Clear Sky Science · ar
طريقة لتوضيح الكيانات في النصوص القصيرة تعتمد على نموذج BERT وخوارزمية أقصر مسار
لماذا يهم تمييز الأسماء المربكة
نبحث ونمرر وندردش يومياً باستخدام مقاطع نصية قصيرة وغالباً فوضوية—تغريدات، استعلامات بحث، رسائل دردشة. تمتلئ هذه المقاطع بأسماء أشخاص وأماكن وشركات وأشياء يمكن أن تحمل أكثر من معنى، مثل «Apple» الفاكهة أو «Apple» الشركة. على الحواسيب أن تخمن المعنى المقصود، وعندما تخطئ التخمينات تصبح نتائج البحث والتوصيات والخدمات عبر الإنترنت أقل فائدة. تقدم هذه الورقة طريقة جديدة لمساعدة الآلات على تفسير الأسماء الغامضة بشكل صحيح في النصوص القصيرة، خاصة في وسائل التواصل والبحث الصينية، من خلال دمج نماذج لغوية متقدمة مع خوارزمية رسومية ذكية.
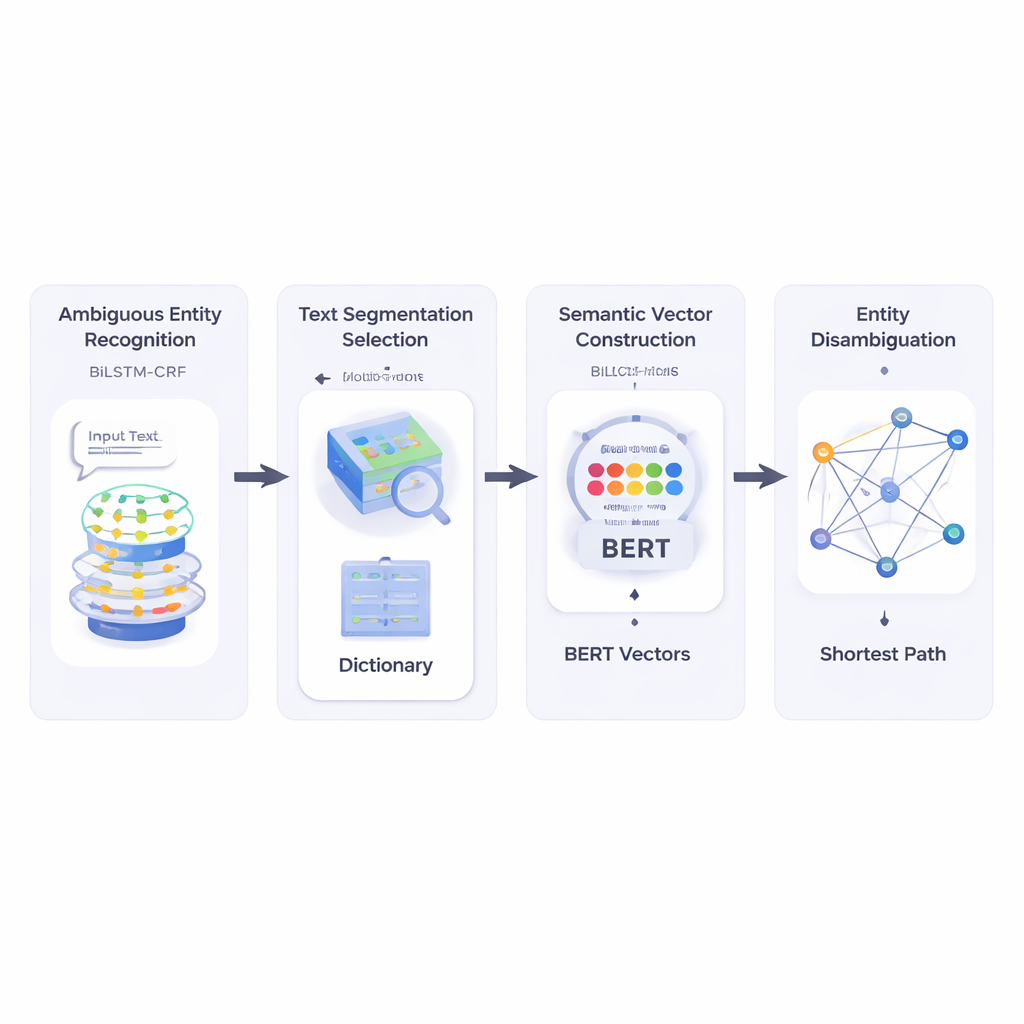
من نصوص قصيرة فوضوية إلى أهداف واضحة
النصوص القصيرة صعبة الفهم بالنسبة للحواسيب بشكل مفاجئ. على عكس المقالات الطويلة، تحتوي سياقاً ضئيلاً وتزخر بالعامية والاختصارات والجمل الناقصة. حاولت الطرق التقليدية مطابقة اسم في النص مع إدخالات في قاعدة معرفة، أو استخدام قواعد محبوكة يدوياً ونماذج تعلم آلي أبسط. كثيراً ما تعامل هذه المناهج كل كلمة كأن لها معنى واحداً ثابتاً، وهذا يفشل تماماً عندما تمثل الكلمة عنوان وظيفة أو شركة أو أغنية اعتماداً على السياق. النتيجة هي ارتباك متكرر بشأن الكيان الواقعي الذي تشير إليه كلمة في تغريدة أو استعلام.
تعليم النظام تمييز الأسماء الغامضة
يبني المؤلفون أولاً نظاماً يقرأ النص القصير ويحدد أي الأجزاء أسماء كيان وأيها قد تكون غامضة. يستخدمون تجميعة شبكية عصبية تسمى BiLSTM‑CRF، وهي جيدة في وسم تسلسلات الكلمات من خلال النظر إلى السياق على الجانبين الأيسر والأيمن. بمجرد وسم الكيانات المحتملة، يستشير النظام موردًا معجميًا كبيرًا يسمى HowNet. إذا سرد HowNet عدة معانٍ لكلمة، تُعلَم هذه الكلمة كغامضة؛ أما إذا كان هناك معنى واحد فقط فتُعتبر الكلمة واضحة بالفعل. تمنح هذه الخطوة النظام قائمة مركزة بالأسماء التي تحتاج فعلاً إلى توضيح.
تحويل المعاني إلى نقاط في الفضاء
بعد ذلك، تكسر الطريقة النص القصير إلى مقاطع كلمات مرشحة وتختار أفضل تقسيم عن طريق التحقق من مدى توافق كل اقتطاع ممكن، من حيث المعنى، مع كلمات مرجعية مفهومة بوضوح في نفس الجملة. لقياس ذلك، يعتمد المؤلفون على BERT، وهو نموذج لغوي قوي مدرّب مسبقاً ينتج «متجهًا دلاليًا» عدديًا لكل استخدام كلمة، يعكس معناها المعتمد على السياق. بحساب تشابه جيب التمام بين هذه المتجهات، يجد النظام التقسيم الذي تكون قطعه أكثر توافقًا دلالياً مع المصطلحات المرجعية غير الغامضة. يتيح هذا للنموذج تمثيل كل معنى محتمل لكل كلمة كنقطة في فضاء متعدد الأبعاد.
إيجاد أقصر مسار إلى المعنى الصحيح
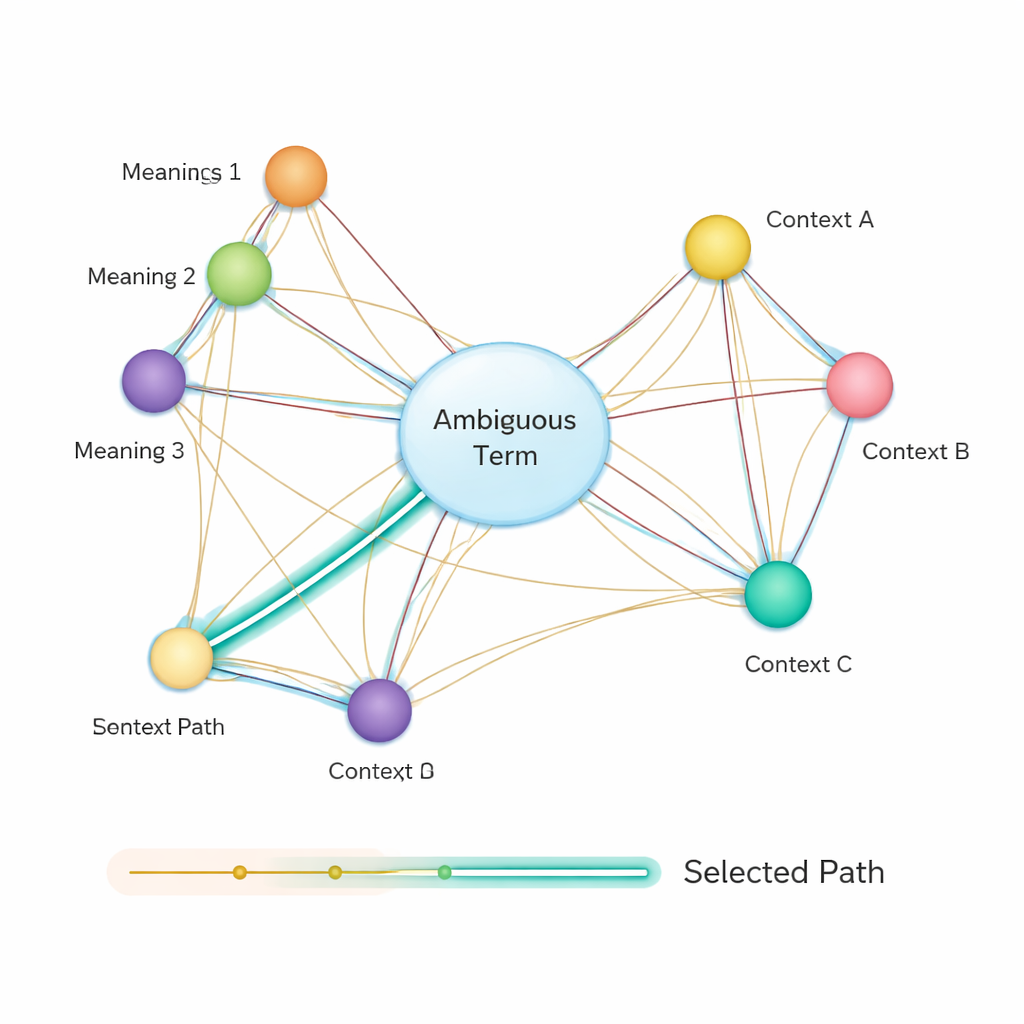
بعد ذلك، يبني الأسلوب شبكة دلالية: رسم حيث يمثل كل معنى محتمل لكل مصطلح عقدة، وتربط الحواف المعاني التي قد تترافق في نفس الجملة. تستند قوة كل حافة إلى مدى تشابه المعاني، مجدداً باستخدام متجهات مستمدة من BERT. لتحديد أي معنى لكلمة غامضة يناسب الجملة أفضل، يطبق المؤلفون خوارزمية كلاسيكية تعرف بخوارزمية أقصر مسار ديكسترا. بديهياً، يبحث النظام عن المسار عبر هذا الرسم المعنوي الذي يحافظ على «المسافة» الدلالية الإجمالية عند الحد الأدنى الممكن. المسار المختار يتوافق مع تفسير متسق لجميع المصطلحات، والمعنى المختار للكيان الغامض الموجود على هذا المسار يُعتمد كنتيجة نهائية.
ما مدى تحسن الأداء؟
اختبر الباحثون طريقتهم على مجموعة بيانات صينية عامة من معيار CLUE، الذي يحاكي سيناريوهات نصية قصيرة حقيقية مثل منشورات وسائل التواصل والاستعلامات. قارنوا أربع مقاربات: نسخ تستخدم تضمينات Word2Vec التقليدية، ونموذج اللغة ELMo، ونظام قائم على BERT دون خطوة أقصر مسار، وأنبوبهم الكامل BiLSTM‑CRF‑BERT‑SPA. عبر آلاف النصوص، حسّن أسلوبهم الكامل الدقة والاسترجاع ودرجة F1 بنحو ربع في المتوسط مقارنةً بالبدائل. عملياً، كان النظام أفضل في اكتشاف الكيانات الصحيحة وأيضاً أكثر اتساقاً عبر أحجام بيانات مختلفة.
ماذا يعني هذا لتقنيات الاستخدام اليومي
بالنسبة لغير المتخصصين، الخلاصة واضحة: من خلال دمج نموذج فهم لغوي قوي (BERT) مع بحث رسومي لأقصر مسار، يمنح المؤلفون الحواسيب طريقة أكثر موثوقية لتحديد ما تشير إليه اسم غامض في نصوص قصيرة وصاخبة. يمكن أن يجعل هذا محركات البحث أذكى، ويساعد المنصات الاجتماعية على فهم المشاركات بشكل أفضل، ويحسن الأدوات اللاحقة مثل أنظمة التوصية والرسوم المعرفية. رغم أن الطريقة موجهة حالياً نحو اللغة الصينية ولا تزال بحاجة إلى تحسينات كفاءة، إلا أنها توضح كيف يمكن لمزج الذكاء الحديث مع خوارزميات كلاسيكية أن يقلل بحدة من الالتباس في تفسير الآلات للغتنا اليومية.
الاستشهاد: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
الكلمات المفتاحية: توضيح الكيانات, نص قصير, BERT, رسم معرفي, معالجة اللغة الطبيعية