Clear Sky Science · ar
ردم فجوة الأداء: تحسين منهجي لنماذج اللغة المحلية لاستخراج معلومات PHI الطبية باليابانية
لماذا هذا مهم لخصوصية المرضى
تحتفظ المستشفيات بمجموعة هائلة من السجلات الطبية التي يمكن أن تحسّن الرعاية والبحث، لكن هذه السجلات مليئة بتفاصيل حساسة مثل الأسماء والعناوين والتواريخ. أنظمة الذكاء الاصطناعي السحابية القوية تجيد إخفاء هذه المعلومات، ومع ذلك لا يُسمَح للعديد من المستشفيات بإرسال بيانات المرضى الخام إلى خوادم خارجية. تظهر هذه الدراسة أنه مع ضبط دقيق، يمكن لنماذج ذكاء اصطناعي أصغر تعمل بالكامل داخل المستشفى أن تقترب بشكل مفاجئ من أداء أفضل أنظمة السحابة—مما يوفر وسيلة لاستخدام الذكاء الاصطناعي مع إبقاء بيانات المرضى آمنة في الموقع.
معضلة الخصوصية مقابل التقدّم
نماذج اللغة الكبيرة الحديثة قادرة ذات موثوقية على تحديد وإزالة معلومات الصحة المحمية (PHI) من النصوص الطبية، وغالباً ما تتجاوز دقتها 90 بالمئة. ومع ذلك، فإن إرسال ملاحظات المرضى غير المحررة إلى خدمات السحابة يثير مخاوف قانونية وأخلاقية بموجب لوائح مثل HIPAA وGDPR وقانون حماية المعلومات الشخصية الياباني (APPI). تصر مؤسسات كثيرة على «سيادة البيانات» الكاملة، أي أن المعلومات لا تغادر أجهزتها. حتى الآن، كانت النماذج المحلية التي يمكن تشغيلها على أجهزة داخلية تُفوِّت غالباً عدداً أكبر من المعرفات، مما يضع المستشفيات أمام مقايضة: تحليلات قوية في السحابة أو خصوصية أشد بأدوات أضعف. سعى الباحثون إلى معرفة ما إذا كان يمكن تضييق هذه الفجوة بما يكفي للاستخدام السريري في العالم الحقيقي.
خطة مُدرجة لنظام محلي أذكى
صمم الفريق إطار عمل من خمس خطوات لتحسين أداء نماذج اللغة المحلية تدريجياً في إزالة PHI من تقارير الأشعة اليابانية. بدأوا بـ14 نموذجاً مختلفاً بأحجام متنوعة، تعمل جميعها على حاسوب معزول وخالٍ من الإنترنت لمحاكاة أمان المستشفى. باستخدام 160 تقريراً تركيبياً مُصاغاً بعناية—واقعية لكنها خيالية بالكامل—قاسوا مدى قدرة كل نموذج على اكتشاف وفصل ثمانية أنواع من المعرفات، من الأسماء وأرقام الهوية إلى التواريخ والأقسام. بعد اختبار أساسى مبدئي، أنشأوا مطالبات عامة أكثر إفادة، ثم صاغوا تعليمات مُخصصة لخصوصيات كل نموذج، أضافوا حلقة آلية «التحقق الذاتي والتصحيح»، وأخيراً اختبروا أفضل المرشحين على مجموعة احتياطية من التقارير. 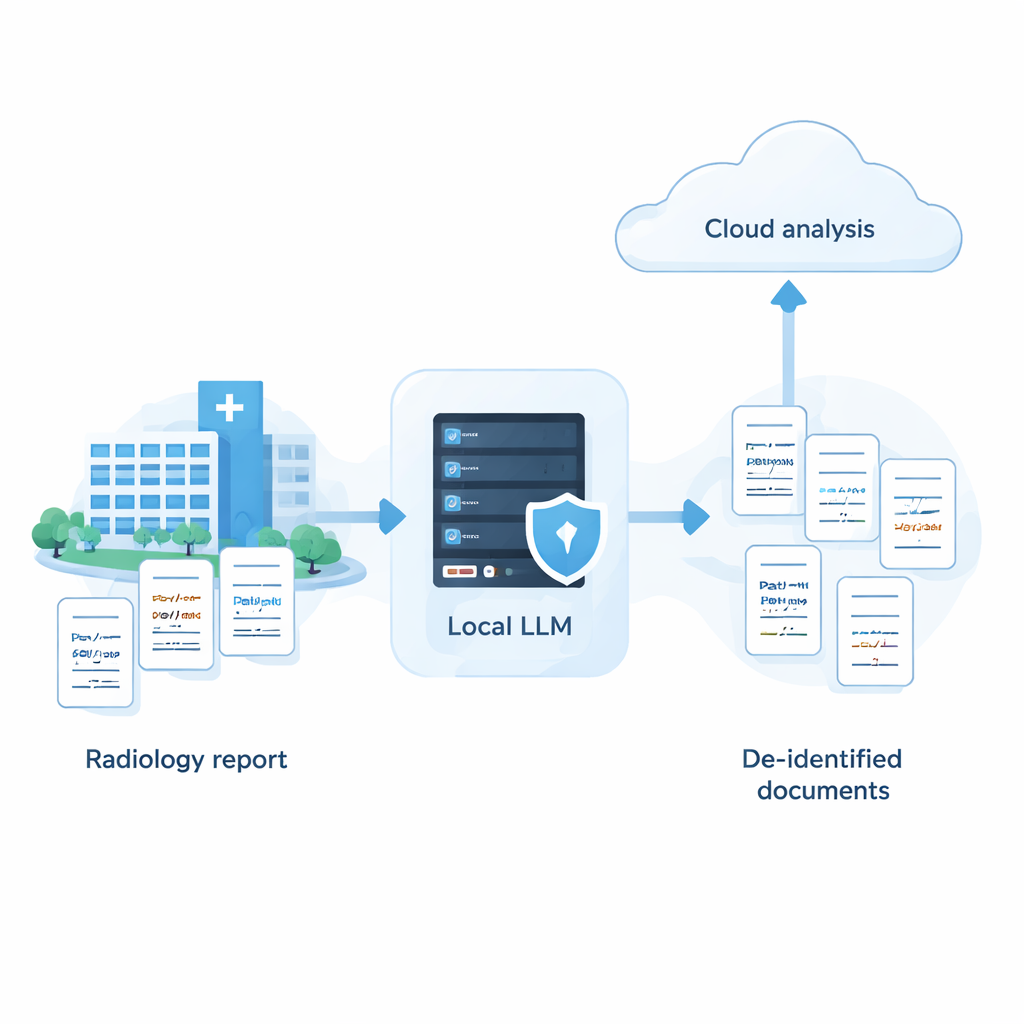
الاقتراب من أداء السحابة
من خلال هذه العملية المرحلية، اكتشف الباحثون أن حجم النموذج الخام لم يكن العامل الحاسم للنجاح؛ فبعض الأنظمة الكبيرة جداً أدت أداءً ضعيفاً. بدلاً من ذلك، كانت النماذج الأكثر وعداً تلك التي استجابت جيداً لتصميم التعليمات وتحليل الأخطاء. أصبح أحد الأنظمة متوسطة الحجم، Mistral-Small-3.2، الفائز الواضح بعد المطالبات المخصصة وخطوة التنقيح الذاتي حيث راجع النموذج مخرجاته وصحّح بعضاً منها انتقائياً. في 60 حالة اختبار نهائية حصل هذا الإعداد المحلي المحسّن على 91.54 من 100—أي حوالي 97.8 بالمئة من نتيجة أفضل نموذج سحابي التي بلغت 93.56—مع الالتزام التام بقواعد التنسيق. بمعنى عملي، اعتُبر القصور المتبقّي ضئيلاً من الناحية السريرية. وكانت التكلفة الرئيسية هي السرعة: استغرق المعالجة محلياً نحو 25 ثانية لكل تقرير نموذجي، مقارنة بأقل من ثانيتين في السحابة، لكن هذا اعتُبر مقبولا لأعمال الدُفعات الروتينية غير الطارئة. 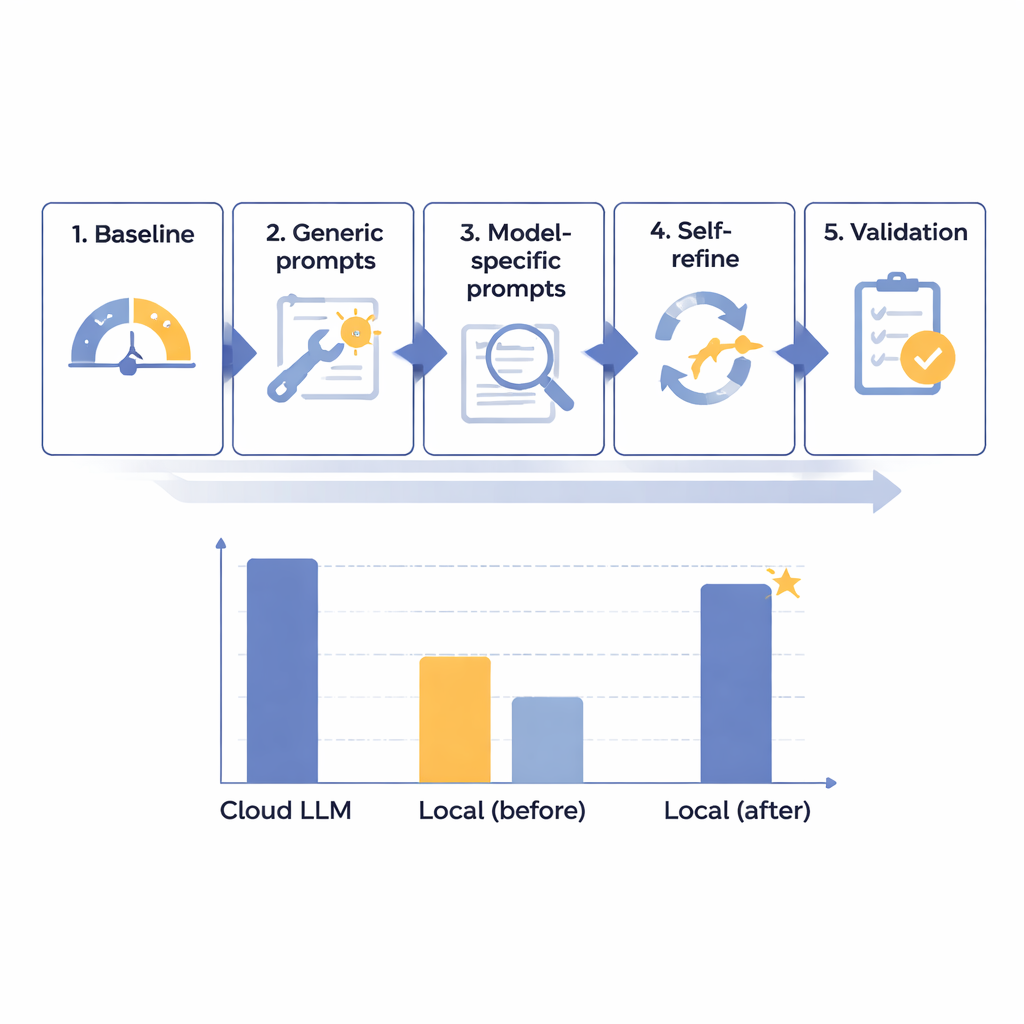
عتبة مفاجئة للتصحيح الذاتي
من النتائج الأكثر إثارة للاهتمام نقطة تحول بنحو 87–88 نقطة على مقياس المؤلفين المكوّن من 100 نقطة. النماذج التي حصلت على نقاط أدنى من هذا المستوى في الاختبار الأساسي—مثل Mistral-Small-3.2—استفادت كثيراً من حلقة التنقيح الذاتي، محققة ما يقرب من سبع نقاط إضافية عن طريق تصحيح جزء صغير من أخطائها. أما النماذج التي بدأت بالفعل فوق هذه العتبة فلم تُظهر تقريباً أي تحسُّن، وأحياناً أهدرت جهداً بمحاولة «تصحيح» إجابات صحيحة. يشير ذلك إلى أن أدوات التحسين المتقدمة ينبغي أن تُحفَظ للنماذج الجيدة لكنه غير الممتازة، مما يتيح للمستشفيات تركيز قدرة الحوسبة ووقت الموظفين حيث يُحدث الفرق الأكبر. يحذّر المؤلفون أن هذه العتبة مبنية على نموذجين فقط وتحتاج لتأكيد، لكنها تقدّم قاعدة إرشادية مبكرة لتخطيط النشر.
مغزى ذلك للمستشفيات والمرضى
تؤكد الدراسة أن على المستشفيات ليس عليها الاختيار بين خصوصية قوية وذكاء اصطناعي قوي. باتباع نهج منهجي—فرز العديد من النماذج، وضبط المطالبات حسب نقاط القوة والضعف، وإضافة خطوة مراجعة ذاتية ذكية—يمكن لنظام محلي بالكامل أن يقترب من دقة خدمات السحابة الرائدة في إزالة المعلومات الحساسة من النصوص الطبية. عملياً، يفتح ذلك الباب أمام استراتيجية هجينة: تُزال PHI بأمان على أجهزة مملوكة للمستشفى، ولا تُرسل إلى السحابة إلا التقارير المجهولة الهوية بعد إزالة الأسماء والمعرفات الأخرى لإجراء تحليلات متقدمة. وبينما استند العمل حتى الآن إلى تقارير أشعة يابانية تركيبية ويجب اختباره على بيانات العالم الحقيقي ولغات أخرى، فإنه يقدّم خارطة طريق قابلة للتنفيذ للمؤسسات التي ترغب في الاستفادة من الذكاء الاصطناعي مع إبقاء ثقة المرضى وخصوصيتهم في الصدارة.
الاستشهاد: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
الكلمات المفتاحية: إزالة الهوية الطبية, خصوصية المرضى, نماذج اللغة المحلية, الذكاء الاصطناعي في الرعاية الصحية, تقارير الأشعة