Clear Sky Science · ar
تعزيز تقدير العمق بعيد المدى عبر ترميز هجين من CNN-ترانسفورمر ودمج دلالي عابر للأبعاد
رؤية العمق بعين واحدة
غالباً ما تعتمد الروبوتات الحديثة والسيارات ذاتية القيادة والطائرات بدون طيار على مجسّات ثلاثية الأبعاد باهظة الثمن لمعرفة المسافات. تُظهر هذه الدراسة كيف يمكن دفع إمكانيات كاميرات الألوان العادية، مثل تلك في الهواتف الذكية، إلى مدى أبعد بكثير: يصمم المؤلفون طريقة جديدة ليمكن للحاسب استنتاج العمق من صورة واحدة فقط، ويركزون على أصعب جزء في المشهد لتحقيق الدقة—المسافات البعيدة، حيث تكون العقبات صغيرة وضبابية وسهلة الأخطاء في التقدير.
لماذا يصعب تقدير الأشياء البعيدة
تقدير العمق من صورة واحدة، المعروف بتقدير العمق أحادي العين، هو نوع من الخدعة البصرية. الأجسام القريبة تغطي الكثير من البيكسلات ولها نُسج واضحة، لذا فإن الشبكات العصبية الحالية تعمل جيداً على المدى القصير والمتوسط. لكن في المسافات البعيدة، تتقلص السيارات إلى بضعة بيكسلات وتذوب خطوط الطريق في الضباب. الشبكات التفافيه التقليدية جيدة في ملاحظة التفاصيل المحلية الدقيقة لكنها تواجه صعوبة في استيعاب الصورة الكاملة للشارع. نماذج الترانسفورمر الأحدث ترى السياق العام جيداً، لكنها أقل حساسية للحواف والنُسج الدقيقة. ونتيجة لذلك، كثيراً ما تتعثر كلتا العائلتين من الأساليب تحديداً في الموضع الذي تحتاجه الملاحة الآمنة إلى تقديرات موثوقة: في المسافات الطويلة.
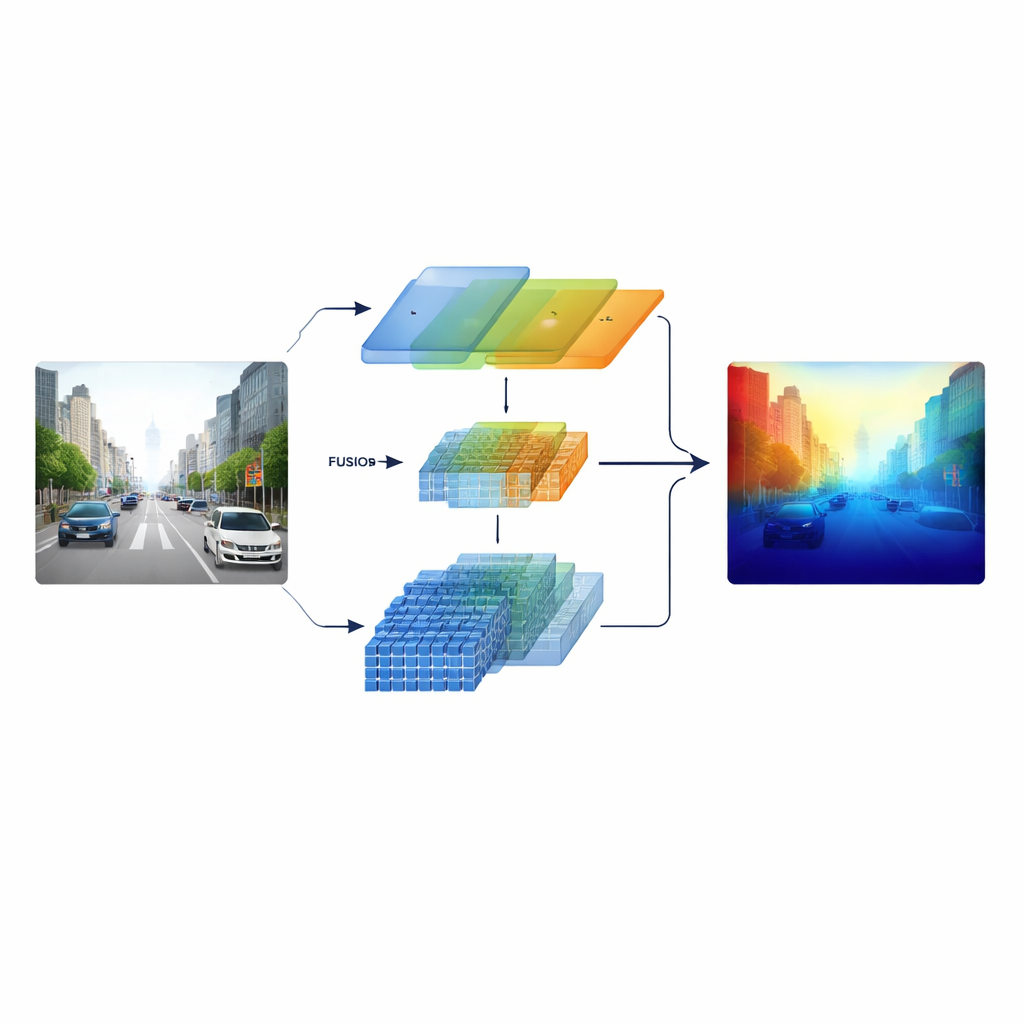
مزج طريقتين للرؤية
يتعامل الباحثون مع هذا التحدي ببناء مُشفّر «غير متناظر» يشغّل نوعين مختلفين من المعالجة البصرية بالتوازي. أحد الفروع يعتمد على شبكة تلافيفية كلاسيكية بأسلوب ResNet متخصصة في الأنماط المحلية الواضحة مثل علامات المسار والأعمدة وحواف الأشياء. الفرع الآخر يستخدم Swin Transformer، المصمم لالتقاط الاتصالات طويلة المدى عبر الصورة، مثل تخطيط ممر الطريق أو أفق المباني البعيدة. بدلاً من دمج هذين المنظورين فقط في النهاية، يحتفظ النظام بميزات متعددة المقاييس من كلا الفرعين ويغذيها في مرحلة اندماج مصممة بعناية، بحيث تُثري البنية الدقيقة والسياق العريض بعضهما بعضاً طوال العملية.
عبور القنوات والمكان والمقياس
في صميم النموذج توجد وحدة دمج دلالي عابرة للأبعاد تعمل مثل غرفة اجتماع ذكية لتدفقات المعلومات الاثنين. أولاً، تقرر أي القنوات—أنواع مختلفة من الأنماط البصرية المتعلمة—تستحق اهتماماً أكبر، موازنة الإشارات بين النُسج التفصيلية والإشارات الدلالية عالية المستوى. بعد ذلك، تنظر بشكل منفصل على الاتجاهين الأفقي والعمودي، وهما مهمان بشكل خاص في المشاهد المليئة بالطرق والمباني والأشجار، لتسليط الضوء على البنى الهامة التي تمتد عبر الصورة. أخيراً، تخلط بين الميزات السطحية الغنية بالتفاصيل وتلك الأعمق والأكثر تجريدًا عبر عدة مقاييس. خطوة وزن قابلة للتعلّم تتيح للشبكة أن تقرر مدى الاعتماد على كل فرع لكل منطقة، بحيث لا تُغرق الأشياء الصغيرة البعيدة في مشاهد القرب.
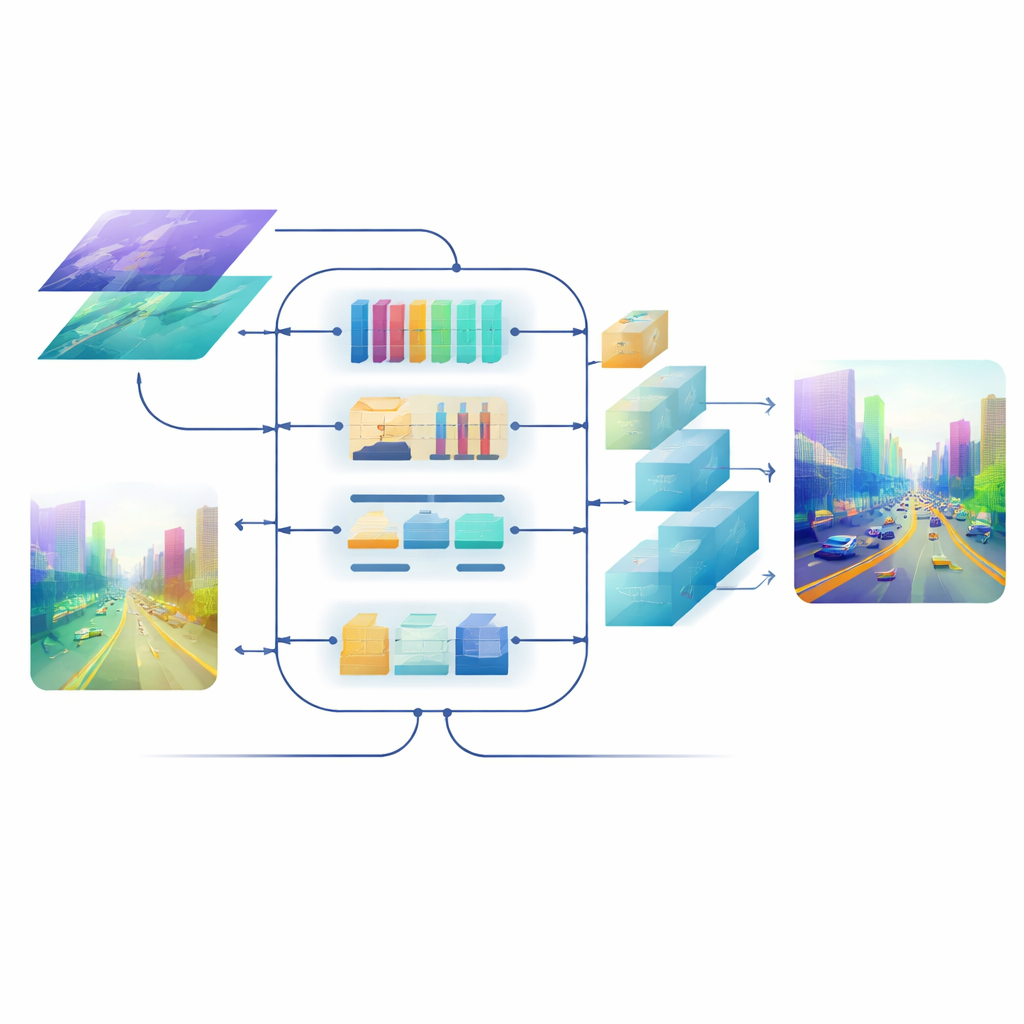
تحسين الصورة النهائية
حتى مع ميزات مدمجة جيدة، قد يؤدي تحويلها مرة أخرى إلى خريطة عمق كاملة الدقة إلى تمويه الحواف وفقدان الهياكل الرفيعة. لتجنّب ذلك، يصمم الفريق مفكك تشفير يدفعه الانتباه. تستخدم كتل التكبير فيه التلافيف الخفيفة العميقة (depth-wise convolutions) لتكبير الخريطة دون فقدان السياق، وآلية انتباه ذاتي متعددة المقاييس تجمع قنوات الميزات بحيث يمكن حساب الانتباه بكفاءة. تُنقح هذه الخطوة توقعات العمق عند كل مقياس مع الحفاظ على ضوابط الحساب. النتيجة هي حقل عمق ناعم ومتسق حيث تبقى حدود الأشياء—مثل محيط راكب دراجة بعيد أو درجات سرير طابقين—حادّة.
مدى فعاليته في العالم الحقيقي
اختُبر الأسلوب على عدة مجموعات بيانات معيارية. على KITTI، مجموعة كبيرة من مشاهد القيادة، يحقق النموذج دقة متقدمة على معظم المقاييس الشائعة، والأهم أنه ينتج أدنى خطأ في المناطق المعيّنة طويلة المدى. كما يعطي حدود عمق أنظف حول الأشياء مقارنة بالأنظمة المنافسة. على NYU Depth V2، التي تحتوي على مشاهد داخلية، وعلى معيار SUN RGB-D، ينجح نفس النموذج في التعميم، معيداً بناء الأثاث وتخطيطات الغرف في سحب نقاط ثلاثية الأبعاد مقنعة. تظهر دراسات الإقصاء—اختبارات منهجية تزيل أو تستبدل مكونات—أن كل جزء مقترح، من المُشفّر الهجين إلى وحدة الدمج وكتلة انتباه المفكك، يحسّن الأداء بشكل ملحوظ، خصوصاً للمناطق البعيدة منخفضة النُسج.
ماذا يعني هذا لتقنية يومية
ببساطة، يعلّم هذا العمل الشبكة العصبية أن تستخدم كل من عدسة مكبرة وعدسة زاوية واسعة في آن واحد، وأن تدمجهما بحكمة. من خلال موازنة أفضل بين التفاصيل المحلية وفهم المشهد العام، تُحسّن الإطار المقترح بشكل كبير قدرة كاميرا واحدة على تقدير العمق بعيداً في الطريق أو عبر الغرفة. هذا يجعل تزويد الروبوتات والمركبات والطائرات بدون طيار بأجهزة استشعار أرخص أكثر عملية بينما يمنحها إحساساً ثلاثي الأبعاد غنياً بالعالم—وهو خطوة مهمة نحو أنظمة مستقلة أكثر أماناً وكفاءة وبأسعار معقولة.
الاستشهاد: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
الكلمات المفتاحية: تقدير العمق أحادي العين, رؤية حاسوبية, اندماج الترانسفورمر وCNN, القيادة الذاتية, إعادة بناء المشهد ثلاثي الأبعاد