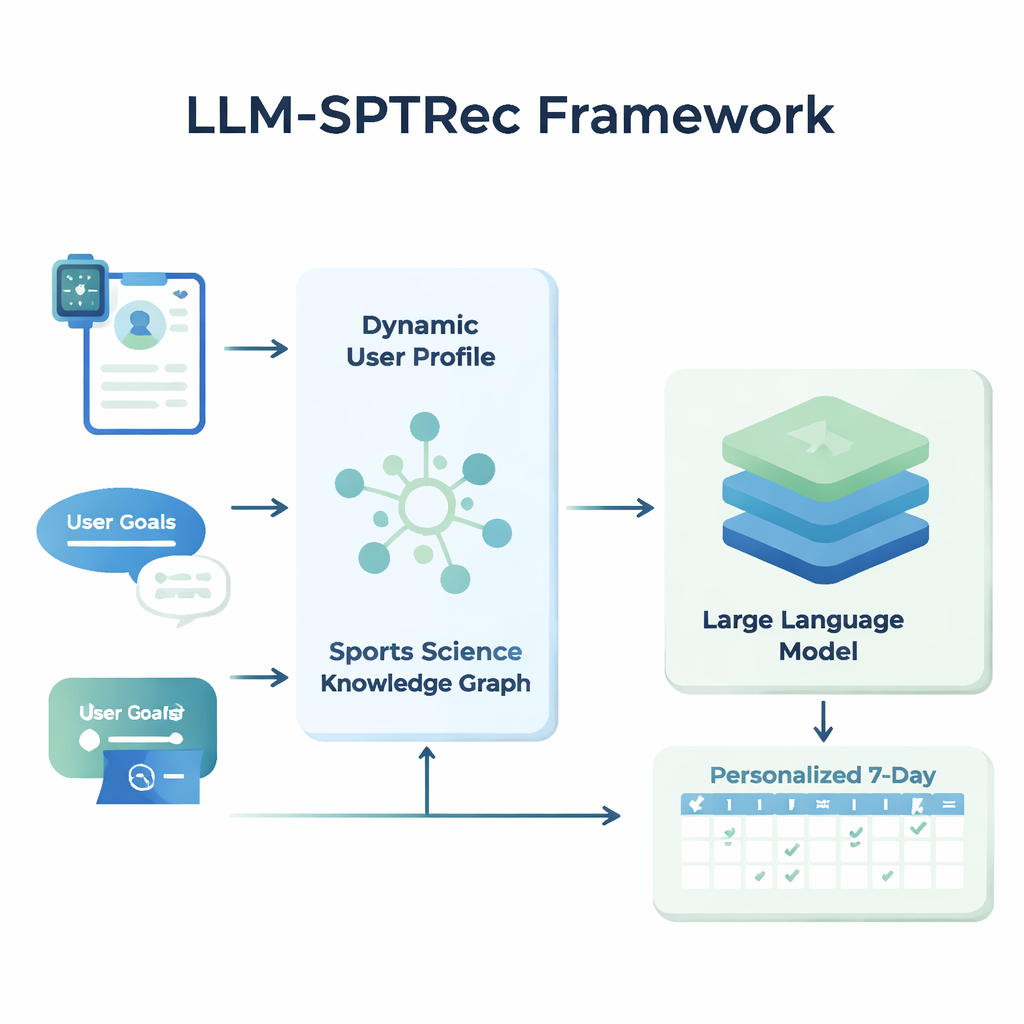
تعليم الذكاء الاصطناعي علوم رياضية حقيقية
لمنع التوصيات غير الآمنة أو غير العلمية، بنى الباحثون رسمًا معرفيًّا لعلوم الرياضة، وهو في الأساس خريطة منظمة لحقائق موافق عليها من خبراء. تشمل آلاف الإدخالات التي تربط التمارين بالعضلات وأنواع الحركة والمعدات والإصابات الشائعة ومبادئ التدريب مثل التحميل التصاعدي والتخصيص. لكل مستخدم، يستخرج النظام الأجزاء الأكثر صلة من هذا الرسم — مثل العضلات المستهدفة بتمرين الضغط وأي الحركات ضارة لمشاكل الكتف — ويحوّلها إلى نص مقروء يُغذَّى إلى النموذج اللغوي جنبًا إلى جنب مع ملف تعريف المستخدم. ثم يُطلب من النموذج اللغوي، عبر موجه مصمم بعناية، توليد خطة تدريب متعددة الأيام بصيغة منظمة، مع الالتزام بقواعد مثل تدوير مجموعات العضلات بين الأيام وتجنب موانع الاستعمال المعروفة.
المحافظة على بنية الخطط وسلامتها وتحسينها مع الوقت
لا يقتصر LLM-SPTRec على توليد النص فحسب. وحدة التحقق تفحص كل خطة مقابل قواعد صارمة، مثل عدم تحميل نفس مجموعات العضلات الأساسية في أيام متتالية، وتعلم التعارضات مع مخاطر الإصابات المخزنة في الرسم المعرفي. إذا فشلت الخطة في هذه الفحوصات، يعيد النظام استدعاء النموذج ويشير صراحة إلى الأخطاء حتى يتم إنتاج خطة آمنة. يتم تدريب النظام أيضًا على مرحلتين. أولًا يتعلم من مجموعة كبيرة من الخطط المصممة من قبل خبراء. ثم يُنقّح أكثر باستخدام تغذية راجعة، حيث تكافئ تصنيفات المستخدمين المحاكاة أو الحقيقية الخطط المتماسكة والمتوافقة مع الأهداف والمُرضية في الاتباع، بينما تُعاقب بشدة الاقتراحات غير الآمنة. هذا الحلقة المغلقة توجّه النموذج نحو توصيات تعمل بشكل أفضل على أرض الواقع.
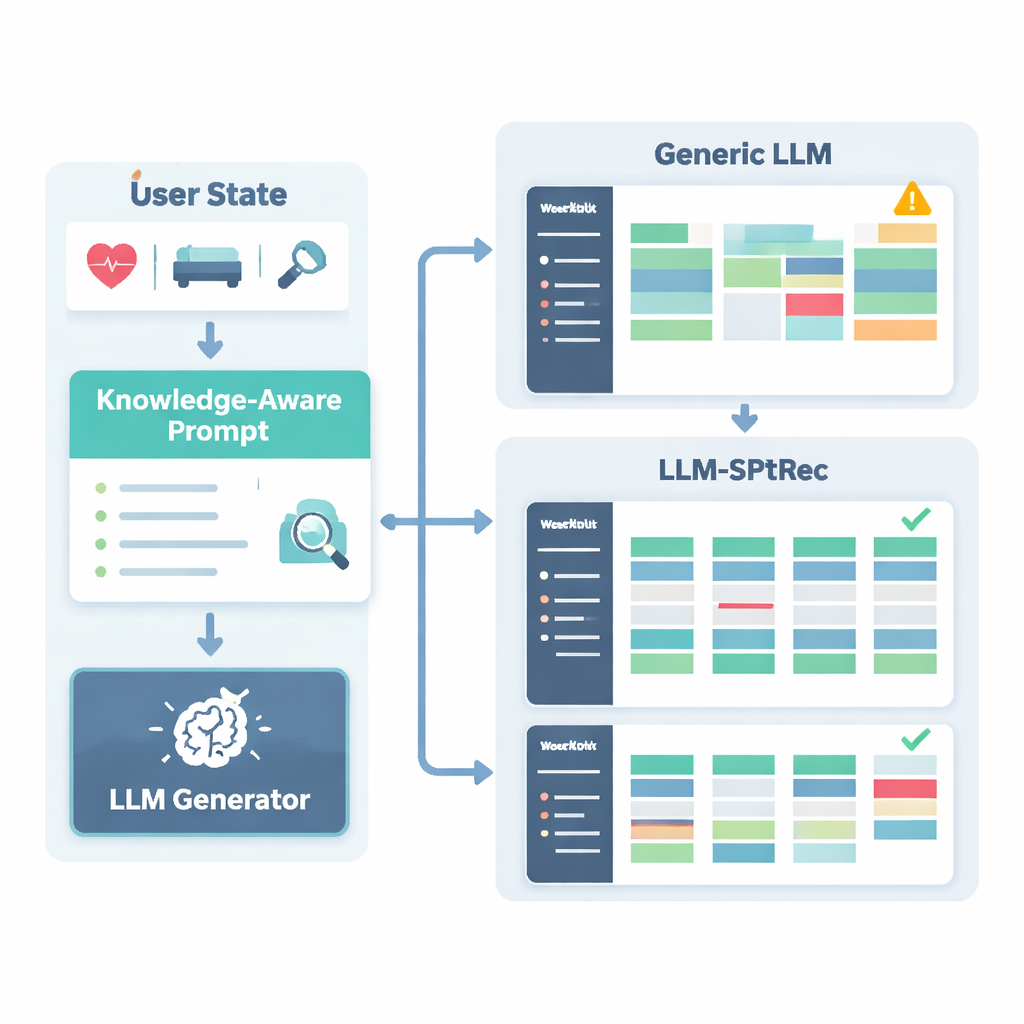
مدى أداء النظام في الممارسة
اختبر المؤلفون LLM-SPTRec على مجموعة بيانات عالمية كبيرة تُسمى SportFit-1M، التي تجمع بيانات مُجهَّلة المصدر من تطبيقات اللياقة والأجهزة القابلة للارتداء، وتغطي عشرات الآلاف من المستخدمين وملايين سجلات التدريب والسجلات الفيزيولوجية. قضوا بنظامهم مع مقارنات قوية: فلترة تعاونية تقليدية، نموذج تسلسلي ينظر فقط إلى الاختيارات السابقة، موصٍّ متقدم قائم على الرسم المعرفي، وإطار عمل عام قائم على نماذج لغوية. تفوق LLM-SPTRec على جميعها ليس فقط في اختيار التمارين المناسبة، بل — والأهم — في إنتاج خطط كاملة قيّمها الخبراء على أنها أكثر تماسكًا وأكثر توافقًا مع أهداف المستخدم. كانت درجات الرضا المتوقعة للمستخدمين أعلى أيضًا، وأظهرت دراسة بشرية صغيرة مع مدرّبين معتمدين أن سلامته كانت أفضل بكثير من نموذج لغوي عام بلا تأصيل خاص بالرياضة.
ما يعنيه هذا للتدريب الرقمي المستقبلي
بالنسبة للقارئ العادي، الخلاصة هي أن التدريب الذكي والآمن بالذكاء الاصطناعي ممكن عندما تجتمع ثلاثة مكونات: بيانات غنية من أجهزتك، وعلوم رياضية خبيرية مُشفَّرة كمعرفة مُنظَّمة، ونماذج لغوية قوية تُوجَّه وتُفحَص بعناية. يبيّن LLM-SPTRec أن مثل هذا المزيج يمكنه توليد خطط تدريب تكيفية يومًا بيوم تحترم حالة جسمك المتغيرة وأهدافك الشخصية، مع تقليل مخاطر النصائح الضارة أو غير المنطقية. ونظرًا للمستقبل، يمكن أن يمتد نفس النهج إلى ما وراء التمارين ليشمل التغذية وإعادة التأهيل من الإصابات أو حتى الصحة النفسية، مبيّنًا مستقبلًا يكون فيه مساعدو الذكاء الاصطناعي أقل شبهًا ببرامج الدردشة العامة وأكثر شبهًا بمدرّبين رقميين معرفيين وواعين بالسلامة.
الاستشهاد: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
الكلمات المفتاحية: تدريب مخصص, الذكاء الاصطناعي في علوم الرياضة, توصية لياقة, بيانات الأجهزة القابلة للارتداء, رسم معرفي