Clear Sky Science · ar
معيار لتقييم كفاءة الاستجواب التشخيصي لنماذج اللغة الكبيرة في محادثات المرضى
لماذا تهم الأسئلة الطبية الأذكى
عندما تزور طبيبًا، نادرًا ما ينبع التشخيص الأول الذي تسمعه من عرض عرض واحد تذكره. بدلًا من ذلك، يطرح الأطباء سلسلة من الأسئلة الاستيضاحية—عن التوقيت، الشدة، المشاكل المصاحبة—ليضيّقوا تدريجيًا نطاق الاحتمالات. وبالرغم من قوة أنظمة الذكاء الاصطناعي الحالية، فإن معظم اختباراتها تُجرى كما لو أنها تختبر في امتحانات الاختيار من متعدد، وليس كما لو أنها تتحدث مع أشخاص حقيقيين. تقدم هذه الورقة Q4Dx، طريقة جديدة للحكم على مدى قدرة نماذج اللغة الكبيرة على أداء دور «الطبيب الفضولي»: اختيار الأسئلة الصحيحة، بالترتيب المناسب، للوصول بكفاءة إلى التشخيص الصحيح.
من أسئلة الامتحان إلى المحادثات الحقيقية
تعطي معظم اختبارات الذكاء الاصطناعي الطبي الحالية للنماذج حالات مرتبة ومحددة بالكامل—مثل مشكلة من كتاب دراسي—وتطلب منها اختيار تشخيص. هذا يبيّن ما «تعرفه» النظام، لكن ليس كيف سيتصرف في محادثة فوضوية في العالم الحقيقي مع مريض ينسى تفاصيل أو يصف الأعراض بلغة يومية. يجادل المؤلفون بأن هذه ثغرة خطيرة. في العيادات، تتكشف المعلومات ببطء وغالبًا بشكل غير دقيق؛ ومهارة الممارس الجيد تكمن بقدر ما في ما يسأله كما في ما يعرفه بالفعل. صُممت Q4Dx لسد هذه الفجوة عن طريق تحويل التركيز من الإجابة الثابتة على الأسئلة إلى استراتيجية طرح الأسئلة عبر الزمن.
بناء قصص مرضى تشبه الحياة الواقعية
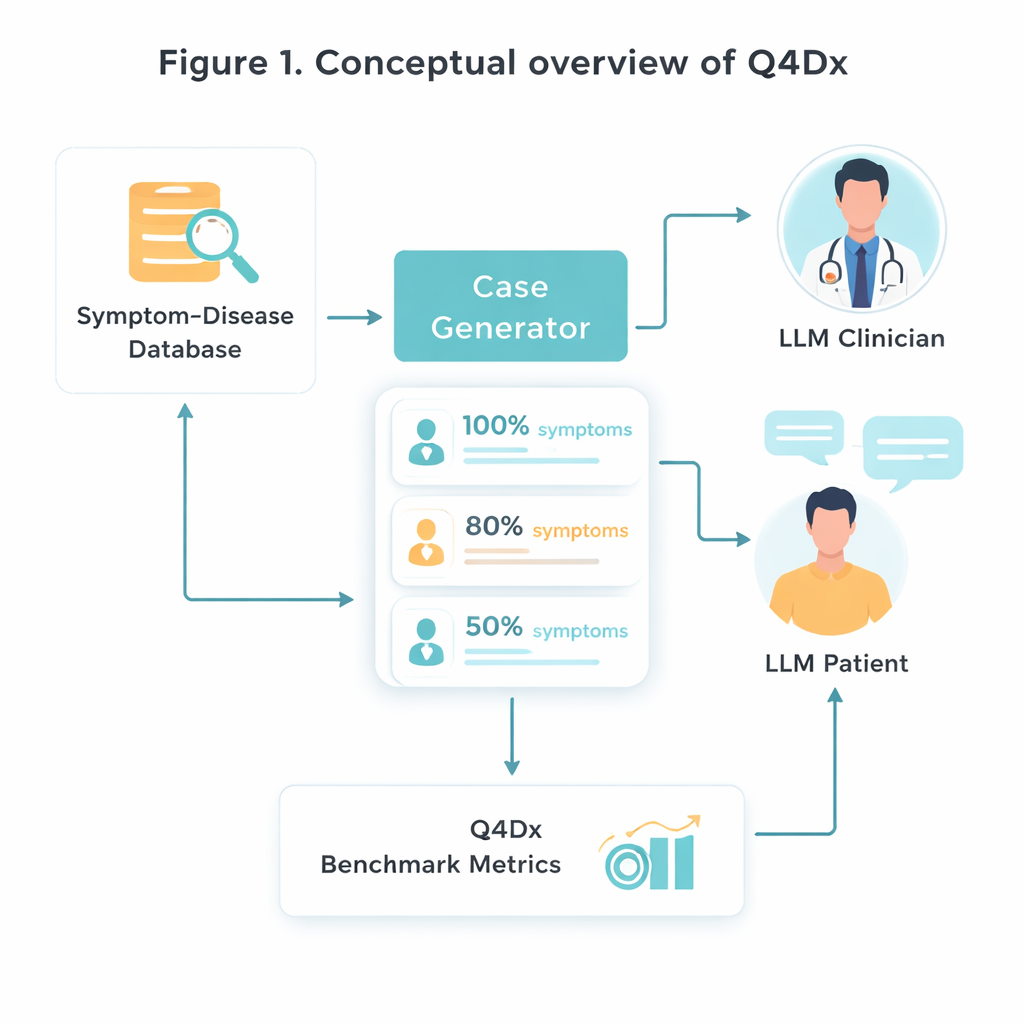
لبناء هذا الاختبار الجديد، يبدأ الباحثون من مصدر طبي مُنسَّق يربط أمراضًا محددة بمجموعات الأعراض المميزة لها. يختارون عشوائيًا 100 من أزواج المرض–الأعراض هذه ثم يستخدمون نموذج ذكاء اصطناعي لتحويل قوائم الأعراض الجافة إلى أوصاف ذاتية لصوت المريض تبدو طبيعية—قصص كما قد يرويها شخص في العيادة. من كل حالة كاملة، يولِّدون نسخًا أقصر حيث يُذكر فقط نحو 80 بالمئة أو 50 بالمئة من الأعراض المفتاحية. يتيح هذا الإخفاء المنضبط للمعلومات دراسة مدى تكيّف النماذج المختلفة عندما تكون المؤشرات المهمة مفقودة أو مجرد تلميحات. وتؤكد الفحوصات على تداخل الأعراض أن النسخ الأقصر تحتوي فعليًا على معلومات قابلة للاستخدام أقل، وليس مجرد كلمات أقل.
حوار محاكٍ بين الطبيب والمريض
جوهر Q4Dx هو مجموعة كبيرة من المحادثات المحاكاة بين وكيلين للذكاء الاصطناعي. يلعب أحدهما دور المريض، الذي يملك وصولًا كاملاً إلى المرض الأساسي ومجموعة الأعراض الكاملة. يعمل الآخر كطبيب: يرى فقط وصفًا جزئيًا، وربما غامضًا، للحالة في البداية ويجب أن يقرر ما الذي يسأل عنه تاليًا. بعد كل رد من المريض، يصدر الوكيل الطبي تشخيصًا مبدئيًا، مما يخلق أثرًا خطوة بخطوة لتطور تفكيره. من خلال تسجيل جميع الأسئلة والأجوبة والتخمينات الوسيطة، يلتقط المعيار ليس فقط ما إذا كان النموذج صائبًا، بل كيف وصل إلى ذلك. تُستخدم تسلسلات الأسئلة المنتجة بواسطة الذكاء الاصطناعي كاستراتيجيات مرجعية—لا كحقيقة طبية مطلقة، بل كمِسطرة ثابتة يمكن مقارنة النماذج المستقبلية وحتى المتدرّبين البشريين معها.
قياس جودة الأسئلة، لا الأجوبة فقط
لحكم الأداء، صمم المؤلفون ثلاثة مقاييس بسيطة لكنها مكمِّلة. الدقة التشخيصية بدون تدريب مسبق (ZDA) تسأل: إذا أعطيت النموذج الحالة كاملة من البداية، هل يمكنه تسمية المرض الصحيح فورًا؟ ومتوسط الأسئلة حتى التشخيص الصحيح (MQD) يعكس الكفاءة: في المتوسط، كم عدد الأسئلة التي يحتاجها النموذج من المريض قبل أن يصل لأول مرة إلى التشخيص الصحيح، ضمن حد أقصى خمسة؟ أخيرًا، كفاءة تسلسل الاستجواب (ISE) تنظر إلى جودة مسار الأسئلة نفسه—مدى تشابه الأسئلة التي يختارها النموذج في المعنى مع تسلسل المرجع. باستخدام هذه المقاييس، يُظهر الفريق أن نموذجًا عامًا قويًا (GPT‑4.1) يشخص بشكل صحيح نحو نصف المرات عندما تتوفر المعلومات الكاملة، لكن دقته تنخفض مع إخفاء الأعراض. وفي الوقت نفسه، تنجح جلساته التفاعلية عادة بعد عدد قليل فقط من الأسئلة المختارة جيدًا، وتنمو أسئلته أكثر توافقًا مع استراتيجيات شبيهة بالخبراء عبر الأدوار المتتالية.

ماذا يعني هذا لمستقبل الذكاء الاصطناعي الطبي
لغير المتخصصين، رسالة هذا العمل واضحة: في الطب، طرح الأسئلة الذكية لا يقل أهمية عن امتلاك الإجابات الصحيحة، ويجب تقييم الذكاء الاصطناعي على الجانبين. توفر Q4Dx إطارًا قابلاً لإعادة الاستخدام ومتاحًا للجمهور لتحقيق ذلك بالضبط. من خلال تقديم قصص مرضى واقعية بمقادير متفاوتة من المعلومات المفقودة، وخرائط محادثة مفصّلة، ومقاييس واضحة للدقة والكفاءة، يتيح المعيار للباحثين مقارنة أنظمة الذكاء الاصطناعي المختلفة وحتى مواجهتها مع الأطباء البشريين في ظروف مضبوطة. مع مرور الوقت، قد تساعد أدوات مثل Q4Dx في تدريب مساعدين سريريين أكثر أمانًا وموثوقية وتحسين كيفية تعلم الأطباء والطلاب فن المقابلة التشخيصية—دعمًا لتحسين الرعاية الفعلية للمرضى.
الاستشهاد: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
الكلمات المفتاحية: الذكاء الاصطناعي الطبي, التفكير التشخيصي, الحوار السريري, نماذج اللغة الكبيرة, استراتيجية السؤال