Clear Sky Science · ar
إطار تعلم معزز للاختبارات التكيفية المحوسبة باستخدام نهج ذراع القمار المتعدد
اختبارات أذكى للفصل الدراسي الرقمي
أي شخص جلس لإجراء اختبار طويل موحد يعرف كم يمكن أن يكون مملاً وغير عادل. بعض الأسئلة سهلة للغاية، وأخرى مستحيلة، وقد لا يعكس الناتج النهائي حقًا ما تعرفه. تعرض هذه الورقة طريقة جديدة لبناء اختبارات محوسبة تتكيف في الوقت الفعلي مع إجابات كل شخص. بالاستعانة بأفكار من الذكاء الاصطناعي الحديث، يهدف المؤلفون إلى جعل الاختبارات أقصر وأكثر دقة وأكثر توافقًا مع مستوى كل مُختبَر.
لماذا تفشل الاختبارات الثابتة
الاختبارات التقليدية تمنح كل طالب نفس مجموعة الأسئلة. هذا يجعل إعداد الاختبار بسيطًا، لكنه يهدر المعلومات: يمر الطلاب الأقوياء عبر الكثير من البنود السهلة، بينما يُغمر الطلاب الذين يواجهون صعوبة بسرعة. تحاول الاختبارات التكيفية المحوسبة إصلاح ذلك عن طريق اختيار السؤال التالي بناءً على الإجابات السابقة، لكن معظم الأنظمة الحالية لا تزال تعتمد على نماذج إحصائية قديمة وقواعد مصنوعة يدويًا. تواجه هذه الأساليب القديمة صعوبة في التقاط أنماط الإجابة المعقدة وغالبًا ما تعجز عن احتساب الاختلافات الكبيرة بين المتعلمين في بيئات حديثة وعلى نطاق واسع عبر الإنترنت.
إدخال الذكاء الاصطناعي الحديث في الاختبارات
يقترح المؤلفون إطارًا جديدًا يجمع بين التعلّم العميق والتعلّم المعزز لتوجيه الاختبارات التكيفية من البداية إلى النهاية. يعمل النظام في دورات متكررة. أولاً، يحلل شبكة عصبية تلافيفية أحادية البُعد (1D‑CNN) إجابات الشخص الأخيرة، وصعوبة الأسئلة، وإحصاءات موجزة أخرى. من هذا التدفق من البيانات ينتج رقمًا واحدًا يمثل مستوى مهارة الشخص الحالي على مقياس معياري، بطريقة تشبه كيف تصف نظريات الاختبار التقليدية القدرة ولكن يتعلمها النموذج مباشرةً من البيانات. تُدرب هذه الشبكة على التعرف على أنماط دقيقة مثل النجاح المتكرر في الأسئلة الأصعب أو الأخطاء غير المتوقعة في الأسئلة الأسهل. 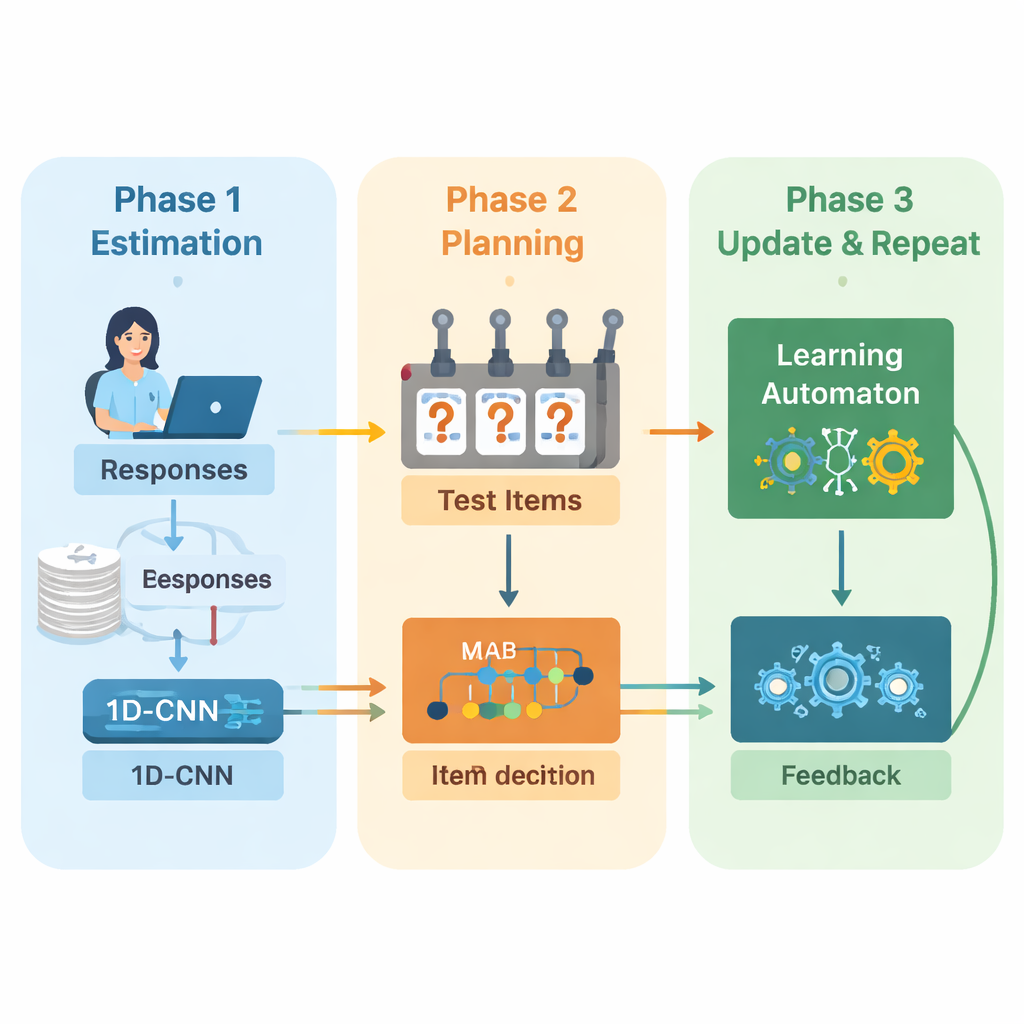
اختيار السؤال التالي المناسب
بمجرد أن يحصل النظام على تقدير محدث للقدرة، عليه أن يقرر ما الذي يسأل عنه بعد ذلك. هنا يستخدم المؤلفون استراتيجية «ذراع القمار المتعدد»، وهي أداة كلاسيكية من نظرية القرار حيث يُعامل كل إجراء ممكن كمسمار يُسحب على آلة قمار. في هذا السياق، كل سؤال في بنك البنود هو ذراع. ينظر الخوارزم إلى الأسئلة التي تتوافق صعوبتها تقريبًا مع تقدير المهارة الحالي ثم يختار تلك المتوقّع أن تكون الأكثر معلوماتية. يوازن بين هدفين: الحصول على مطابقة صعوبة جيدة بحيث لا تكون الإجابات سهلة جدًا ولا صعبة جدًا، وتغطية أكبر عدد ممكن من مجالات المحتوى حتى لا يتجاهل الاختبار مواضيع مهمة. يوجه درجة مكافأة تمزج بين هذين الهدفين عملية الاختيار.
التعلم من قراراته الخاصة
للاستمرار في التحسّن أثناء سير الاختبار، يضيف النظام مكوّنًا تعليميًا آخر يدعى الآلة التعليمية. تراقب هذه الوحدة كيف يتغير تقدير القدرة عبر الجولات وما إذا كانت دقة الشخص تتحسّن أو تتراجع. تُعدّل مجموعة صغيرة من الاحتمالات التي تلخّص ما إذا كان النموذج يتوقع أن ترتفع القدرة أو تبقى كما هي أو تنخفض. ثم تُعاد هذه الاحتمالات كمدخل إضافي إلى الشبكة العصبية في الجولة التالية. بهذه الطريقة لا يتعلم محرك الاختبار عن الطالب فحسب، بل يتعلم أيضًا عن قراراته السابقة—مكافأة الاتجاهات التي أدت إلى تقديرات دقيقة ومعاقبة الاتجاهات التي لم تؤدِ إلى ذلك. 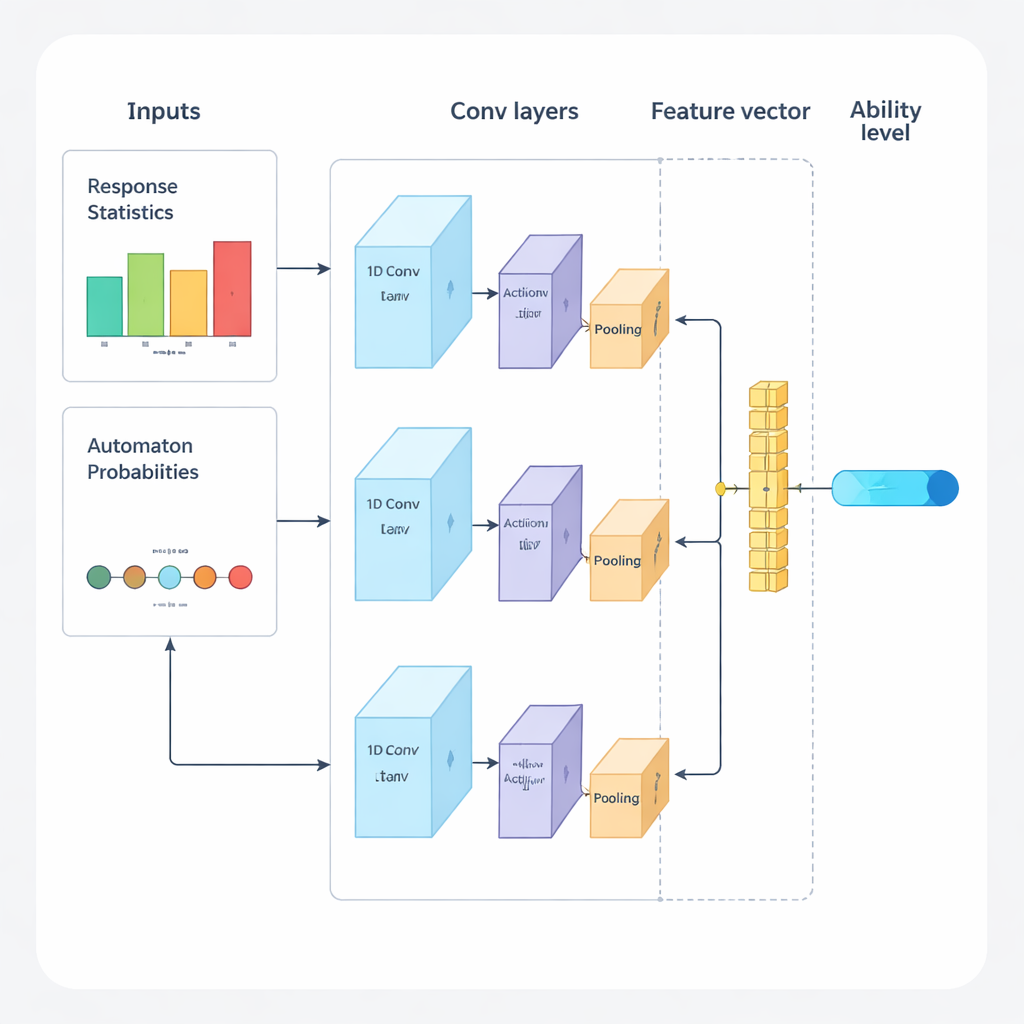
ما مدى فعاليته عمليًا؟
قيّم الباحثون إطارهم باستخدام مجموعة بيانات اختبار كبيرة متعددة اللغات وآلاف المختبرين المحاكين الذين كانت مستويات مهاراتهم الحقيقية معروفة. قارنوا نهجهم مع عدة طرق رائدة للاختبارات التكيفية. عبر مجموعة من مقاييس الخطأ والارتباط، أنتج النظام الجديد تقديرات أكثر دقة للقدرة مع حاجة إلى عدد أقل من الأسئلة. كانت أخطاؤه — المقاسة بإحصاءات شائعة مثل الجذر التربيعي لمتوسط مربع الخطأ والخطأ المتوسط المطلق — أدنى بوضوح من طرق المنافسين. وفي الوقت نفسه وزّع استخدام الأسئلة بصورة أكثر توازنًا عبر بنك البنود، مما خفّض خطر تعرّض بعض الأسئلة للكشف المفرط والتسرّب.
ماذا يعني هذا لامتحانات المستقبل
بمصطلحات يومية، تشير هذه الدراسة إلى أن الاختبارات المحوسبة المستقبلية قد تبدو أشبه بجلسة تدريس مخصّصة أكثر من كونها اختبارًا جامدًا. ستركّز الأسئلة بسرعة على مستوى الصعوبة المناسب لكل شخص، وتستكشف النطاق الكامل للمواضيع المهمة، وتكتمل بمجرد أن يثق النظام في مستواك — وغالبًا بعد بنود أقل من اختبارات اليوم. وعلى الرغم من أن الطريقة لا تزال تعتمد على بيانات تدريب جيدة وقدرات حاسوبية، ولم تُجرّب بعد إلا على مجموعة بيانات واحدة، فإنها تشير إلى جيل جديد من التقييمات الأذكى والأعدل والأكثر كفاءة التي تتكيف بشكل طبيعي مع المتعلمين الأفراد.
الاستشهاد: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
الكلمات المفتاحية: الاختبارات التكيفية المحوسبة, التقويم التعليمي, التعلّم العميق, التعلّم المعزز, ذراع القمار المتعدد