Clear Sky Science · ar
طريقة تخصيص موارد لشبكة الأشياء الإدراكية تعتمد على خوارزمية التعلم المعزز متعددة الوكلاء
لماذا يجب أن تظل بيانات سيارتك «طازجة»
تتبادل السيارات الحديثة باستمرار معلومات عن موقعها وسرعتها ومحيطها مع مركبات أخرى ومعدات على جانب الطريق. لكي تعمل ميزات السلامة ووظائف القيادة الذاتية المستقبلية بشكل جيد، يجب أن تكون هذه المعلومات ليست دقيقة فحسب بل وطازجة أيضاً: إنذار فرملة متأخر بثانية واحدة قد يصبح بلا فائدة. تستكشف هذه الورقة كيفية الحفاظ على حداثة مثل هذه البيانات قدر الإمكان عبر شبكات لاسلكية مزدحمة، باستخدام طريقة تحكم جديدة قائمة على التعلم تتيح للسيارات أن تقرر بنفسها كيف ومتى ترسل البيانات.
طرقات ذكية تشارك موجات الهواء
تدرس الدراسة شبكة طرق مستقبلية حيث تشارك آلاف السيارات المتصلة طيف راديو محدود مع مستخدمين حاليين مثل عملاء الهواتف المحمولة. هذا الإعداد، المسمى إنترنت الأشياء الإدراكي، يفترض أن السيارات «ضيوف مؤدبون»: يمكنها استعارة الترددات فقط عندما لا تزعج المستخدمين الأساسيين. في الوقت نفسه، يجب أن تتواصل المركبات مع بعضها ومع محطات القاعدة بسرعة كافية لدعم تحذيرات التصادم وتنسيق المرور وخدمات الترفيه. موازنة هذه المطالب صعبة لأن السيارات تتحرك بسرعة، والإشارات تتلاشى أثناء انزلاقها بين مباني المدينة، والقنوات المتاحة تتغير من لحظة لأخرى.
قياس الطزاجة، ليس السرعة فقط
غالباً ما يركز تصميم الشبكات التقليدي على زيادة معدل البيانات أو تقليل التأخير المتوسط. لكن بالنسبة لرسائل السيارات الحرجة للسلامة، ما يهم حقاً هو مدى قدم آخر تحديث للحالة عندما يصل إلى المستلم. يستخدم المؤلفون مقياساً يسمى عمر المعلومات، والذي يزيد بمرور الوقت بعد آخر تحديث ناجح ويُعاد ضبطه عندما يصل تحديث جديد. في نموذجهم، ترسل كل زوج من المركبات أجزاءً من البيانات مراراً وتكراراً. إذا كان الرابط اللاسلكي قوياً ومستوى القدرة المختار كافياً، يتم مسح الجزء الحالي بسرعة وينخفض العمر؛ إذا كان الاتصال ضعيفاً أو الطاقة محدودة، تنتقل البيانات المتبقية ويستمر العمر في الارتفاع. الهدف هو اختيار قنوات الراديو ومستويات القدرة بحيث يبقى هذا العمر منخفضاً قدر الإمكان، مع الحفاظ على توفير الطاقة وحماية المستخدمين الأساسيين من التداخل.
تعليم السيارات التعاون بالتجربة والخطأ
نظراً لأن البيئة اللاسلكية تتغير بسرعة وكل سيارة ترى معلومات محلية فقط، يصوغ المؤلفون المشكلة كمهمة تعلم بدلاً من صيغة ثابتة. تعمل كل سيارة كوكيل ذكي يراقب وضعه مراراً: أي القنوات تبدو مشغولة، مدى قوة روابطها الراديوية، مقدار البيانات المتبقي لإرسالها، ومدى قدم آخر تحديث لها. استناداً إلى هذا الرؤية الجزئية، تختار إجراءً يجمع بين خيار متقطع (أي قناة تستخدم، أو ما إذا كانت تبقى صامتة) وخيار مستمر (كمية القدرة الذي تبث بها). بعد التصرف، يقيس النظام مدى طزاجة المعلومات، وكمية الطاقة المستخدمة، وما إذا كان قد تم إزعاج أي من المستخدمين الأساسيين. تتحول هذه الملاحظات إلى إشارة مكافأة توجه الوكلاء، عبر العديد من الحلقات المحاكاة، نحو قرارات مشتركة أفضل.
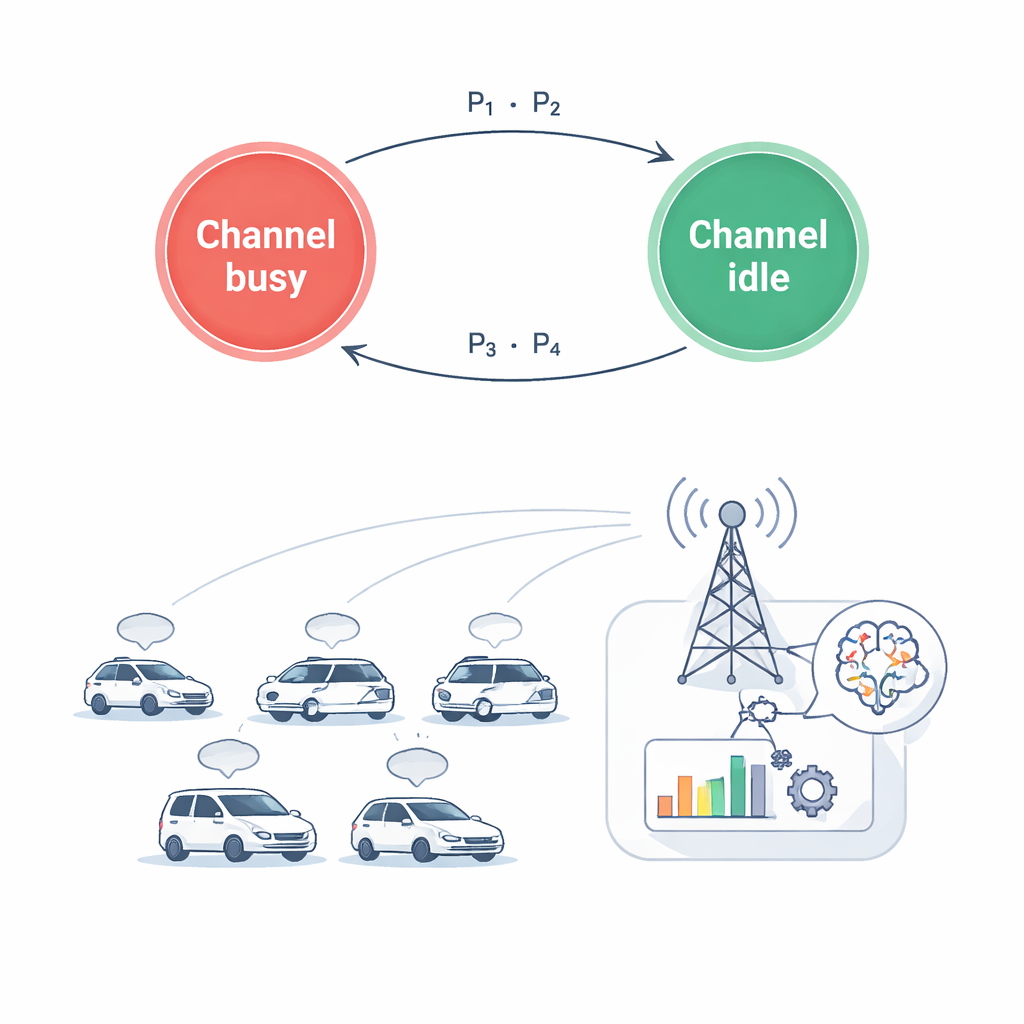
خوارزمية تعلم مصممة للقرارات المختلطة
لتدريب هؤلاء الوكلاء، يطور المؤلفون نسخة محسّنة متعددة الوكلاء من طريقة شائعة تسمى تحسين السياسة التقاربي (Proximal Policy Optimization). متغيرهم، IMAPPO، يستخدم وحدة تدريب مركزية ترى الحالة العالمية وتقيّم مدى جودة الأفعال المجمعة لجميع السيارات، بينما يتعلم كل سيارة قاعدة قرار خاصة يمكنها تطبيقها بنفسها في الوقت الحقيقي. ابتكار رئيسي هو شبكة قرار محدثة قادرة بطبيعتها على التعامل مع كل من خيار تشغيل/إطفاء القنوات والنطاق السلس لمستويات القدرة الممكنة. في محاكاة لطرق مدينة على شكل شبكة، مع وضع السيارات ومحطات القاعدة في مواضع واقعية واحتساب تأثيرات الراديو مثل التلاشي والتداخل، يقارن الأسلوب المقترح بعدة خوارزميات تعلم متطورة وخط أساس عشوائي.
بيانات أكثر طزاجة بطاقة أقل
تُظهر النتائج أن الطريقة الجديدة يمكنها الحفاظ على معلومات أكثر طزاجة بوضوح بينما تستهلك أيضاً طاقة أقل. عبر أعداد مختلفة من المركبات وكميات بيانات مختلفة للإرسال، يقلل IMAPPO متوسط عمر المعلومات بنحو النصف تقريباً مقارنة بالوصول العشوائي البسيط، ويتفوق على طرق تعلم متقدمة أخرى بهوامش معتبرة. في الوقت نفسه، يخفض إجمالي الطاقة المستخدمة بواسطة السيارات، مما يساعد على حفظ عمر البطارية والحد من التداخل مع مستخدمي الطيف الآخرين. للقارئ العام، يعني هذا أن التحكم الأذكى القائم على التعلم في من يتحدث ومتى وبأي قوة على «الطريق» اللاسلكي يمكن أن يجعل المركبات المتصلة والذاتية القيادة أكثر أماناً وكفاءة واحتراماً لموجات الهواء المزدحمة التي يجب أن تشاركها.
الاستشهاد: Wang, R., Shen, Y., Wang, D. et al. A cognitive internet of things resource allocation method based on multi-agent reinforcement learning algorithm. Sci Rep 16, 7756 (2026). https://doi.org/10.1038/s41598-026-36380-x
الكلمات المفتاحية: المركبات المتصلة, مشاركة الطيف اللاسلكي, عمر المعلومات, التعلم المعزز, إنترنت الأشياء