Clear Sky Science · ar
نموذج هجين ResNet50-رؤية محول مع آلية انتباه لتصنيف الصور الجوية
لماذا تهم العيون الأذكى في السماء
الصور الجوية من الطائرات دون طيار والأقمار الصناعية توجه الآن استجابات الكوارث، وتخطيط المدن، والزراعة، وحتى مراقبة المرور. لكن تعليم الحواسيب لفهم هذه المشاهد المعقدة والمزدحمة من الأعلى لا يزال أمراً صعباً. تقدم هذه الدراسة نموذجين جديدين للذكاء الاصطناعي يجمعان طرقاً مختلفة «للنظر» إلى الصور للتعرف على عشرة أنواع من الأشياء في صور الطائرات دون طيار — مثل المباني، والسيارات، والأشجار، والطرق — بدقة أفضل من الطرق السابقة. قد يجعل نهجهما المراقبة الآلية من الجو أسرع وأكثر موثوقية وأسهل نشرًا في بيئات العالم الحقيقي.
تحديات النظر إلى العالم من الأعلى
تختلف الصور الجوية عن الصور اليومية التي نلتقطها بهواتفنا. تكون الأشياء أصغر، وقد تظهر بزوايا غريبة، وغالبًا ما تكون متقاربة. قد يصعب رؤية سيارة نصف مخفية بشجرة، أو ممر ضيق للمشاة، أو أكوام من الحطام بعد انزلاق أرضي حتى على البشر. ومع ذلك، تعتمد الحكومات وفرق الطوارئ والهيئات البيئية بشكل متزايد على مشاهد الطائرات دون طيار والأقمار الصناعية لتتبع الفيضانات وحرائق الغابات ونمو المدن وأضرار البنى التحتية. مع وجود آلاف الأقمار الصناعية في المدار وازدهار سوق التصوير الجوي، ينمو حجم البيانات بسرعة تفوق قدرة الناس على الفحص اليدوي، مما يدفع للحاجة إلى تصنيف آلي أكثر دقة وكفاءة.
مزيج طريقتين لتعلم الآلات الرؤية
تعتمد أغلب أنظمة التعرف على الصور الناجحة اليوم على التعلّم العميق. إحدى العائلات، الشبكات العصبية الالتفافية، تتفوق في التقاط الأنماط المحلية مثل الحواف والأنسجة والأشكال الصغيرة. والأخرى، الأحدث، المسماة محولات الرؤية، تعامل الصورة كسلسلة من الرقع وتتفوق في التقاط العلاقات بعيدة المدى — على سبيل المثال كيف تتصل طريق ومجموعة من الأسطح وحقل مفتوح مجاور في مشهد واحد. يجمع هذا العمل بين الاثنين: نموذج التلافيف المعروف ResNet-50 ومحول الرؤية. كل منهما يعالج نفس الصورة الجوية ويستخرج مجموعته الرقمية من الميزات — ملخصات مدمجة لما تعلمه الشبكة عن المشهد. ثم تُدمج هاتان السيلتان من المعلومات وتُمرّران إلى وحدة «الانتباه» التي تتعلم أي الميزات هي الأهم للتمييز بين الفئات العشر المستهدفة.
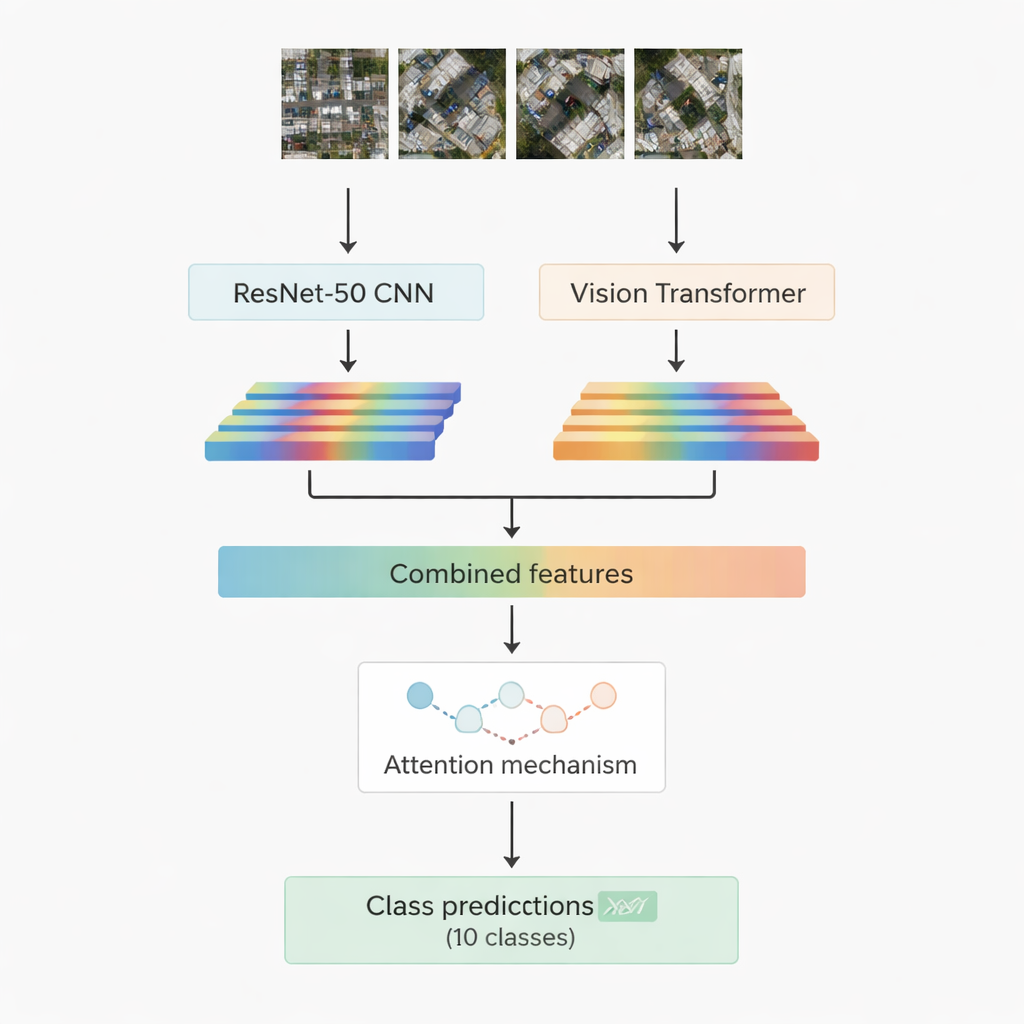
استراتيجيتان للانتباه لتركيز ما يهم
يصمم الباحثون ويختبرون نسختين من النظام الهجين. في الأولى، يدمجون ببساطة ميزات ResNet-50 والمحولة ويغذونها في وحدة انتباه متعددة الرؤوس. يمكن تصور هذه الآلية كأنها العديد من الكشافات الصغيرة التي ينظر كل منها إلى الميزات من زاوية مختلفة قليلاً ثم تدمج نتائجها. في النسخة الثانية، يستخدمون الانتباه المتقاطع: تعمل ميزات الشبكة الالتفافية كاستعلام يطلب من ميزات المحول أين تركز النظر، مما يسمح لأحد التيارين بتوجيه الآخر. في كلتا الحالتين، يمر ناتج الانتباه عبر طبقات قياسية تقوم في النهاية بتعيين رقعة الصورة إلى إحدى الفئات العشر، بما في ذلك المباني، والسيارات، والحطام، وممرات المشاة، والطرق المعدنية، والحقول المفتوحة، والظلال، والدبابات، والأشجار، والأسطح.
الاختبار على صور طائرات دون طيار من العالم الحقيقي
لتقدير مدى كفاءة نماذجهم، يستخدم المؤلفون مجموعة بيانات عامة من ولاية سيكيم الهندية، جمعتها طائرة دون طيار تحلق على ارتفاع يتراوح بين 60 إلى 120 متراً فوق الأرض. تغطي البيانات أنهاراً وغابات وتلالاً ومناطق مبنية، ومقسمة إلى رقع صغيرة بحيث تقع كل صورة في إحدى الفئات العشر. المجموعة متوازنة، مع عدد متساوٍ من صور التدريب والاختبار لكل فئة، مما يجعلها حقل اختبار عادل. يدرب الباحثون كلا النموذجين الهجينين تحت ظروف متطابقة ثم يقارنون أدائهما باستخدام مقاييس مستخدمة على نطاق واسع: الدقة، والإيجابية التنبؤية، والاستدعاء، ومقياس F1، ومصفوفات الالتباس، ومنحنيات ROC. كما يقارنون نتائجهم مع عدة شبكات معروفة وطرق أحدث قائمة على المحولات من الأدبيات الحديثة.

تصنيف أدق وإمكانات عملية في العالم الحقيقي
تفوقت النماذج الهجينة على الأنظمة السابقة في مجموعة البيانات هذه، حيث بلغت الدقة الإجمالية 95.52% و95.80%، مع تقدم طفيف لإصدار الانتباه متعدد الرؤوس. يظل أداؤها قوياً ومستقراً عبر جميع الأنواع العشر من الأشياء، وتُظهر التحليلات التفصيلية أن حتى الفئات الأضعف تُعرف بمعدلات عالية. هذا يشير إلى أن مزج الشبكات الالتفافية ومحولات الرؤية وآليات الانتباه هو وصفة قوية لفهم المشاهد الجوية المعقدة. للمطلع العام، الخلاصة أن الحواسيب أصبحت أفضل بكثير في الإجابة على أسئلة مثل «أين الطرق؟» أو «أي الرقع تظهر حطاماً أو مبانٍ؟» في مجموعات كبيرة من صور الطائرات دون طيار. مع تحسين هذه النماذج وتطبيقها على مجموعات بيانات جديدة، يمكن أن تدعم استجابات كوارث أكثر ذكاءً، ومراقبة بيئية، وخدمات المدن الذكية التي تعتمد على تفسير سريع وموثوق للصور من الأعلى.
الاستشهاد: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
الكلمات المفتاحية: تصنيف الصور الجوية, صور الطائرات بدون طيار, التعلّم العميق, رؤية المحول, الاستشعار عن بعد