Clear Sky Science · ar
MQADet: نمط توصيل وتشغيل لتعزيز كشف الكائنات ذات المفردات المفتوحة عبر الإجابة متعددة الوسائط عن الأسئلة
لماذا يهم وجود مكتشفات كائنات أذكى
تعتمد الهواتف والسيارات والروبوتات المنزلية ومحركات البحث بشكل متزايد على برامج قادرة على العثور على كائنات في الصور: طفل يعبر الشارع، مفاتيحك الضائعة على الطاولة، أو منتج محدد على رف المتجر. لكن معظم أنظمة اليوم تفهم في الغالب تسميات قصيرة وبسيطة مثل «كلب» أو «سيارة». عند طلب «الكلب الصغير ذو الطوق الأحمر المستلقٍ خلف وسادة الأريكة» غالبًا ما ترتبك. تقدم هذه الورقة MQADet، وسيلة لترقية أنظمة العثور على الكائنات الحالية بحيث تفهم أوصافًا غنية ومفصلة كهذه دون إعادة تدريب النماذج الأساسية.
من قوائم ثابتة إلى فهم مفتوح النهاية
تُدرّب كاشفات الكائنات التقليدية على قوائم فئات ثابتة، مثل 80 عنصرًا يوميًّا في مجموعة بيانات COCO الشهيرة. تعمل جيدًا ما دام الكائن ينتمي لإحدى تلك الفئات ويكون الطلب قصيرًا وواضحًا. لكن العالم الحقيقي فوضوي. يشير الناس إلى الأشياء بعبارات طويلة، وسمات دقيقة، وعلاقات مثل «الرجل في السترة الصفراء الواقف خلف الشاحنة». تحاول الكاشفات الأحدث ذات «المفردات المفتوحة» التحرر من القوائم الثابتة بربط الصور بالنص، لكنها ما تزال تواجه صعوبة مع الصياغات المعقدة والفئات النادرة أو «ذوات الذيل الطويل» التي تظهر نادرًا في بيانات التدريب. كما أنها تتطلب الكثير من الحوسبة والبيانات للتحسن.
إتاحة نماذج اللغة لقيادة البحث
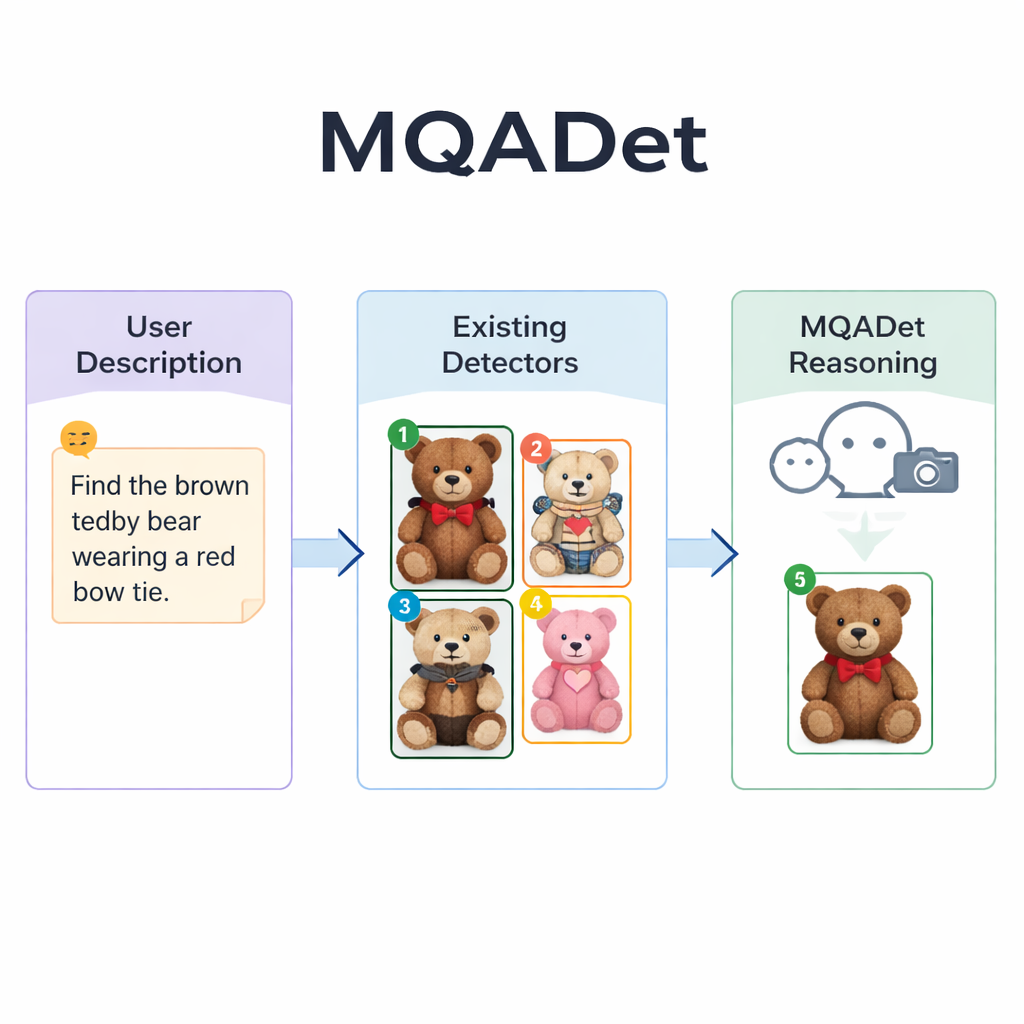
تتعامل MQADet مع هذه المشكلات بوضع نموذج لغوي كبير متعدد الوسائط — نظام يمكنه رؤية الصور وقراءة النص — فوق الكاشفات الموجودة في عملية مكوّنة من ثلاث خطوات للإجابة على الأسئلة. أولًا، مرحلة تسمى استخلاص الموضوعات الواعية بالنص تقرأ جملة المستخدم الكاملة وتستخرج الأهداف الحقيقية، مثل «مظلة» و«مشاة» من وصف طويل. هذا يشبه كيف قد يحدّد الإنسان الأسماء الرئيسية في الجملة قبل مسح المشهد. والأهم أنها تستفيد من فهم نموذج اللغة القوي للغة الطبيعية، فتتعامل مع عبارات وصفية طويلة بدل الكلمات المفردة فقط.
وضع علامات على الكائنات المرشحة في الصورة
في المرحلة الثانية، وضع الكائنات متعددة الوسائط الموجَّه بالنص، تسلّم MQADet تلك الموضوعات المستخرجة بالإضافة إلى الصورة إلى كاشف مفتوح المفردات موجود — مثل Grounding DINO أو YOLO-World أو OmDet-Turbo. يقترح الكاشف عدة مواقع محتملة في الصورة لكل موضوع، مرسومًا مربعًا حول كل مرشح ومضعًا رقمًا بسيطًا داخل المربع. النتيجة «صورة معنّمة» تُظهر كل الخيارات المعقولة. ومن المهم أن MQADet لا تعيد تدريب هذه الكاشفات؛ بل تستخدمها كما هي. هذا يجعل النهج قابلاً للتوصيل والتشغيل: عندما يظهر كاشف أفضل يمكن استبداله في المسار دون بيانات أو ضبط إضافي.

الاستدلال لاختيار المطابقة الأفضل
المرحلة الثالثة، المسماة اختيار الكائن الأمثل المدفوع بنماذج اللغة متعددة الوسائط، تحوّل الاختيار النهائي إلى سؤال متعدد الخيارات للنموذج اللغوي: بالنظر إلى الوصف الأصلي والصورة المعنّمة بصناديق مرقّمة، أي رقم يطابق النص بشكل أفضل؟ لأن النموذج يرى كلًا من الصياغة التفصيلية والتخطيط البصري، يمكنه وزن دلائل دقيقة — أنماط، ألوان، علاقات مكانية مثل «على اليسار»، وتفاعلات بين الكائنات. يُظهر المؤلفون أن إزالة خطوة الاستدلال هذه تُقلّص الدقة بشدة، ما يؤكد أهميتها. باستخدام هذا التصميم المكوّن من ثلاث خطوات، حسّنت MQADet الدقة عبر أربعة معايير صارمة تحتوي على جمل طبيعية طويلة، غالِبًا بزيادة أداء الكاشفات الحالية بمقدار 10–40 نقطة مئوية دون تغيير أوزانها الداخلية.
ماذا يعني هذا لتقنيات الحياة اليومية
بالنسبة لغير المتخصصين، الرسالة الأساسية هي أننا لم نعد بحاجة لإعادة بناء كاشفات الكائنات من الصفر لجعلها أذكى. تعمل MQADet كمساعد ذكي يجلس فوق الأنظمة الحالية، يساعدها على تفسير أوصاف البشر الغنية واختيار الكائن الصحيح في المشاهد المعقدة. يمكن أن يجعل هذا البحث البصري، والأدوات المساعدة، والآلات المستقلة أكثر موثوقية عند التعامل مع طريقة تحدث الناس الطبيعية — المليئة بالتفاصيل والدقة والسياق — ممهّدًا الطريق لتفاعل بصري مدفوع باللغة أكثر بديهية.
الاستشهاد: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
الكلمات المفتاحية: كشف الكائنات ذات المفردات المفتوحة, نماذج لغوية كبيرة متعددة الوسائط, الإجابة البصرية على الأسئلة, الرؤية الحاسوبية, فهم الصور