Clear Sky Science · ar
التدريب التبايني الموجَّه بالكائنات للغة والصورة للتعرّف الصفري الهدف
عيون أذكى للسماء والبحر المزدحمين
تعتمد أنظمة الأمن والاستجابة للكوارث الحديثة على كاميرات في السماء وعلى البحر لرصد الطائرات والسفن وغيرها من الأجسام الحرجة. لكن تعليم الحواسيب التمييز بين مقاتلة وطائرة ركاب، أو بين فرقاطة وسفينة شحن، أمر أكثر صعوبة مما يبدو عندما تكون المشاهد مزدحمة، والبيانات نادرة، وتظهر نماذج جديدة من المعدات باستمرار. تقدم هذه الورقة نظام OG‑CLIP، وهو نظام ذكاء اصطناعي جديد مصمَّم للتعرّف على أهداف عسكرية ومدنية لم يُدرَّب عليها صراحةً من قبل، من خلال الجمع بين معرفة واسعة النطاق وتركيز بصري أدق على الأجسام الأكثر أهمية.
لماذا تفشل الذكاءات التقليدية في الاصابة بالهدف
تتعلم معظم أنظمة التعرّف على الصور من مجموعات ضخمة من الصور الموسومة: ترتبط كل صورة بقائمة ثابتة من الفئات، مثل «قطة» أو «سيارة». ينهار هذا الأسلوب في المجالات المتخصِّصة مثل الدفاع والاستشعار عن بُعد، حيث تكون البيانات حساسة، والتوسيم يتطلّب خبراء، وتنوع المعدات هائل. نماذج الرؤية-واللغة الأحدث مثل CLIP تُزاوج الصور بتعليقات نصية قصيرة جُمعت من الويب، مما يمكّنها من التعرّف على مفاهيم جديدة موصوفة بالكلمات. ومع ذلك، في التصوير العسكري لا تزال هذه النماذج تُواجه صعوبات: تكون التعليقات غير محددة غالبًا، والخلفيات مثل السحب والأمواج تهيمن على البكسلات، وميزات النماذج الداخلية ليست مرنة بما يكفي لتعمل بكفاءة على كل شيء من الطائرات الصغيرة بدون طيار إلى الخوادم القوية. يتعامل OG‑CLIP مع هذه المشكلات الثلاث مباشرة.
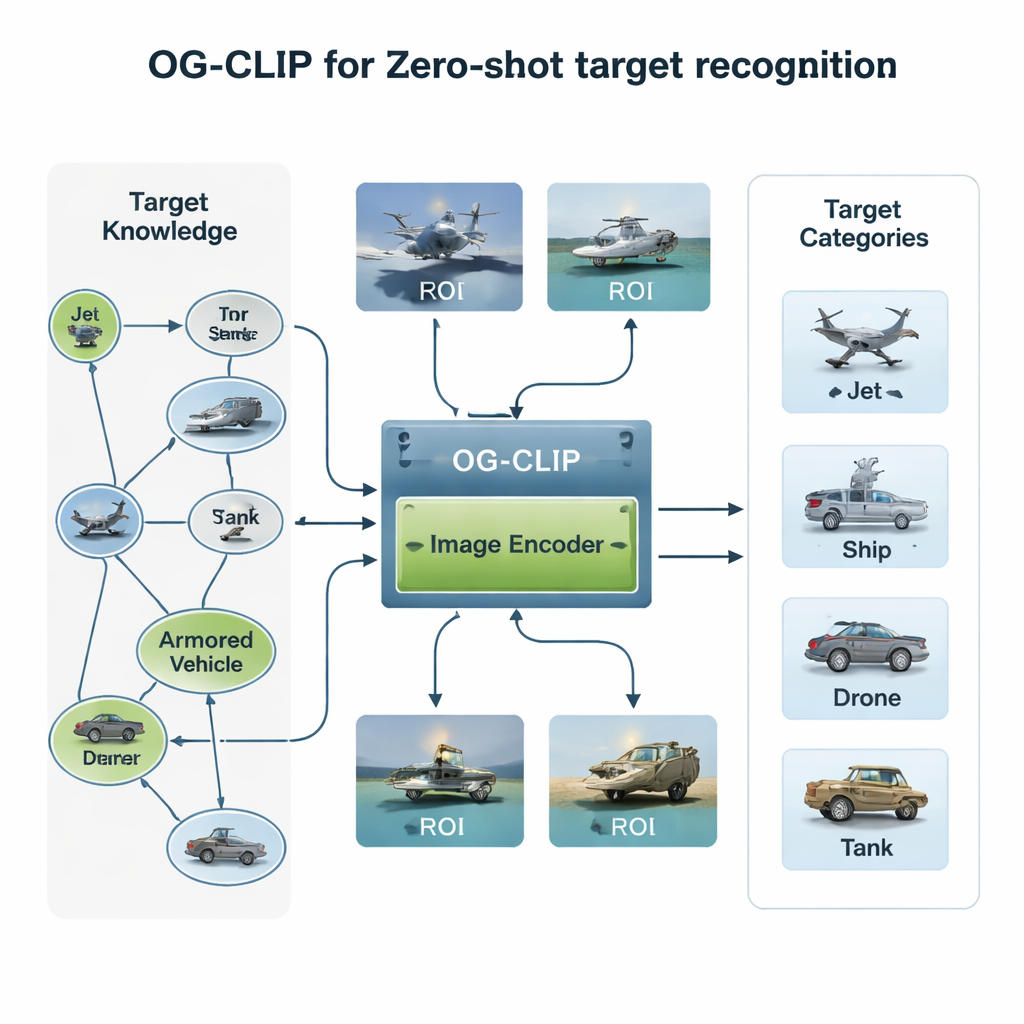
بناء عالم تدريبي غني بالمعرفة
المكوِّن الأول لـ OG‑CLIP هو عالم تدريبي مُهندَس بعناية. جمع المؤلفون قاعدة بيانات تضم 5000 نوع من الأهداف — تتراوح من المقاتلات والقاذفات إلى السفن الحربية والطائرات المدنية — ونظَّموها في رسم بياني معرفي مفصّل. يتضمن كل إدخال حقائق مُهيكلة مثل المدى والوزن وتكوين الأسلحة، مأخوذة من مراجع دفاعية عامة وموسوعات ووثائق فنية. ثم جمعوا نحو مليون صورة باستخدام مجموعات بيانات عامة، وبحث ويب، وأرشيفات داخلية قديمة، وحتى مشاهد محاكة من محركات ألعاب. للحفاظ على موثوقية البيانات، قاموا بتجميع الصور باستخدام نموذج قائم لاكتشاف الشواذ، وتبعوا ذلك بمراجعة خبراء، وفرزوا الوسوم الخاطئة. أخيرًا، استخدموا أدوات متقدمة للرؤية واللغة لتحويل الرسم البياني المعرفي إلى أوصاف طبيعية غنية لكل صورة، بحيث يتعلم النظام ليس فقط «هذه طائرة»، بل «طائرة بمقعد واحد بمقعد واحد ذي جناح منحني لأعلى» أو «قاذفة شبحية ذات شكل جناح طائر».
تعليم النموذج تجاهل الضجيج
الابتكار الثاني يكمن في مكان تركيز النموذج. في العديد من صور الأقمار الصناعية أو الصور الجوية، يحتل السفينة أو الطائرة الفعلية رقعة صغيرة فقط، محاطةً بسماء أو بحر أو تضاريس مشتتة للانتباه. يضيف OG‑CLIP وحدة منطقة الاهتمام (ROI) التي تقلد كيف ينظر الإنسان إلى الكائن الرئيسي بدلًا من الإطار بأكمله. تقوم أداة فصل متقدمة تلقائيًا بتحديد محيط الأجسام المحتملة في الصورة، منتجة أقنعة ناعمة تُبرِز الهدف وتُخفت الخلفية. تُغذى هذه الأقنعة، إلى جانب الصورة الأصلية، إلى العمود البصري للنموذج، بحيث يتركز انتباهه طبيعيًا على السمات المميزة مثل شكل الجناح أو ترتيب السطح أو ظِلّ بدن السفينة. يمكن إضافة هذا التصميم المُلحق إلى الأنظمة القائمة دون إعادة كتابة البنية الأساسية لها، مما يمنحها نظرًا أكثر «توجيهًا بالكائن».

تكييف التفاصيل حسب العتاد
القطعة الثالثة تتناول مسألة عملية لكنها حاسمة: ليست كل الأجهزة قادرة على تحمل نفس مستوى التفاصيل. قد يعالج محطة أرضية للأقمار الصناعية ميزات غنية وذات أبعاد عالية، في حين تحتاج طائرة صغيرة بدون طيار إلى حسابات أسرع وأخف وزنًا. الطرق التقليدية تثبت حجم ميزة واحدًا، أو تدرب عدة نماذج منفصلة لأحجام مختلفة. يستخدم OG‑CLIP بدلًا من ذلك تمثيلًا على طراز «ماترْيوشكا»، يعبّئ المعلومات على مستويات متعددة من التفاصيل في متجه واحد، مثل الدمى المتداخلة. يمكن للنظام اقتطاع أجزاء أقصر أو أطول من هذا المتجه — أوصاف أكثر خشونة أو أكثر دقة لما في الصورة — دون إعادة تدريب. يشجّع آلية وزن كل مستوى على الاحتفاظ بالمعلومات الأكثر فائدة للتصنيف، ويُضيف مصطلح فقد إضافي يدفع المستويات لتظل متسقة دلاليًا مع بعضها البعض.
ما مدى فعاليته في التطبيق العملي؟
لاختبار OG‑CLIP، بنى الباحثون مجموعة تقييم صعبة تضم 99 فئة هدف، بما في ذلك 51 نوعًا من الطائرات العسكرية، و29 نوعًا من السفن الحربية، و19 هدفًا مدنيًا أو مختلطًا. والأهم من ذلك، أن أياً من هذه الفئات لا يظهر في بيانات التدريب، لذا يجب على النظام الاعتماد على فهمه المكتسب للغة والأنماط البصرية — اختبار «صفر إطلاق» (zero‑shot). بالمقارنة مع عدة قواعد أساسية قوية مبنية على CLIP، حسّن OG‑CLIP متوسط الدقة بأكثر من 11 نقطة مئوية، ليصل إلى 84.28 في المئة إجمالًا. أدَّى أداءً جيدًا بشكل خاص في المشاهد المزدحمة والمعقدة وفي التمييزات الدقيقة بين النماذج المماثلة، مثل طرازات المقاتلات المختلفة، حيث منحت وحدة ROI والأوصاف الغنية بالمعرفة أفضلية واضحة. أظهرت دراسات الاستبعاد أن كل مكون — بيانات الرسم البياني المعرفي، وتركيز منطقة الاهتمام، والتمثيلات القابلة للتكيُّف — ساهم في مكاسب قابلة للقياس.
ماذا يعني هذا للمراقبة في العالم الحقيقي
بالنسبة لغير المتخصصين، الخلاصة أن OG‑CLIP هو خطوة نحو أنظمة أمنية ورقابية تستطيع التعرّف بشكل أكثر موثوقية على الطائرات والسفن غير المألوفة من الصور الواقعية، حتى عندما تكون أمثلة الوسم نادرة. من خلال الجمع بين المعرفة الخبيرة المنظمة، والتركيز التلقائي على جسم الاهتمام، ومستويات التفاصيل القابلة للتعديل، يجعل النهج ذكاء الرؤية-واللغة أكثر ذكاءً وعملية. بعيدًا عن الدفاع، قد تساعد أفكار مماثلة في مراقبة البيئة، والاستجابة للكوارث، وأنظمة التفتيش الصناعية على فهم المشاهد المعقدة أثناء التشغيل على مجموعة واسعة من العتاد.
الاستشهاد: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
الكلمات المفتاحية: التعرّف الصفري, نماذج الرؤية-واللغة, الكشف عن الأجسام, الاستشعار عن بُعد, رسوم المعارف