Clear Sky Science · ar
تحسين متعدد المهام وثبات التقارب مع تعلم الميزات الهرمي للتوجيه الذاتي في التحسين
ذكاء اصطناعي أذكى يستطيع التوفيق بين مهام متعددة في وقت واحد
تعتمد التطبيقات الحديثة بشكل متزايد على ذكاء اصطناعي يحتاج إلى أداء عدة وظائف في آن واحد — مثل فهم الصور والنصوص معًا، دعم القرارات الطبية، أو مساعدة السيارات على إدراك الطريق. لكن عندما يتعلم نموذج ذكاء اصطناعي الكثير من المهارات دفعة واحدة، قد تصبح عملية تدريبه غير مستقرة وقد تتداخل المهارات مع بعضها البعض. تقدم هذه الورقة إطار عمل جديدًا للتعلم العميق، يُسمى البنية الموحدة متعددة المهام ومتعددة العرض (UMDA)، صُمم لتمكين نموذج واحد من التعلم من أنواع بيانات متعددة وحل مهام متعددة دون ارتباك أو فقدان للثبات.
لماذا يكافح الذكاء متعدد المهارات اليوم في كثير من الأحيان
تعاني معظم الأنظمة الحالية التي تتعلم عدة مهام (التعلّم متعدد المهام) أو تجمع عدة أنواع بيانات، مثل الصور والنصوص (التعلّم متعدد العرض)، من ثلاث مشكلات رئيسية. أولًا، يمكن أن تتصارع المهام المختلفة أثناء التدريب: تحسين الأداء في مهمة قد يضر بهدوء بمهمة أخرى، وهي مشكلة تعرف بالنقل السلبي. ثانيًا، الجمع أو المتوسط البسيط للمعلومات من مصادر بيانات مختلفة غالبًا ما يفقد العلاقات الدقيقة والمهمة بينها. ثالثًا، قد يصبح سير التدريب نفسه هشا، مع تقلبات كبيرة في اتجاه تحديثات معلمات النموذج. هذه المشكلات خطيرة بشكل خاص في بيئات العالم الحقيقي مثل التشخيص الطبي أو التفتيش الصناعي، حيث تكون البيانات معقدة ويجب أن تكون القرارات موثوقة.
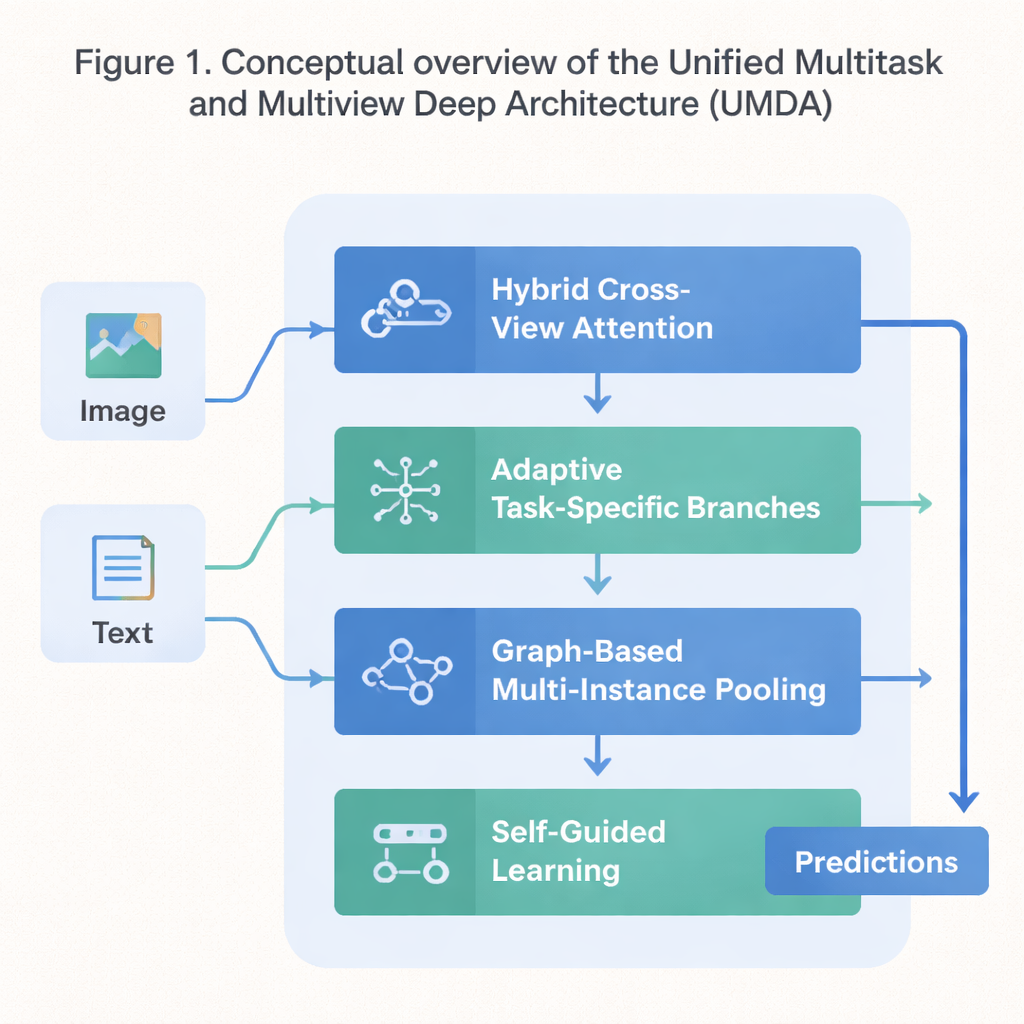
مخطط رباعي الأجزاء للتعلم التعاوني
يتعامل UMDA مع هذه النقائص عن طريق تقسيم عملية التعلم إلى أربعة أجزاء مترابطة تشارك المعلومات بطريقة مُحكَمة. الجزء الأول، المسمى الانتباه الهجين عبر العروض (Hybrid Cross‑View Attention)، ينظر إلى عروض مختلفة لذات البيانات — مثل النصوص والصور التي تصف فيلمًا — ويتعلم أي عرض يجب أن يؤثر في الآخر في كل خطوة. يستخدم أدوات رياضية تشجع النموذج على تجنب الاعتماد المفرط على عرض واحد، والحفاظ على تميّز كل عرض، وفي الوقت نفسه الحفاظ على توافق عام بينها. ببساطة، يعلّم النموذج أن يستمع إلى جميع "حواسه" دون أن يسمح لواحدة منها بأن تطغى على الباقي.
الحفاظ على تميز المهام مع بقاء التعاون
الجزء الثاني، التفرع التكيفي الخاص بكل مهمة (Adaptive Task‑Specific Branching)، يفصل المعرفة العامة التي تشترك فيها العديد من المهام عن المعرفة الخاصة التي تحتاجها كل مهمة على حدة. بدلًا من إجبار جميع المهام على استخدام نفس الميزات بالضبط، يبني UMDA "فروعًا" منفصلة لكل مهمة يمكنها مع ذلك التواصل فيما بينها عبر وصلات موزونة بعناية. تدفع مصطلحات عقابية إضافية في دالة الهدف التدريبي هذه الفروع لأن تكون مختلفة بما يكفي لتتخصص، ولكن ليست مختلفة لدرجة أن تنفصل وتتوقف عن التعاون. هذا التوازن يساعد في تقليل التداخل الضار بين المهام مع السماح لها بالاستفادة من ما يتعلمه الآخرون.
رؤية البنية في مجموعات الأمثلة
تأتي العديد من مجموعات البيانات الحقيقية كمجموعات من العناصر المرتبطة — على سبيل المثال، عدة رقع صورة من شريحة طبية واحدة أو العديد من إطارات الفيديو. الجزء الثالث من UMDA، المسمى التجميع متعدد الأمثلة المعتمد على الرسم (Graph‑Based Multi‑Instance Pooling)، يصوّر صراحة العلاقات بين هذه العناصر بمعاملتها كعقد في شبكة. يربط العناصر المتشابهة، ويسمح بتدفق المعلومات عبر هذه الروابط، ثم يلخص المجموعة بأكملها في تمثيل واحد مضغوط. تدفع قيود تنظيمية إضافية العناصر القريبة إلى الاتفاق مع بعضها مع الحفاظ على قدر كافٍ من التنوع، مما يسمح للنموذج بالتقاط أنماط بنيوية قد يفوّتها المتوسط البسيط.
تدريب ذو ضبط ذاتي من أجل تقدم ثابت
الجزء الأخير، التعلم الموجه ذاتيًا (Self‑Guided Learning)، يركز على كيفية تدريب النموذج بدلاً من بنيته الداخلية. يقيس باستمرار مدى قوة وتشابه إشارات التدريب لكل مهمة ثم يضبط تلقائيًا سرعة التعلم لكل مهمة. كما يقوم بتنعيم وإعادة وزن التدرجات — الإشارات التي تخبر النموذج بكيفية التغير — بحيث تعزز المهام ذات الأهداف المشابهة بعضها البعض، ولا تسمح للمهام التي تسحب في اتجاهات متباينة جدًا بإزعاج استقرار التدريب. عند اختباره على مجموعة بيانات معيارية تدمج ملخصات وأفيشات الأفلام، حقق UMDA دقة متوسطة أعلى من اثني عشر منافسًا متقدمًا، وحافظ على علاقة أكثر تماسكًا بين العروض، وخفّض مقياسًا رئيسيًا لعدم استقرار التدريب بأكثر من النصف.
ماذا يعني هذا لأنظمة الذكاء الاصطناعي في العالم الحقيقي
للغير متخصصين، الرسالة الأساسية هي أن UMDA يقدم طريقة لبناء نماذج ذكاء اصطناعي واحدة قادرة على التعامل مع أنواع بيانات وأهداف متعددة بشكل أكثر موثوقية. من خلال تعليم النموذج متى يشارك المعلومات ومتى يحافظ على فصلها، ومن خلال السماح له بضبط طريقة تعلّمه تلقائيًا، يوفر الإطار توقعات أفضل، وتمثيلات داخلية أكثر تجانسًا، وتدريبًا أكثر سلاسة. يجعل هذا منه لبنة واعدة لأنظمة المستقبل في الطب والقيادة الذاتية وتطبيقات معقدة أخرى حيث يجب على الذكاء الاصطناعي تفسير إشارات متعددة في وقت واحد دون أن يفقد توازنه.
الاستشهاد: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
الكلمات المفتاحية: التعلّم متعدد المهام, الذكاء الاصطناعي متعدد الوسائط, ثبات التعلم العميق, شبكات الانتباه, شبكات الرسوم العصبية