Clear Sky Science · ar
تحسين الدقة المتصلة متعددة النطاقات لصور الاستشعار عن بُعد عبر تعلّم أوزان ميتا
رؤى أوضح من الفضاء
تُشغّل صور الأقمار الصناعية العديد من التطبيقات من تخطيط المدن إلى الاستجابة للكوارث، لكن العديد من الصور أحيانًا تكون ضبابية أكثر مما نرغب بسبب قيود أجهزة التصوير ونقل البيانات. تقدّم هذه الورقة طريقة جديدة لتحويل صور الأقمار الصناعية الضبابية إلى صور أوضح عند أي مستوى تكبير مطلوب، باستخدام استراتيجية تعلّم قادرة على التكيّف مع المظهر الخاص للصور الجوية دون الحاجة لإعادة التدريب في كل حالة.
لماذا تهم صور الأقمار الصناعية الأعلى دقة
تعتبر صور الاستشعار عن بُعد عالية الدقة أساسية لرصد الأشياء الصغيرة، وتتبع التغيرات على الأرض، ورسم خرائط استخدام الأراضي بتفصيل. ومع ذلك، تضطر الأقمار الصناعية الواقعية إلى الموازنة بين الدقة والتكلفة وحجم المستشعر وعرض النطاق، لذا تصل الكثير من الصور بجودة أقل مما يفضله المحلّلون. تقنيات “زيادة الدقة” التقليدية يمكن أن تُحسن الصور لكنها عادةً ما تُدرب لمقياس تكبير ثابت، مثل تكبير مرتين أو أربع مرات بالضبط. هذا يعني أن المشغّلين يحتاجون نماذج منفصلة لكل مستوى تكبير، وهو أمر غير فعّال وغير مرن عند التعامل مع العديد من الأقمار الصناعية والمهام المختلفة.
تجاوز نهج المقاس الواحد يناسب الكل
طوّرت الأبحاث الحديثة تقنيات “الزيادة المستمرة للمقياس” التي تعامل الصورة باعتبارها إشارة ناعمة ويمكنها توليد مخرجات حادة عند أي عامل تكبير بنموذج واحد. بُنيت اختبارات معظم هذه الطرق على صور يومية، ليست على بيانات الأقمار الصناعية. عادةً ما تقرر هذه الأساليب كيفية مزج معلومات البكسل المجاورة باستخدام قواعد هندسية ثابتة—بمعنى آخر، وزن الجيران حسب المسافة. هذا يعمل بشكل جيد نسبيًا للمشاهد الطبيعية مثل الوجوه أو المناظر، لكن صور الأقمار الصناعية تحتوي على مبانٍ كثيفة، وملمس متكرر، وحواف مفاجئة لا تتبع نفس الأنماط. عندما تُطبّق النماذج المدربة على الصور الطبيعية على المشاهد الفضائية، تنهار افتراضاتها ولا تُستعاد التفاصيل مثل أسطح المنازل والطرق والمركبات بدقة.
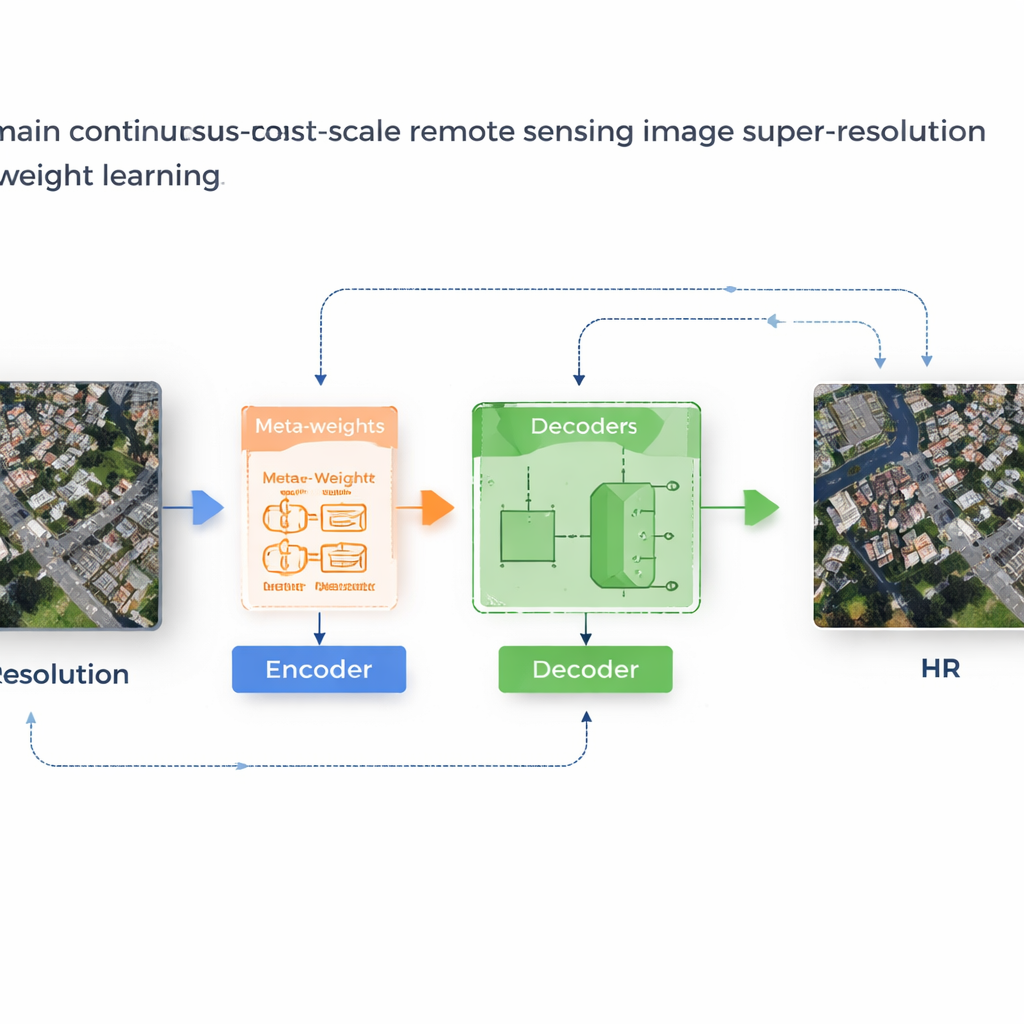
نظام تعلّم يكيّف قواعده بنفسه
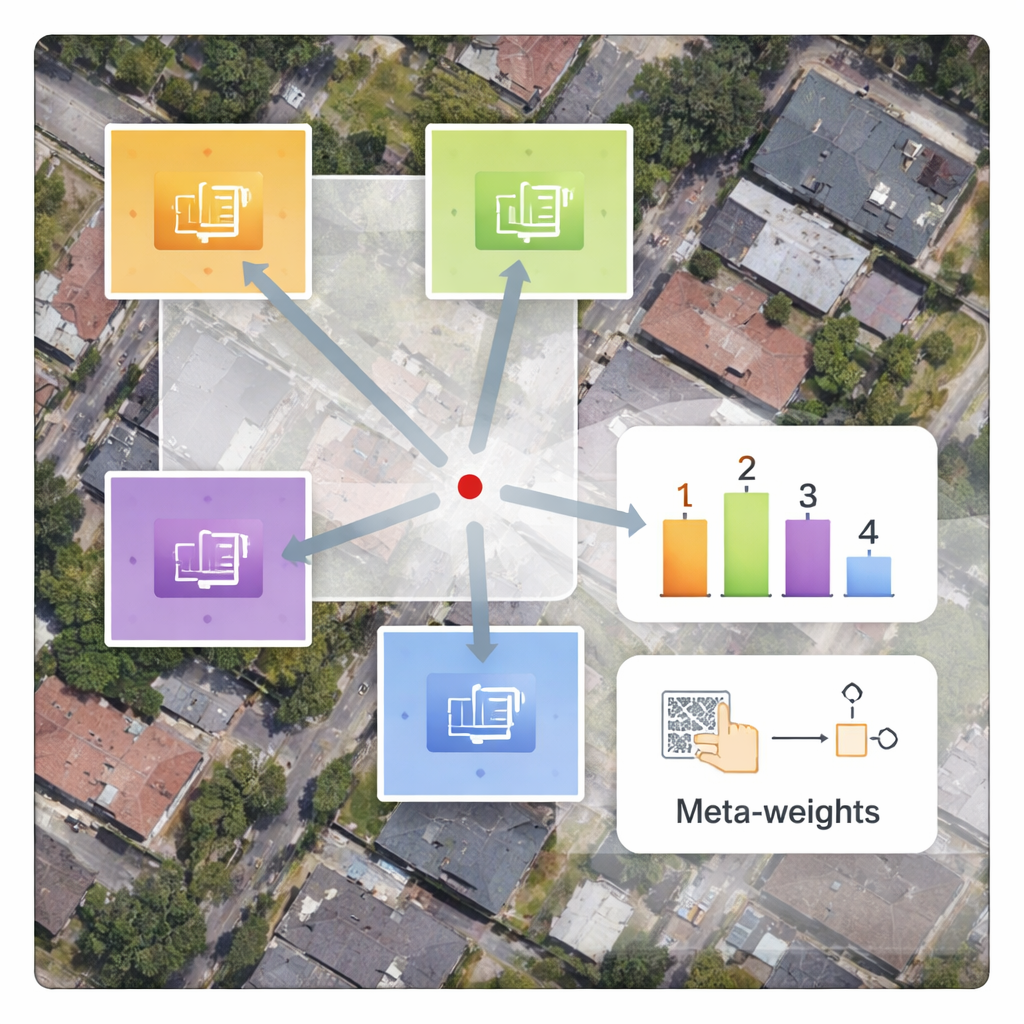
يقترح المؤلفون إطارًا يُدعى MLIN (شبكة عصبية ضمنية قائمة على التعلّم الميتا) لحل مشكلة انتقال النطاق بين المجالات. بدلًا من وضع قواعد يدوية لكيفية دمج ميزات البكسل المجاورة، يتعلّم MLIN هذه القواعد من البيانات. يحتفظ بإطار ترميز قوي للصور تم تدريبه أصلاً على الصور الطبيعية مجمّدًا تمامًا، بحيث يستمر في استخراج أنماط بصرية غنية دون أن تتشوّه بواسطة مجموعات بيانات الأقمار الصناعية الأصغر. فوق هذا، يضيف MLIN «فك تشفير ضمني» جديدًا مزودًا بوحدة تعلّم ميتا. لكل نقطة في الصورة عالية الدقة يريد النموذج إعادة بنائها، تنظر هذه الوحدة إلى الميزات المحيطة ومواقعها الدقيقة ثم تتنبّأ بمجموعة أوزان لينة تخبر المُفكّك بمدى قوة استخدام كل جار. بعبارة أخرى، لم يعد النظام يفترض أن المسافة وحدها هي المهمة؛ بل يتيح للمحتوى المحلي—مثل أنسجة الأسطح أو الحقول أو المياه—أن يشكل عملية إعادة البناء.
من كتل ضبابية إلى هياكل واضحة
من الناحية التقنية، تعمل الطريقة بأخذ عيّنة من الجوار الخفي بحجم 2×2 حول كل موقع مستهدف في الصورة الناتجة. تدمج شبكة ميتا بعد ذلك معلومات حول هذه الميزات وإحداثياتها النسبية وعامل التكبير المطلوب لاختيار أوزان مجموعها واحد. يستخدم المُفكّك هذه الأوزان لمزج التنبؤات من كل جار، منتجًا قيمة لونية نهائية في ذلك الموقع. نظرًا لأن هذا الوزن متعلّم، يستطيع MLIN معاملة المناطق المعقدة—مثل الكتل السكنية الكثيفة والموانئ التي تحتوي سفنًا أو المطارات التي تحتوي مدارج—بشكل مختلف تمامًا عن المناطق السلسة مثل الصحارى أو المحيطات. تُظهر التجارب على مجموعتي بيانات أقمار صناعية مستخدمتين على نطاق واسع (WHU‑RS19 وUCMerced) أن MLIN يوفّر باستمرار درجات جودة رقمية أعلى وتفاصيل أكثر حدة مرئية مقارنة بعدة طرق رائدة للتمدد المستمر في المقياس، عبر مستويات التكبير المألوفة وحتى التكبيرات الشديدة التي تصل إلى عشر مرات.
تدريب أسرع من دون تأخير إضافي
ميزة عملية في التصميم هي أن المفكّك الجديد وشبكة أوزان الميتا فقط هما اللذان يحتاجان إلى التدريب على صور الأقمار الصناعية، بينما يبقى الترميز الكبير ثابتًا. هذا يقلّل كثيرًا من زمن التدريب مقارنة بالطرق التي تعيد تدريب جميع المعلمات من الصفر. وعلى الرغم من أن شبكة الميتا تضيف حسابات إضافية، فإن معالجات الرسوميات الحديثة تتعامل مع هذه العمليات بكفاءة، لذا يبقى زمن معالجة صورة واحدة شبه مطابق للنهج الموجودة. تؤكد دراسات الاستبعاد—اختبارات دقيقة حيث تُزال أو تُبسط أجزاء من النظام—أن الوزن المعتمد على المحتوى هو العنصر الأساسي الذي يحسّن كلًا من حدة الحواف واستمرارية النسيج.
عيون أوضح على الأرض
بعبارات بسيطة، توضح هذه الدراسة كيفية إعادة استخدام نماذج صور قوية مدرّبة على صور يومية وتكييفها بذكاء لعالم صور الأقمار الصناعية المختلف جدًا. من خلال السماح للنظام بتعلّم كيفية موازنة المعلومات من البكسلات المجاورة اعتمادًا على ما هو موجود فعلًا في المشهد، ينتج MLIN صورًا فضائية أوضح وأكثر موثوقية عند أي مستوى تكبير من نموذج واحد. وهذا يعني أدوات أفضل للعلماء والمخطّطين وفرق الاستجابة للطوارئ الذين يعتمدون على مشاهد مفصّلة لكوكبنا، مع الحفاظ على متطلبات الحوسبة والتخزين ضمن حدود معقولة.
الاستشهاد: Zhang, Q., Ma, S., Tang, Y. et al. Cross-domain continuous-scale remote sensing image super-resolution via meta-weight learning. Sci Rep 16, 6073 (2026). https://doi.org/10.1038/s41598-026-36632-w
الكلمات المفتاحية: تحسين دقة الأقمار الصناعية, صور الاستشعار عن بُعد, التعلّم الميتا, تكبير بمقياس عشوائي, تحسين الصور