Clear Sky Science · ar
المقارنة بين نماذج التعرف على الأفعال للكشف عن إيذاء الذات في مجموعات بيانات استوديو والواقع الحقيقي
مراقبة المرضى بعيون رقمية
في المستشفيات النفسية يعمل الممرضون بلا كلل للحفاظ على سلامة المرضى، لا سيما أولئك المعرّضين لإيذاء أنفسهم. ومع ذلك، لا يستطيع حتى أكثر الموظفين إخلاصًا مراقبة كل غرفة في كل ثانية. تستقصي هذه الدراسة ما إذا كان بإمكان الذكاء الاصطناعي المساعدة عبر مسح الفيديو من كاميرات الأجنحة تلقائيًا لرصد علامات مبكرة على إيذاء الذات — مقدمًا طبقة حماية إضافية دون أن يحل محل الرعاية البشرية.
لماذا يصعب اكتشاف إيذاء الذات
إيذاء الذات — أي إصابة متعمدة يسببها الشخص لنفسه — يحدث غالبًا في لحظات قصيرة ومخبأة: خدش سريع تحت بطانية أو استخدام أداة صغيرة بعيدًا عن الأنظار. تعتمد أجنحة الطب النفسي على فحوصات دورية ومراقبة بالكاميرات، لكن النقاط العمياء، وإرهاق الطاقم، والحدود في التواجد الليلي أو خلال العطل تجعل اليقظة المستمرة أمرًا مستحيلًا. في المقابل، يثير تسجيل ومشاركة لقطات مرضى حقيقيين قضايا خطيرة تتعلق بالخصوصية والأخلاقيات. ونتيجة لذلك، توفرت للباحثين كمية قليلة جدًا من فيديوهات واقعية لتدريب أنظمة الذكاء الاصطناعي التي قد ترصد سلوكًا خطيرًا في الوقت الفعلي.
بناء مجموعات اختبار أكثر أمانًا للذكاء الاصطناعي
لكسر هذه المعضلة، أنشأ الباحثون نوعين من مجموعات الفيديو. أولًا، في استوديو مُهيأ ليبدو كغرفة نفسية بأربع أسِرّة، مثل سبعة ممثلين شباب يرتدون أردية مرضى وأدوا مشاهد مخططة بعناية. بحثوا عن أشياء يومية مثل أغطية بلاستيكية أو أنابيب مرهم شفاه أو مسامير صغيرة، ثم مثلوا تسلسلات قصيرة من حركات إيذاء الذات على المعصم أو الساعد أو الفخذ، مع تسجيل الكاميرات من الزوايا العلوية لكل الركن. وصّف الخبراء كل مقطع فيديو كتصرف طبيعي أو إيذاء للذات، فبَنَوا مجموعة نظيفة ومتوازنة مكونة من 1120 مقطعًا. ثانيًا، جمع الفريق لقطات مراقبة حقيقية من أجنحة نفسية مؤمنة على مدار عشرة أشهر. بحث الأطباء في السجلات الطبية عن ملاحظات تتعلق بسلوكيات مثل الخدش أو النقش أو القطع ثم عثروا على الفيديو المطابق. بعد تمويه الوجوه وإزالة التفاصيل المعرفية، جمعوا 59 مقطعًا تُظهر إيذاء ذات حقيقيًا و59 مقطعًا طبيعيًا للمقارنة.
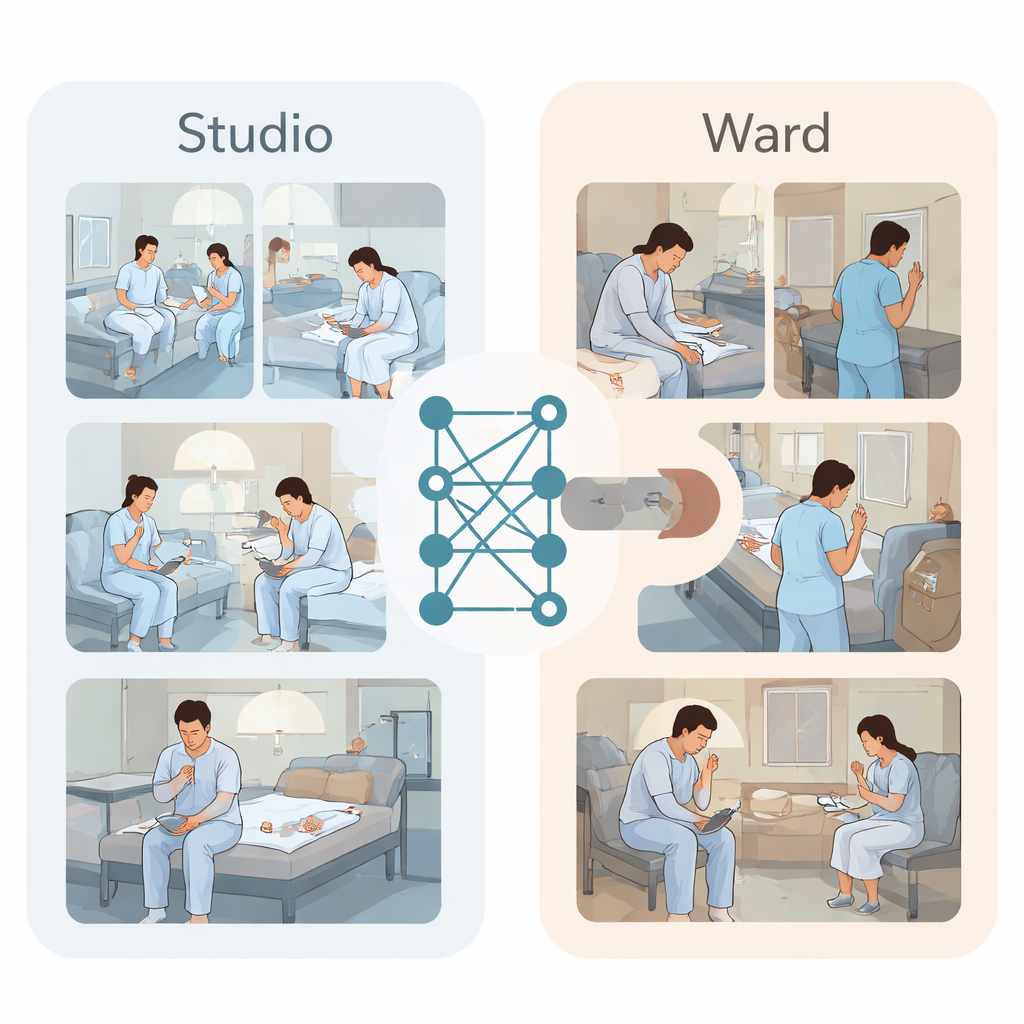
اختبار أفضل تقنيات الذكاء البصري الحالية
مع توافر هذه المجموعات، قَيَّم الفريق أنظمة التعرف على الأفعال الرائدة — برامج حاسوبية مصممة لفهم ما يفعله الأشخاص في الفيديو. بَعضها قائم على شبكات التفاف قديمة تحلل تسلسلات قصيرة من الإطارات، بينما تستخدم النماذج الأحدث القائمة على المحولات آليات الانتباه لربط الأنماط عبر الزمان والمكان. دُرِّبت جميع النماذج على فيديوهات الاستوديو فقط لتقرير ما إذا كان المقطع يُظهر إيذاء الذات أو سلوكًا طبيعيًا. ومن المهم أن الباحثين اتبعوا مخطط اختبار صارم: في كل جولة، حُجبت كل المقاطع الخاصة بممثل واحد كبيانات اختبار جديدة بالكامل، ما ضمن أن الخوارزميات لم تستطع الاكتفاء بحفظ أفراد بعينهم.
عندما تلتقي فيديوهات الاستوديو النظيفة بالواقع الفوضوي
على لقطات الاستوديو المرتبة، برز النموذج المحوَّل الأكثر تقدمًا المسمى VideoMAEv2. لقد حقق توازنًا أفضل بين الأخطاء الفائتة والتنبيهات الكاذبة مقارنةً بالآخرين، حيث بلغ مقياس F1 (مقياس يجمع الدقة والاستدعاء) نحو 0.65، بينما تقاربت الأساليب الأبسط مع التخمين العشوائي. أوضحت التفسيرات البصرية أن هذا النموذج ركز بدقة على موضع التماس بين الأداة والجلد بدلًا من أن يشتت بالتحركات الخلفية. لكن بمجرد إطلاق هذه النظم المدربة على تسجيلات الجناح الحقيقية — دون أي إعادة تدريب — تراجع أداؤها. ظل VideoMAEv2 أفضل من الحظ، بمقياس F1 يقارب 0.61، لكنه واجه صعوبة خاصةً مع السلوكيات الطفيفة مثل النقش والخدش التي لم تظهر في البيانات المحاكية، ومع المرضى الصغار أو البعيدين عن الكاميرا أو المستترين جزئيًا.
ما معنى ذلك لسلامة المرضى
عند جمع النتائج معًا تتضح فجوة واضحة بين المحاكاة والواقع. قد تتعثر أنظمة الذكاء الاصطناعي الواعدة عند اختبارها في بيئة المستشفى الحقيقية المليئة بالفوضى والزوايا الغريبة والسلوكيات المتباينة. المساهمة الأساسية للدراسة ليست منتج سلامة جاهزًا ولكن نقطة انطلاق: مجموعة بيانات استوديو عامة وموسومة جيدًا، ومجموعة اختبار واقعية جُمعت بعناية، ومعيار شفاف يوضح أماكن فشل الطرق الحالية. للقراء غير المتخصصين، الرسالة مباشرة: يمكن للذكاء الاصطناعي بالفعل المساعدة في تمييز اللحظات المشبوهة في بث الكاميرات داخل الأجنحة، لكنه لا يزال غير موثوق كحارس مستقل. وسد هذه الفجوة سيحتاج إلى بيانات تدريب أغنى وأكثر تنوعًا ونماذج أذكى، تُطوَّر مع وضع الخصوصية والعدالة والحكم السريري في المقام الأول.
الاستشهاد: Lee, K., Lee, D., Ham, HS. et al. Benchmarking action recognition models for self-harm detection in studio and real-world datasets. Sci Rep 16, 6850 (2026). https://doi.org/10.1038/s41598-026-36999-w
الكلمات المفتاحية: كشف إيذاء الذات, أجنحة الطب النفسي, التعرف على الأفعال في الفيديو, الذكاء الاصطناعي في الرعاية الصحية, سلامة المرضى