Clear Sky Science · ar
تطوّر كشف الأجسام من الشبكات الالتفافية إلى المحولات ودمج متعدد الوسائط
تعليم الحواسيب رؤية الأشياء اليومية
في كل مرة يوسم فيها هاتفك أصدقاءك في صورة، أو ترصد سيارة راكباً على الرصيف، أو يبرز أداة طبية ورماً في فحص، تعمل تقنية قوية بهدوء في الخلفية: كشف الأجسام. تشرح هذه المقالة الاستعراضية كيف تطوّر كشف الأجسام بسرعة خلال العقد الماضي، من خدع معالجة الصور المبكرة إلى أنظمة اليوم القائمة على المحولات والأنظمة متعددة المستشعرات، ولماذا تهمّ هذه التطورات من أجل شوارع أكثر أماناً، وروبوتات أذكى، وتشخيصات طبية أدق.
من البيكسلات إلى الأشياء القابلة للتعرّف
كشف الأجسام هو مهمة العثور على عناصر محددة في الصور أو الفيديو ووضع تسميات لها—سيارات، درّاجون، حيوانات، هياكل طبية، والمزيد. تبدأ المقالة بتوضيح مدى استخدام هذه القدرة: في القيادة الذاتية، والمراقبة، وتصوير الأمراض، والروبوتات. اعتمدت الأنظمة المبكرة على قواعد مصممة يدوياً لاستخراج الأشكال والأنسجة، لكن النهج الحديثة تتعلم مباشرة من البيانات باستخدام التعلّم العميق. الآن يسود فئتان واسعتان: الشبكات العصبية الالتفافية (CNNs) التي تجيد اكتشاف الأنماط المحلية مثل الحواف والزوايا، والمحولات التي تتفوّق في فهم المشهد الأوسع والعلاقات بين الأشياء البعيدة. معاً، تحددان كيف «ترى» الآلات الحالية العالم.
كيف تعمل محركات الرؤية الكلاسيكية
لا تزال طرق الـCNN تشغّل العديد من التطبيقات الزمن الحقيقي. تفحص هذه الشبكات الصور بفلاتر صغيرة لبناء خرائط ميزات أكثر ثراءً، ثم تزود رؤوس الكشف بهذه الخرائط لرسم مربعات احتواء وتعيين تسميات. تشرح المراجعة استراتيجيتين رئيسيتين. الأنظمة ذات المرحلتين مثل Faster R-CNN تقترح أولاً مناطق محتملة للأجسام ثم تُنقّحها، ما يحقّق دقة عالية غالباً بتكلفة حسابية أكبر. الأنظمة من مرحلة واحدة مثل سلسلة YOLO تتخطى خطوة الاقتراح وتتنبأ بالمربعات والتسميات بتمريرة واحدة، فتضحي بقليل من الدقة مقابل السرعة. النسخ الحديثة من YOLOv5 وYOLOv8 خضعت لضبط كبير—أضيفت أهرامات ميزات أذكى للكائنات الصغيرة، وبُنيت كتل خفيفة للأجهزة الطرفية، وحُسّنت دوال الخسارة—للوصول إلى مئات الإطارات في الثانية مع البقاء تنافسية على مجموعات الاختبار الصعبة.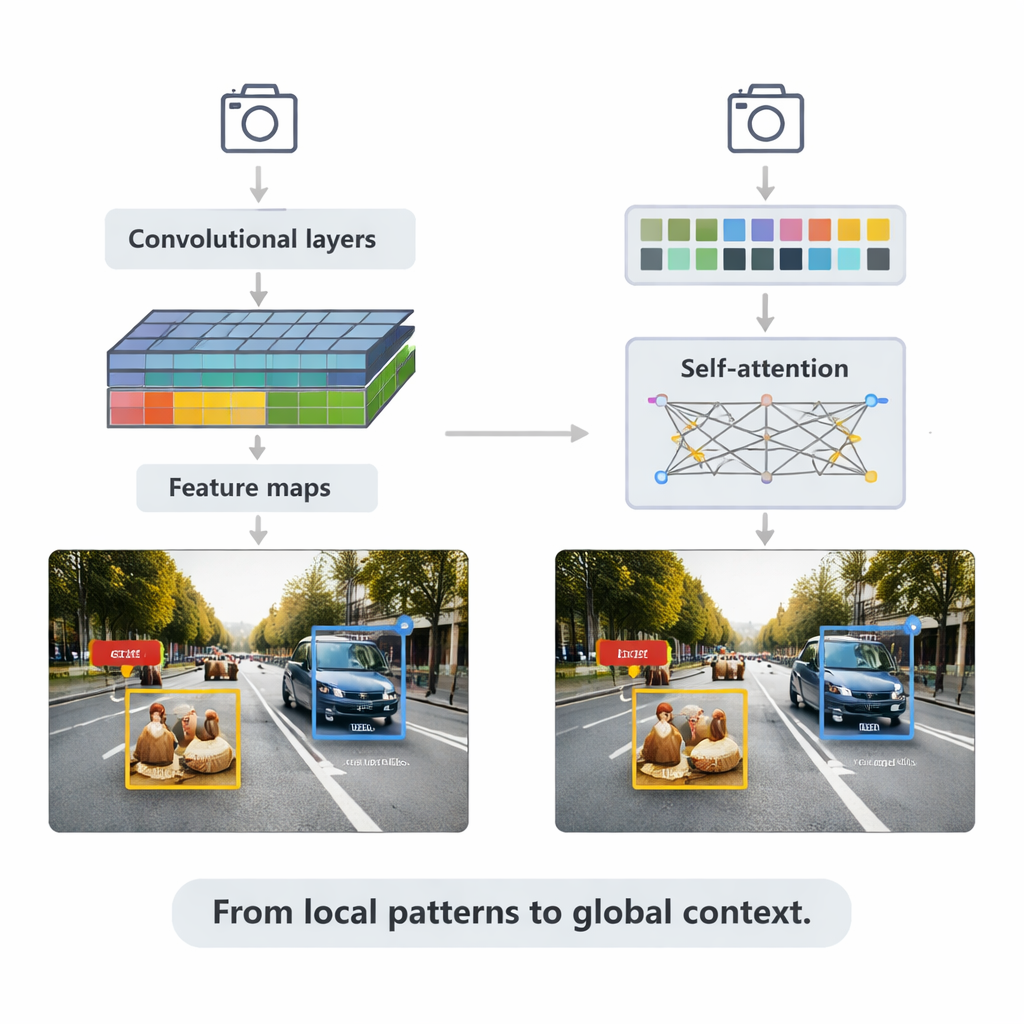
المحولات وقوّة السياق
تنتقل المقالة بعد ذلك إلى المحولات، وهي بنية أحدث مستعارة من نماذج اللغة. بدل التركيز على المناطق المحلية فقط، تستخدم المحولات «الانتباه الذاتي» لمقارنة كل رقعة في الصورة مع كل رقعة أخرى، متعلّمة أي المناطق هي الأكثر صلة بكل قرار. تُزيل نماذج مثل Detection Transformer (DETR) وخلفاؤها العديد من الحيل المصممة يدوياً، ساعية إلى خطوط أنابيب أبسط من النهاية إلى النهاية. تقلّل المتغيرات مثل Deformable DETR وRT-DETR من الحسابات وتحسّن سرعة التدريب، مما يسمح للمحولات بالعمل في الزمن الحقيقي مع تحقيق بعض أعلى درجات الدقة على معيار COCO الشائع. تتألّق هذه النماذج بشكل خاص في المشاهد المعقدة ذات الأجسام المتراكبة والخلفيات المشتّتة، حيث يساعد السياق العالمي في تمييز، مثلاً، راكباً يخفيه جزئياً جانب سيارة.
مزج الكاميرات والليدار واللغة
الظروف الواقعية—الضباب، والظلام، والوهج، والفوضى—غالباً ما تهزم أنظمة المستشعر الواحد. يركّز القسم الرئيسي من المراجعة على الدمج متعدد الوسائط: جمع بيانات من كاميرات عادية (RGB)، وحساسات عمق مثل LiDAR، وكاميرات حرارية، وحتى أوصاف نصية. يقدّم المؤلفون تصنيفاً واضحاً لكيفية حدوث هذا المزج: الدمج المبكر يخلط البيانات الخام في البداية، والدمج الوسيط يدمج الميزات المتعلّمة داخل الشبكة، والدمج المتأخر يجمع مخرجات كاشفات منفصلة في النهاية. تستخدم «محولات الدمج» الحديثة آليات الانتباه لمواءمة هذه التيارات، بحيث تعزّز قياسات المسافة الدقيقة من LiDAR والمظاهر الغنية من صور RGB والإشارات الدلالية من اللغة بعضها بعضاً. يعزّز هذا النهج الكشف في القيادة الذاتية، والتصوير الطبي، وفهم الفيديو، والمشاهد المكتظة بالنصوص.
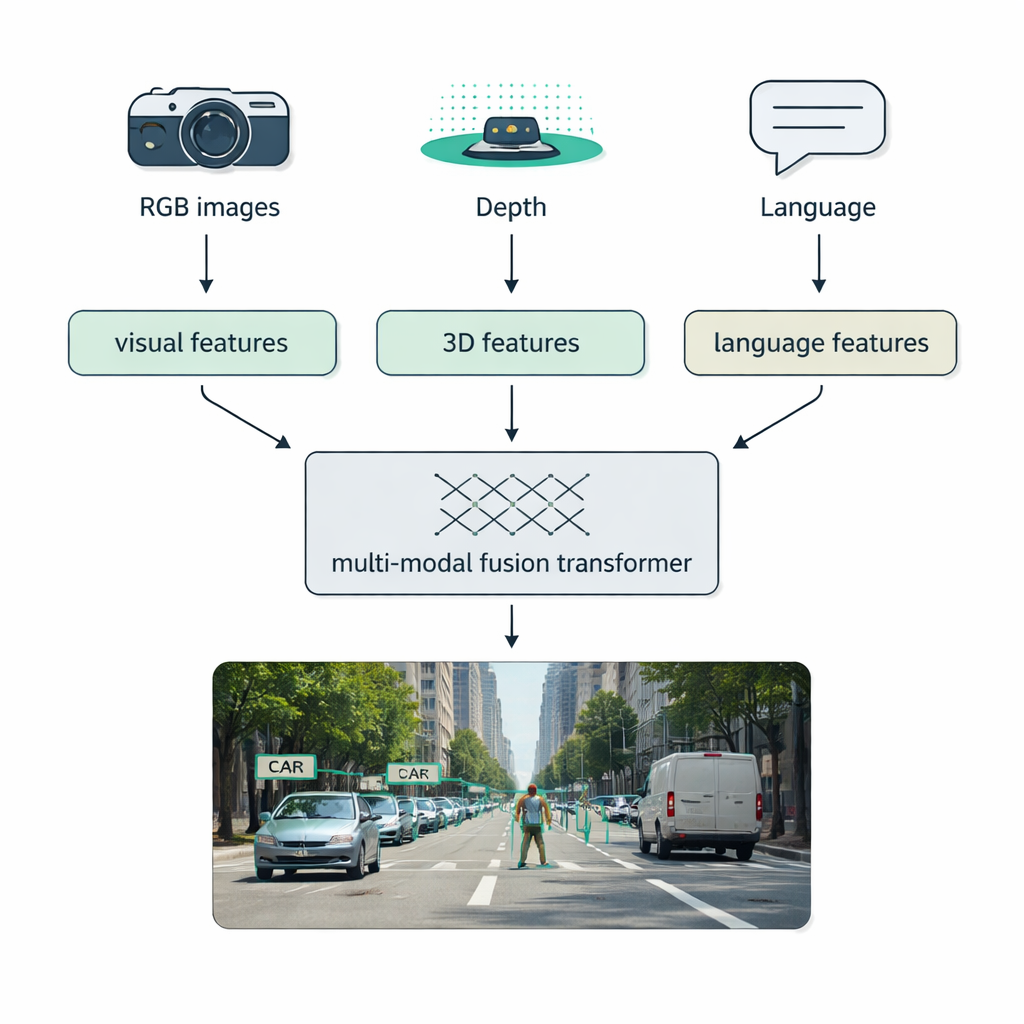
المقاييس والقيود وما القادم بعد ذلك
عبر الاختبارات القياسية مثل MS COCO، تقارن المراجعة كاشفات CNN والمحولات من حيث الدقة والسرعة معاً. تظل شبكات الـCNN الكلاسيكية ذات المرحلتين قوية لكنها أبطأ، وتسيطر نماذج نمط YOLO على الأجهزة الخفيفة، وتقود الأنظمة القائمة على المحولات الآن من ناحية الدقة مع تقليص الفجوة في السرعة. تحقق طرق الأشعة تحت الحمراء المتخصّصة درجات عالية جداً في ظروف الرؤية المنخفضة. ومع ذلك تبقى مشكلات صعبة: الأجسام الصغيرة جداً أو كبيرة جداً، والاعتراض الشديد، وتغيّر الطقس والإضاءة، والحاجة للعمل بموثوقية على أجهزة صغيرة للغاية. بالنظر إلى المستقبل، يبرز المؤلفون اتجاهات نحو نماذج إدراك موحّدة تتعامل مع الكشف والتقسيم والتوصيف معاً، و"نماذج أساس" تدمج الرؤية واللغة للتعرّف على أشياء موصوفة نصياً حتى لو لم تُوسم في بيانات التدريب.
لماذا يهمّ هذا في الحياة اليومية
بالنسبة لغير المتخصصين، الفكرة الأساسية هي أن كشف الأجسام ينتقل من أنظمة ضيقة ومُعدّة يدوياً إلى محركات رؤية مرنة وعامة قادرة على التكيّف مع مهام وبيئات ومستشعرات جديدة. توفر شبكات الـCNN تعرفاً سريعاً وفعّالاً للنمط؛ تضيف المحولات فهماً أوسع وأكثر وعيًا بالسياق؛ ويربط الدمج متعدد الوسائط دلائل إضافية من العمق ودرجة الحرارة واللغة. معاً، تعدّ هذه التطورات بسيارات تتوقّع المخاطر بشكل أفضل، وأدوات تساعد الأطباء بثقة أكبر، وأجهزة منزلية تتفاعل بأمان وذكاء أكبر مع محيطها—قرباناً للرؤية البشرية الغنية.
الاستشهاد: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
الكلمات المفتاحية: كشف الأجسام, رؤية الحاسوب, التعلّم العميق, نماذج المحولات, الدمج متعدد الوسائط