Clear Sky Science · ar
محولات التعلم العميق المبنية على الإدراك البصري لتصنيف اللوحات الفوتوغرافية والصور من خلال استخراج السمات
لماذا يهم هذا للصور اليومية
في عصر يمكن لأي شخص فيه توليد صورة شبيهة بالواقع ببضع نقرات، أصبح من الصعب التمييز بين الصورة الفوتوغرافية الحقيقية واللوحة التقليدية أو ما أُنتج بالكامل بواسطة خوارزميات. تستقصي هذه الدراسة كيف يمكن للذكاء الاصطناعي الحديث أن يميّز تلقائيًا اللوحات المصنوعة يدويًا عن الصور الملتقطة بالكاميرا، وحتى عن الصور المولَّدة بالذكاء الاصطناعي، ما يساعد في حماية أسواق الفن والأرشيفات والمستخدمين على الإنترنت من التضليل والتزوير.
الفن والصور وظهور الصور المولَّدة آليًا
قد تبدو اللوحات والصور الفوتوغرافية متشابهة للوهلة الأولى على الشاشة، لكن لكل منهما بصمات مرئية مختلفة للغاية. تميل اللوحات إلى إظهار ضربات فرشاة مرئية، ألوان مُجَرَّدة أسلوبياً، وتكوينات أكثر تجريدًا، بينما تحتوي الصور عادةً على تفاصيل أدق وإضاءة طبيعية. في الوقت نفسه، تنتج مولدات الصور الحديثة أعمالًا تقلد كلا الوسيطين بمهارة متزايدة. تحتاج المتاحف والمعارض وجامعو الأعمال والمنصات الرقمية بشكل متزايد إلى أدوات يمكنها بسرعة وبثقة تحديد نوع الصورة التي يتعاملون معها، سواء لمصادقة الأعمال أو لإدارة فيضان المحتوى التركيبِي.
خط سير جديد لتعليم الآلات على الرؤية
بنَى الباحثون خط أنظمة متكامل لتحليل الصور قائمًا على محول الرؤية، وهو نموذج تعلم عميق حديث طُوِّر أصلاً لمعالجة اللغة وأُعيد تكييفه للصور. درّبوا هذا النظام على مجموعة بيانات عامة من منصة Kaggle تحتوي على 1,361 لوحة و3,747 صورة فوتوغرافية، تمثل مجموعة واسعة من المشاهد والأنماط. تُجرى على كل صورة عملية توحيد أولًا: تُعاد تحجيمها، تُقصّ بشكل طفيف، ثم تُعزَز بعمليات قلب، دورانات صغيرة، تغيُّرات في السطوع، وإزالة الضوضاء بحيث يختبر النموذج تنويعات واقعية متعددة. بعد هذه التحضيرات، يقسم محول الرؤية كل صورة إلى رقع صغيرة ويتعلّم كيف ترتبط أجزاء الصورة ببعضها عبر الإطار كله. 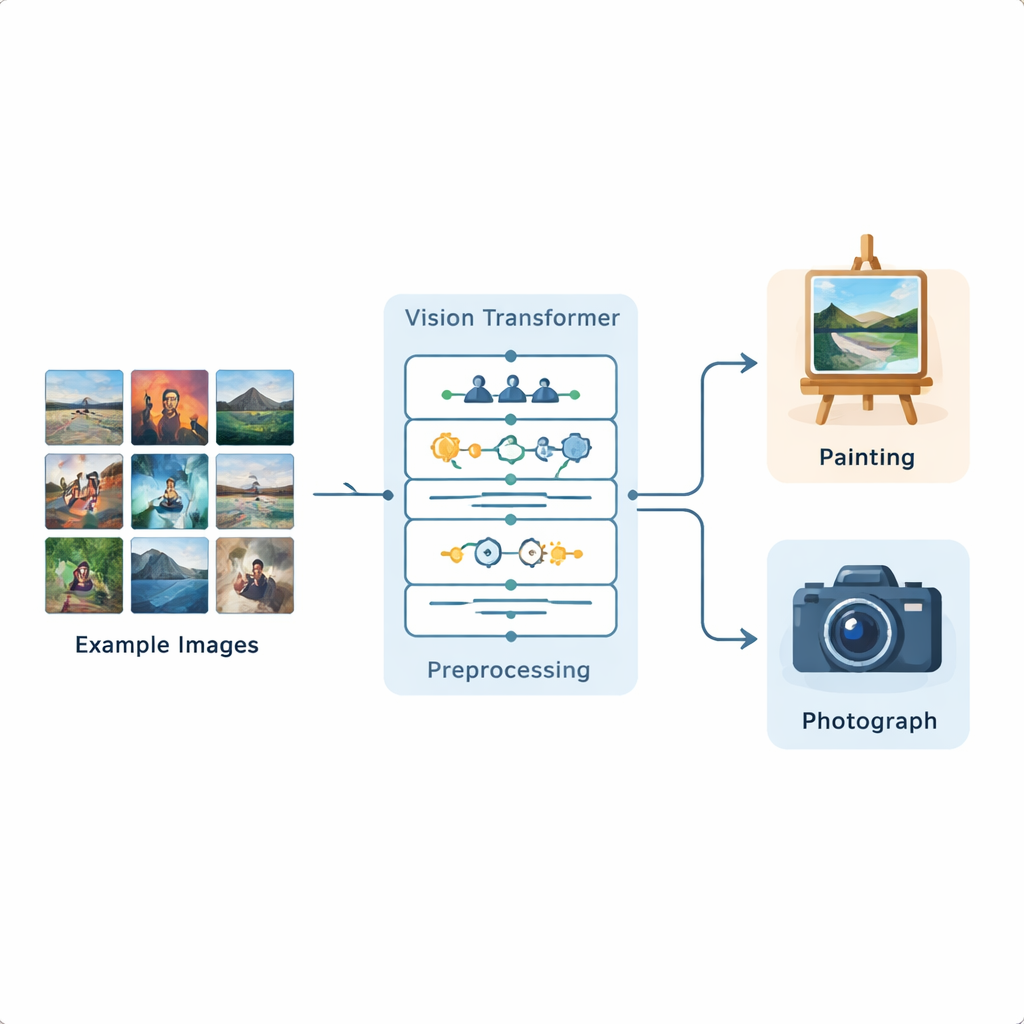
كيف يركِّز النموذج على التفاصيل الصحيحة
على عكس الشبكات العصبية السابقة التي تنظر أساسًا إلى الأنماط المحلية، يستخدم محول الرؤية آلية "الانتباه" ليقرر أي أجزاء الصورة أهم لمهمة التصنيف. يسأل عمليًا، لكل رقعة، إلى أي مدى ينبغي أن يولي اهتمامًا لكل رقعة أخرى. هذا يجعله أفضل في إدراك البنية العامة: كيف تتدفق الألوان عبر القماش، وكيف تسقط الإضاءة عبر المشهد، أو كيف تتكرر الخامات. للتأكد من أن النموذج لا يخمّن بشكل أعمى، يطبّق المؤلفون أيضًا طريقة تصوير تُسمى Grad-CAM، التي تبرز المناطق المحددة التي أثّرت في كل قرار. بالنسبة للوح، تميل هذه المناطق المظللة إلى التركيز على ملمس ضربات الفرشاة والمناطق الأسلوبية؛ أما في الصور الفوتوغرافية فتتجمع حول الحواف الدقيقة والأسطح الواقعية وانتقالات الإضاءة. 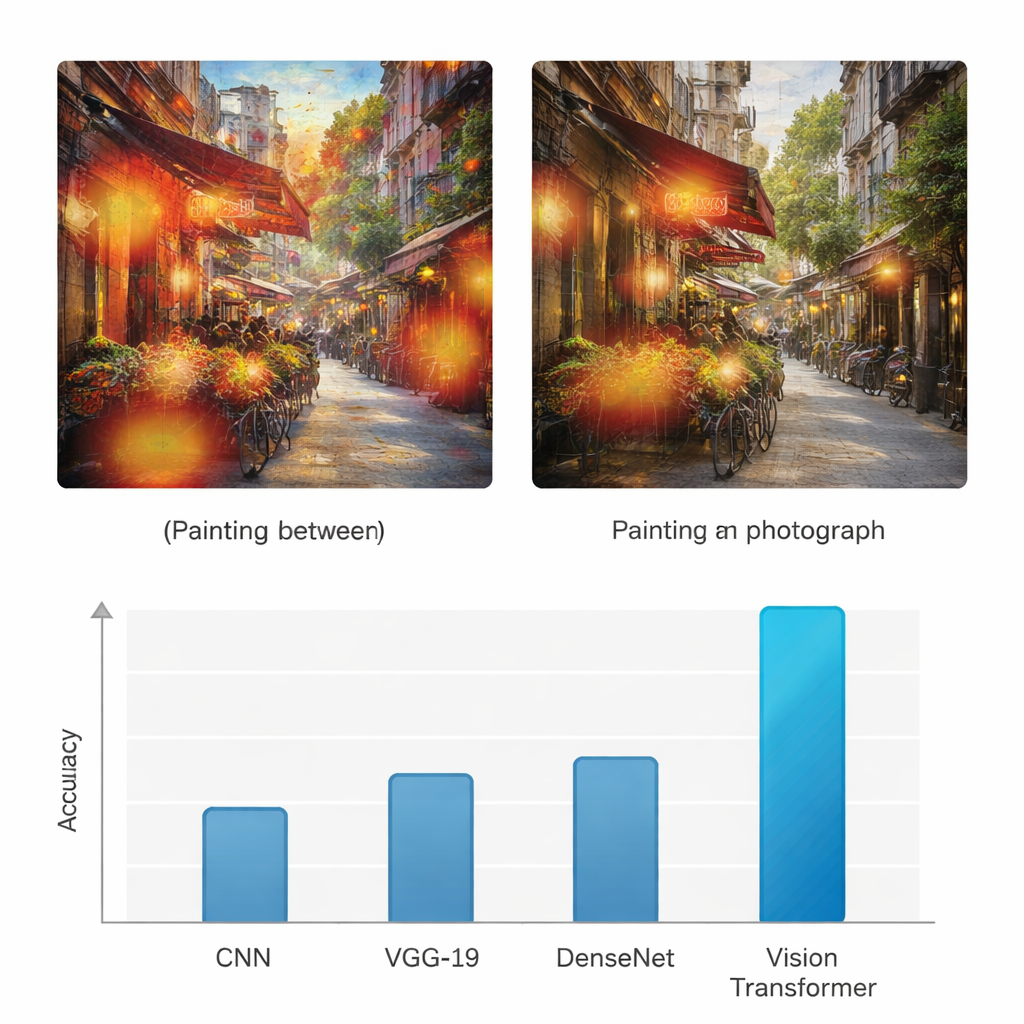
تفوق على أساليب تمييز الصور السابقة
لمعرفة ما إذا كانت هذه المقاربة تضيف قيمة فعلية، يقارن البحث محول الرؤية بثلاثة معمارية تعلم عميق شائعة: شبكة التلافيف العصبية القياسية (CNN)، وشبكة VGG-19، وDenseNet. تدرَّب جميع النماذج وتُختَبَر على نفس مجموعة البيانات، وتقَيَّم باستخدام مقاييس مألوفة مثل الدقة والدقة النوعية والاستدعاء ودرجة F1، التي توازن بين الاكتشافات الصحيحة والأخطاء لكلا الصنفين. بينما تصل الشبكات الأساسية إلى نسب دقة في نطاق منتصف السبعينات إلى منتصف الثمانينات بالمئة، يحقق محول الرؤية دقة 95% لكل من اللوحات والصور الفوتوغرافية، مع دقة واستدعاء مرتفعين بالمثل. يجري المؤلفون أيضًا اختبارات إحصائية متعددة للتأكيد أن هذا التحسّن ليس بسبب الصدفة، مما يبيّن أن النموذج القائم على المحول أفضل بشكل موثوق عبر تجارب متكررة ومعايير تقييم مختلفة.
ماذا يعني هذا للفن والثقة والتقنية
تشير النتائج إلى أن نماذج المحول الحديثة يمكن أن تكون أدوات قوية وقابلة للتفسير لفصل اللوحات عن الصور الفوتوغرافية وللكشف عن الصور المولَّدة بالذكاء الاصطناعي التي تقلد أيًا من الوسيطين. للمستخدمين غير المتخصصين، الخلاصة هي أن الحواسيب باتت قادرة على اكتشاف دلائل دقيقة—مثل ضربات الفرشاة، النعومة، أو تدرجات الإضاءة—قد يغفلها حتى المراقبون البشريون الدقيقون، وبسرعة وعلى نطاق واسع. يمكن لمثل هذه الأنظمة مساعدة المعارض والجامعين في التحقق من الأعمال، ومساعدة الأمناء والموثّقين في تنظيم مجموعات رقمية ضخمة، ودعم المنصات الإلكترونية في وسم أو تصفية المحتوى التركيبِي. مع استمرار مولدات الصور في طمس الحدود بين الواقع والاختراع، تقدم طرق مثل تلك المعروضة هنا وسيلة عملية للحفاظ على الثقة فيما نراه.
الاستشهاد: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
الكلمات المفتاحية: صور مولَّدة بالذكاء الاصطناعي, مصادقة الأعمال الفنية, تصنيف الصور, محول الرؤية, تحليل الفن الرقمي