Clear Sky Science · ar
التحقق من صحة الأخبار بالأردية باستخدام التعلم العميق مع تضمين BERT و GloVe المدمجين
لماذا يهم اكتشاف الأخبار المزيفة بالأردية
في باكستان وحول العالم، يحصل الآن عدد أكبر من الناس على أخبارهم من المواقع الإلكترونية ووسائل التواصل الاجتماعي أكثر من الصحف أو التلفاز. جعل هذا التحول من السهل أكثر من أي وقت مضى انتشار القصص الكاذبة بسرعة، خصوصًا باللغات الوطنية مثل الأردية حيث الأدوات الرقمية محدودة. تتناول هذه الدراسة سؤالًا بسيطًا لكنه عاجلًا: هل يمكن للذكاء الاصطناعي الحديث أن يميّز تلقائيًا بين الأخبار الأردية الحقيقية والمزيفة، مما يساعد القراء العاديين والصحفيين والمنصات على الدفاع عن أنفسهم من المعلومات المضللة؟
التحدي المتزايد للمعلومات المضللة عبر الإنترنت
يبدأ المؤلفون بتوضيح كيف يمكن للعناوين الملفقة والقصص المشوهة تشكيل الرأي العام، وتصعيد التوترات السياسية، وحتى الإضرار بصحة الناس وأموالهم. بينما تركز العديد من مواقع التحقق من الحقائق والمشروعات البحثية على الإنجليزية، غالبًا ما تُترك اللغات الإقليمية مثل الأردية خلف الركب. تشمل الموارد الأردية الحالية بضعة آلاف فقط من الأخبار، كثير منها مترجم من الإنجليزية ومركّز على مواضيع ضيقة مثل السياسة. وهذا يجعل من الصعب تدريب أنظمة حاسوبية موثوقة للتعرف على المحتوى المريب باللغة التي يقرأها معظم الباكستانيين فعليًا.
بناء مجموعة كبيرة من الأخبار الأردية
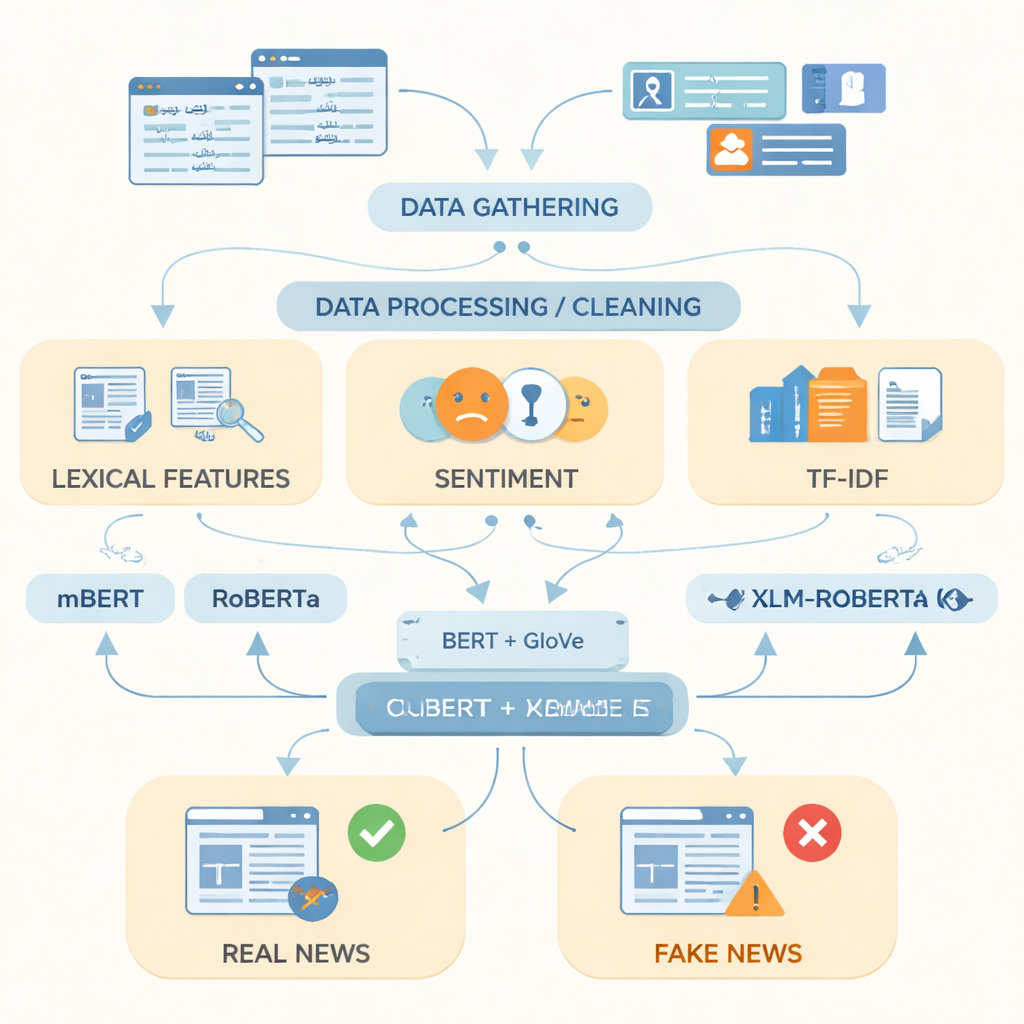
لسد هذه الفجوة، جمع الباحثون ما وصفوه بأكبر مجموعة بيانات للأخبار المزيفة بالأردية حتى الآن، تحتوي على 14,178 مقالة إخبارية جُمعت بين 2017 و2023 من مواقع إخبارية ومنصات إلكترونية باكستانية محترمة. تمتد القصص عبر خمسة عشر مجالًا من الحياة اليومية، بما في ذلك السياسة والصحة والتعليم والأعمال والجريمة والرياضة والبيئة. باستخدام مصادر التحقق من الحقائق مثل PolitiFact وFactCheck وواجهات برمجة تطبيقات إخبارية متخصصة، وُسِّم كل عنصر كحقيقي أو مزيف؛ أما العناصر الجزئية الصحة فجمعت مع الأخبار الحقيقية لتعكس تغطية أكثر دقة. ثم قام الفريق بتنظيف النص بإزالة التكرارات وعناوين الويب وعلامات الترقيم الزائدة، وتقسيم الجمل إلى كلمات، وإزالة كلمات الحشو الشائعة جدًا.
تدريس الحواسيب شكل الأخبار المزيفة
بعد إعداد البيانات، ركز المؤلفون على أفضل طريقة لتمثيل النص الأردي للحاسوب. دمجوا مؤشرات بسيطة مثل الكلمات المستخدمة بتكرار، والنبرة العاطفية للغة، ودرجات تكرار المصطلحات مع تقنيتين قويتين لتمثيل الكلمات. الأولى، المسماة GloVe، تعامل كل كلمة كمتجه رقمي ثابت بناءً على مدى تكرار ظهورها مع كلمات أخرى عبر المجموعة بأكملها. والأخرى، المبنية على نماذج على غرار BERT، تنظر إلى كل كلمة في سياق جملتها وتمنحها معنى واعيًا بالسياق. من خلال دمج هذين المنظورين للغة في تمثيل واحد أغنى، يمكن للنظام أن يلتقط كلًا من الأنماط العامة والتحولات اللفظية الدقيقة التي غالبًا ما تميز القصص المزيفة عن الحقيقية.
اختبار نماذج اللغة المتقدمة
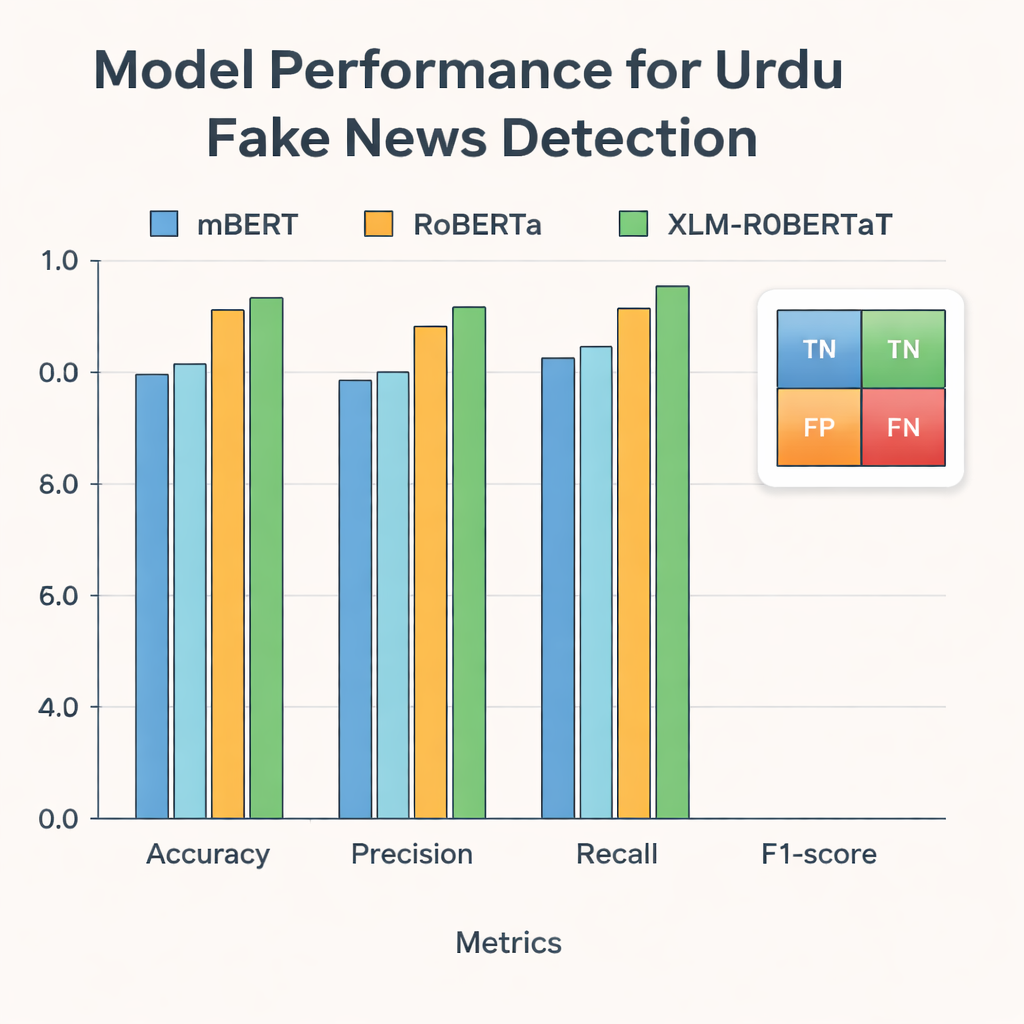
ثم أدخل الباحثون هذه التمثيلات في ثلاثة نماذج تعلم عميق حديثة مُدربة على نصوص بلغات متعددة: mBERT وRoBERTa وXLM-RoBERTa. تم تعديل كل نموذج خصيصًا على مجموعة البيانات الأردية للتنبؤ بما إذا كانت كل مقالة حقيقية أم مزيفة. تم تقييم أدائها باستخدام مقاييس معيارية: الدقة (مدى صحة التنبؤات)، والدقة الإيجابية (مدى صحة العناصر المصنفة كمزيفة)، والاسترجاع (كمية القصص المزيفة التي تم اكتشافها)، ومقياس F1 الذي يوازن بين الدقة والاسترجاع. بينما أدت كل النماذج أداءً قويًا، تميز XLM-RoBERTa المدمج مع تمثيل BERT وGloVe المجمّع، حيث صنف بشكل صحيح حوالي 96 بالمئة من مقالات الاختبار وحقق مقياس F1 بقيمة 0.956 — أفضل من أنظمة سابقة للكشف عن الأخبار المزيفة بالأردية التي استخدمت مجموعات بيانات أصغر أو طرقًا أبسط.
ماذا يعني هذا لقرَّاء العامة
بالنسبة لغير المتخصصين، الرسالة واضحة: مع وجود بيانات أردية عالية الجودة وبالكم الكافي والنوع الصحيح من الذكاء الاصطناعي، أصبح من الممكن الآن بناء أدوات تميّز تلقائيًا القصص المحتملة الكذب بدرجة موثوقية عالية. تُظهر الدراسة أن تمثيلات اللغة الأغنى والنماذج متعددة اللغات تمنح الحواسيب فهمًا أفضل لكيف تُكتب الأردية فعلًا في مناطق ومواضيع مختلفة. رغم أن العمل الحالي يركز على النص فقط ولم يحلل بعد الصور أو سلوكيات التواصل الاجتماعي، فإنه يؤسس قاعدة قوية لأنظمة مستقبلية قد تعمل عبر اللغات وأنواع الوسائط. عمليًا، تقرب هذه الأبحاث باكستان خطوة إلى ملحقات المتصفح ولوحات معلومات غرف الأخبار أو فلاتر وسائل التواصل الاجتماعي التي تساعد الناس على التمييز بين الحقيقة والخيال باللغة التي يستخدمونها يوميًا.
الاستشهاد: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
الكلمات المفتاحية: كشف الأخبار المزيفة, اللغة الأردية, التعلم العميق, BERT و GloVe, المعلومات المضللة عبر الإنترنت