Clear Sky Science · ar
تقدير التباين القائم على تعلّم الآلة تحت أخذ العينات ذي المرحلتين باستخدام بيانات قطاعَي الصحة والتعليم
لماذا تهم المتوسطات الأذكى في القرارات الواقعية
عندما يدرس الأطباء ضغط الدم أو يتابع المعلمون درجات الطلاب، لا يهتمون فقط بالمتوسط؛ بل يحتاجون إلى معرفة مدى تباين الأفراد حول ذلك المتوسط. هذا الانتشار، المسمى بالتباين، يحدد عدد المرضى اللازمين لتجنيدهم في تجربة، وحجم برنامج التدريس المكثف، ومدى ثقتنا في قرارات السياسة. الورقة التي تلخّصها هذه المادة تقدم طريقة إحصائية جديدة لقياس هذا التباين بدقة أكبر من خلال مزج أفكار أخذ العينات الكلاسيكية مع تعلم الآلة الحديث، وقد اختُبرت على بيانات من قطاعَي الصحة والتعليم.
قياس التشتت حين تكون المعلومات غير مكتملة
في عالم مثالي، يعرف الباحثون تفاصيل إضافية عن كل فرد في المجتمع قبل إجراء المسح: العمر، عادات الدراسة، التاريخ الطبي، وغير ذلك. في الواقع، تلك المعلومات غالباً ما تكون ناقصة أو مكلفة لجمعها. يعمل المؤلفون ضمن تصميم يدعى أخذ العينات ذي المرحلتين للتعامل مع هذا الوضع. في المرحلة الأولى، يأخذون عينة كبيرة نسبياً ورخيصة ويسجلون معلومات خلفية بسيطة، مثل العمر أو ما إذا كان لدى الشخص اتصال بالإنترنت. في المرحلة الثانية، يسحبون عيّنة فرعية أصغر ويقيسون نتيجة أكثر تكلفة أو استهلاكاً للوقت، مثل ضغط الدم الانقباضي أو درجات الامتحان النهائي. التحدي هو استخدام هاتين الطبقتين من المعلومات لتقدير مدى تباين النتيجة فعلاً في المجتمع بأكمله.
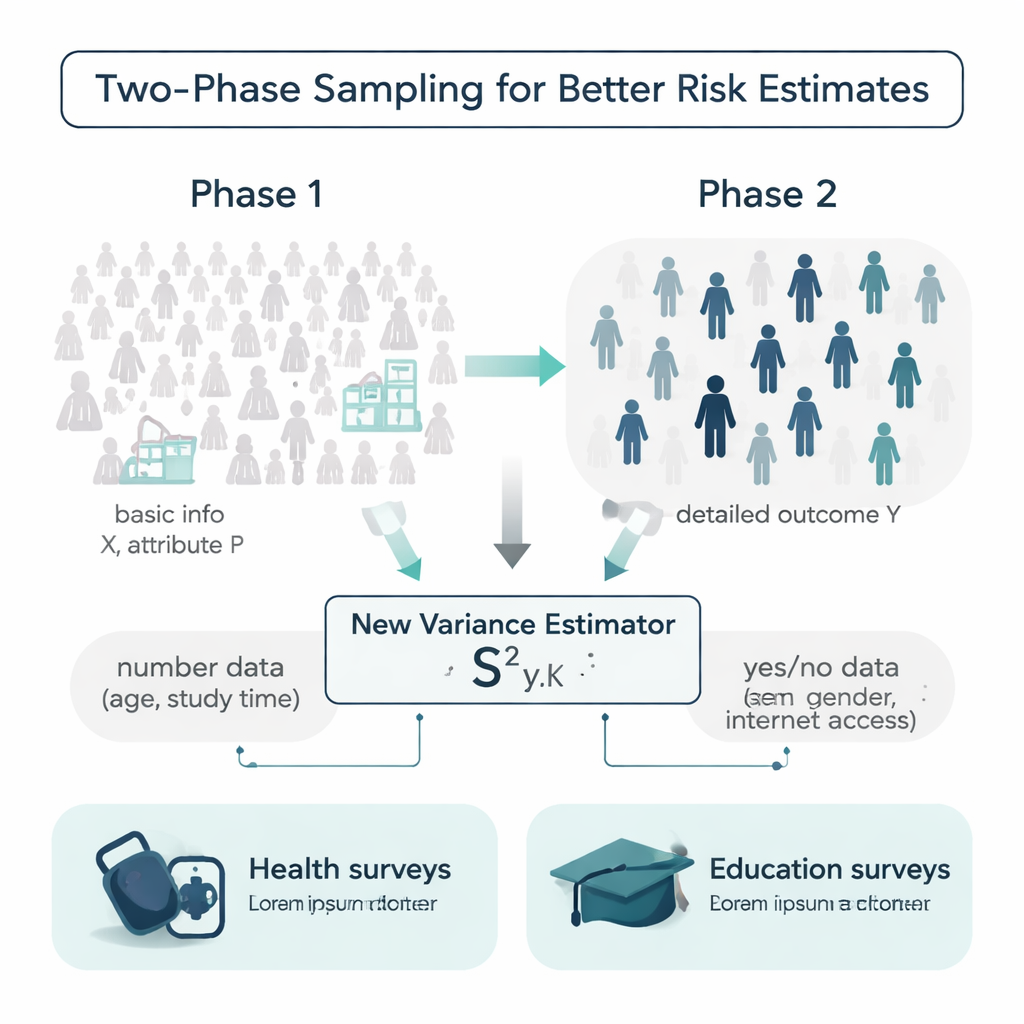
مقدر جديد يستخدم الأرقام والصفات نعم/لا معاً
تعتمد معظم الأدوات التقليدية لقياس التباين على النتيجة نفسها أو على متغير مساعد واحد فقط، وغالباً ما تفترض أن البيانات تتبع توزيعات مريحة على شكل جرس. يقترح المؤلفون مقدراً جديداً للتباين يستخدم نوعين من المعلومات المساعدة في الوقت نفسه: عامل رقمي (مثل العمر أو ساعات الدراسة الأسبوعية) وصفة ثنائية نعم/لا (مثل الجنس أو وجود اتصال بالإنترنت). يوضحون رياضياً كيف يتصرف هذا المقدر «المركّب» ويستنتجون صيغاً للتحيّز ومربع الخطأ المتوسط — وهما مقياسان رئيسيان للدقة. تحت شروط معقولة، يكون المقدر خالياً فعلياً من التحيّز وتكون قيمته المتوقعة للخطأ أصغر من تلك الخاصة بالمعادلات المنافسة واسعة الاستخدام، مما يعني أنه ينبغي أن يوفر تقديرات عدم يقين أكثر حدة من نفس كمية البيانات.
اختبار الأداء عبر عوالم بيانات متعددة
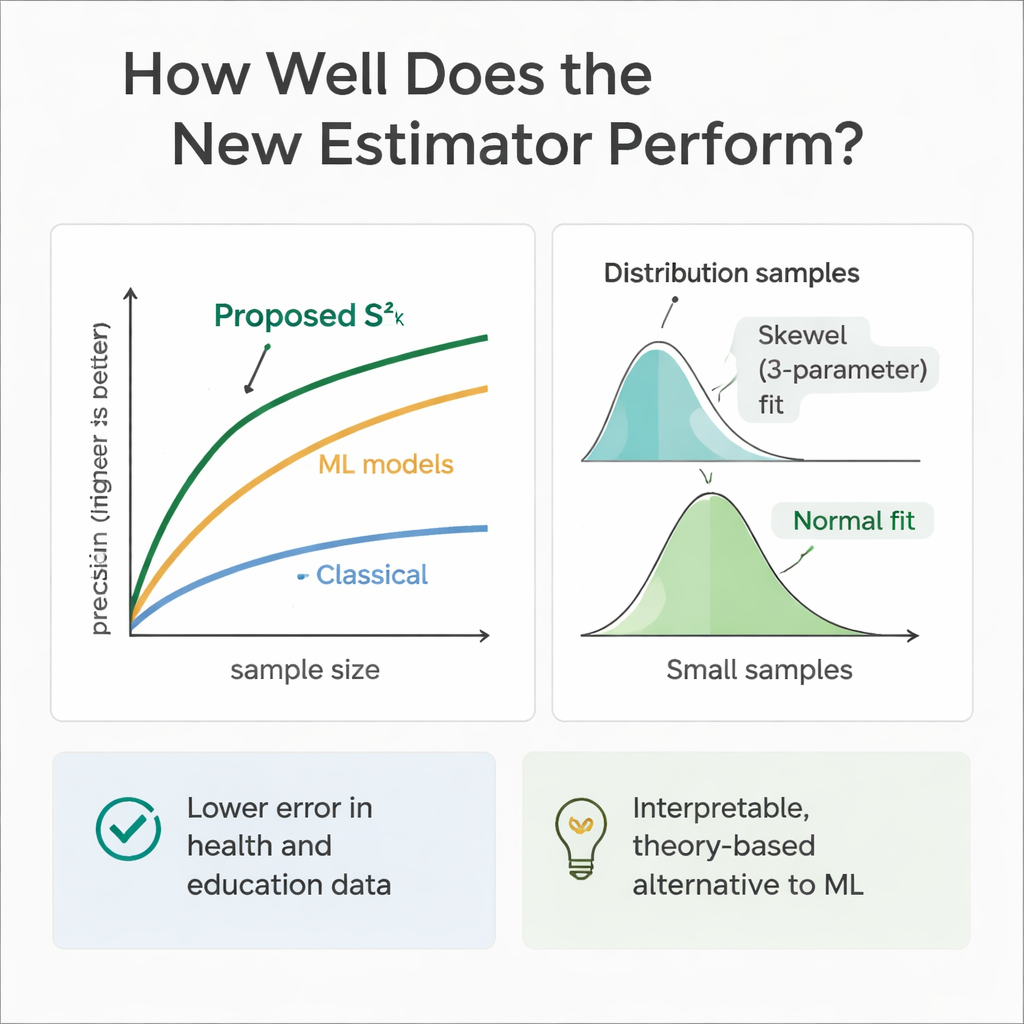
للتحقق مما إذا كانت النظرية تنطبق على الممارسة، أجرى الفريق تجارب حاسوبية مكثفة. قاموا بمحاكاة مجتمعات حيث تتبع المتغيرات المساعدة والنتيجة مجموعة من التوزيعات، من المتماثلة (عادية وموحدة) إلى المائلة (جاما وفايبول). باستخدام أخذ عينات متكرر، قارنوا خطأ المقدر الجديد مع عدة طرق معتمدة عبر أحجام عينات مختلفة. في الغالبية العظمى من الحالات، وخاصة مع زيادة حجم العينات، أظهر الأسلوب الجديد كفاءة نسبية أعلى بكثير — وغالباً ما خفّض الخطأ بنسبة 30 إلى 70 في المئة مقارنة بمقدر التباين الكلاسيكي. كما فحص المؤلفون كيف يتصرف توزيع أخذ العينات الخاص بالمقدر نفسه، ووجدوا أن منحنى وايبول ذو ثلاث معاملات يصفه بشكل أفضل للعينات المتواضعة، بينما يميل نحو شكل طبيعي مع ازدياد حجم العينات.
بيانات واقعية من العيادات والفصول الدراسية
ثم طُبّق الأسلوب على دراستي حالة من العالم الحقيقي. في مجموعة بيانات صحية، كانت النتيجة هي ضغط الدم الانقباضي، مع العمر كعامل رقمي والجنس كصفة ثنائية. في مجموعة بيانات تعليمية، كانت النتيجة هي الدرجة النهائية في المقرر، وكان العامل هو وقت الدراسة الأسبوعي، والصفة هي ما إذا كان الطالب يمتلك اتصالاً بالإنترنت. في كلتا الحالتين، قدّم المقدر المقترح أصغر مربع خطأ متوسط بين جميع المنافسين الإحصائيين المختبرين، مما ضيّق تقدير التباين حول متوسط ضغط الدم وأداء الطلاب المتوسط بشكل ملحوظ. يترجم هذا التحسّن إلى فواصل ثقة أكثر دقة ومقارنات أكثر اعتمادية بين المجموعات أو التدخّلات.
كيف يقارن بتعلم الآلة
بما أن نماذج تعلم الآلة تتفوّق في التنبؤ، درّب المؤلفون أشجار الانحدار والغابات العشوائية والانحدار بدعم المتجهات على نفس السيناريوهات المحاكاة في الصحة والتعليم. هذه النماذج، المُزوّدة بنفس المتغيرات المساعدة، حققت غالباً دقة تنبؤية مساوية أو متفوقة قليلاً على المقدر الجديد من حيث الأداء التنبؤي الخالص. إلا أنها تتصرف كصناديق سوداء: من الصعب تتبّع كيف تجمع المعلومات بالضبط، ويفتقرون إلى الصيغ الواضحة اللازمة للاستدلال التقليدي في المسوح. بالمقابل، المقدر المقترح شفاف وجذوره في نظرية أخذ العينات، مما يجعله أسهل في التبرير في بيئات تنظيمية أو سريرية أو سياساتية حيث تهم الشفافية بقدر أهمية الأداء الخام.
ماذا يعني هذا للمسوحات في الممارسة العملية
بعبارات بسيطة، تُظهر هذه الدراسة أن الباحثين يمكنهم الحصول على مقاييس أكثر موثوقية للتشتت دون زيادة كبيرة في حجم العينات، ببساطة عن طريق الاستفادة الممنهجة حتى من المعلومات الإضافية الضئيلة التي يجمعونها بالفعل. من خلال مزج عامل رقمي (مثل العمر أو وقت الدراسة) مع صفة بسيطة نعم/لا (مثل الجنس أو الوصول إلى الإنترنت) في خطة أخذ عينات من مرحلتين، يمنح المقدر الجديد تقديرات تباين أدق وأكثر ثباتاً من الطرق التقليدية طويلة الأمد. وبينما تبقى أدوات تعلم الآلة المتقدمة مفيدة كمعايير مرجعية، فإن هذا النهج يقدم حلّاً عملياً وقابلاً للتفسير في منتصف الطريق، يساعد محللي الصحة والتعليم على استخلاص استنتاجات أقوى من بيانات محدودة.
الاستشهاد: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
الكلمات المفتاحية: أخذ عينات المسح, تقدير التباين, تعلم الآلة, بيانات صحية, أبحاث التعليم