Clear Sky Science · ar
التعلّم الفوقي للتعرّف على مهام مفتوحة بعدد قليل من الأمثلة
لماذا يهم تعليم الذكاء الاصطناعي بعدد قليل جدًا من الأمثلة
يمكن لأنظمة الذكاء الاصطناعي الحديثة أن تتعرّف على الوجوه والحيوانات والأشياء اليومية بدقة ملحوظة—ولكن عادةً فقط بعد أن ترى ملايين الصور المعلّمة. في كثير من الحالات الواقعية، مثل تشخيص مرض نادر أو اكتشاف نوع جديد من العيوب على خط إنتاج، لا تتوفر لدينا هذه الكمية من البيانات. يستكشف هذا البحث كيف يمكن تدريب نماذج ذكاء اصطناعي تتعلّم مهام بصرية جديدة من عدد قليل من الأمثلة، حتى عندما تختلف هذه المهام كثيرًا عما دُربت عليه النماذج. يقدّم الورق طريقة تسمى Open-MAML تهدف إلى جعل هذا النوع من التعلّم المرن قليل البيانات أكثر موثوقية وتوقّعًا.
من التدريبات الثابتة في الصف إلى الاختبارات القصيرة المفتوحة النهاية
يقيم معظم البحث في «التعلّم بعدد قليل من الأمثلة» أنظمة الذكاء الاصطناعي ضمن شروط محكمة. يُدرّب النموذج ويُختبر على مهام متشابهة للغاية، مثلاً دائماً يميّز بين خمس فئات بالضبط (يسمّى «خمس-طُرُق») مع مثال واحد لكل فئة («لقطة واحدة»). هذا يشبه تدريب طالب فقط على اختبارات من خمسة أسئلة مع مثال تدريبي واحد لكل نوع سؤال. في العالم الحقيقي الأمور أكثر فوضى: عدد الفئات يمكن أن يتغير، وكمية البيانات المعلّمة لكل فئة قد تزيد أو تقل مع الزمن. يسمي المؤلفون هذا الوضع الأكثر واقعية إعداد المهمة المفتوحة، حيث يجب على النماذج التعامل مع مهام ذات أعداد فئات وأمثلة مختلفة عما رأته أثناء التدريب. 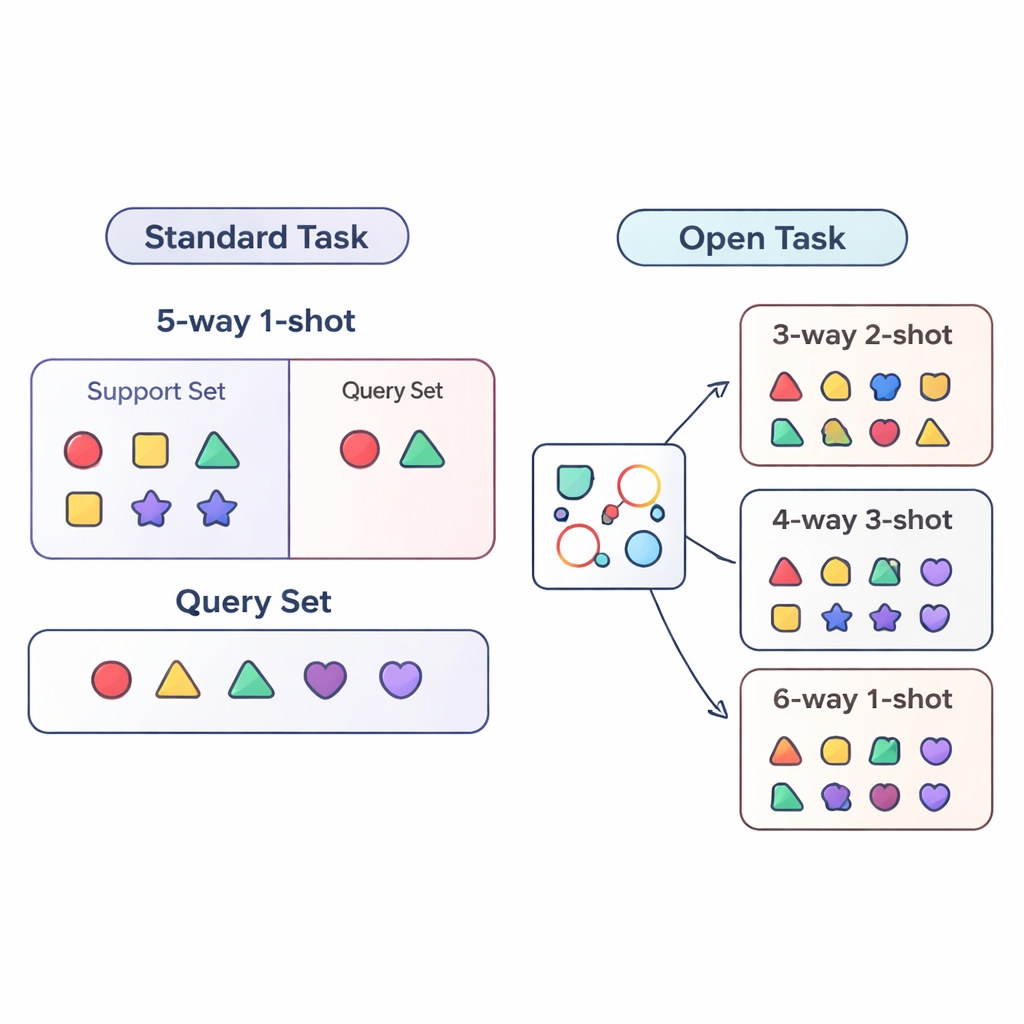
إعادة تعريف كيفية اختبار متعلّمي اللقطات القليلة
لدراسة عالم المهام المفتوحة بطريقة منهجية، يقترح البحث ثلاث نُظم تقييم. في نظام العرض المتقاطع (cross-way)، يتغيّر عدد الفئات فقط: قد يُدرّب النموذج على خمس فئات لكنه يُختبر على ثلاث أو خمسة عشر. في نظام اللقطة المتقاطعة (cross-shot)، يتفاوت عدد الأمثلة لكل فئة، من صورة مُعلّمة واحدة إلى عدة صور. الحالة الأصعب هي العرض المتقاطع-اللقطة المتقاطعة حيث يتغيّر كل من عدد الفئات وكمية البيانات لكل فئة معًا. كما يفحص المؤلفون ما يحدث عندما يتغيّر أسلوب الصور بصريًا، بالتدريب على مجموعة بيانات كائنات عامة والاختبار على مجموعة طيور ذات تفاصيل دقيقة. تم تصميم هذه الإعدادات لكشف ما إذا كانت الطريقة قادرة فعلاً على التعميم خارج وصفة تدريب ثابتة واحدة.
كيف يتكيّف Open-MAML بسرعة
يبني Open-MAML على استراتيجية تعلّم فوقي شائعة تُسمى التعلّم الفوقي النمطي النماذج-محايدة (MAML)، التي تُدرّب نموذجًا ليتمكّن من التكيّف السريع لمهمة جديدة بعد عدد قليل من خطوات التدرّج. ومع ذلك، يفترض MAML القياسي أن عدد الفئات وقت الاختبار يطابق التدريب، ويستخدم طبقة تصنيف نهائية ثابتة. يقدم Open-MAML ثلاث تغييرات رئيسية لكسر هذا القيد. أولًا، يستخدم بناء المُصنِّف الديناميكي: عندما تحتوي المهمة الجديدة على فئات أكثر من السابقة، ينشئ وحدات إخراج إضافية بنسخ متوسط الوحدات الموجودة، مانحًا النموذج نقطة بداية محايدة ومعقولة. ثانيًا، يُعدّل معدل التعلّم الداخلي اعتمادًا على عدد الفئات والأمثلة في المهمة، ليبقى التكيّف مستقرًا سواء كانت البيانات نادرة أو وفيرة. ثالثًا، يضيف مُنظِّمًا يُسمّى AdaDropBlock يخفي مؤقتًا مناطق متجاورة في خرائط السمات أثناء التدريب، حاثًا النموذج على استخدام إشارات بصرية أكثر تنوعًا بدلًا من الإفراط في التخصيص لتفاصيل صغيرة وهشة. 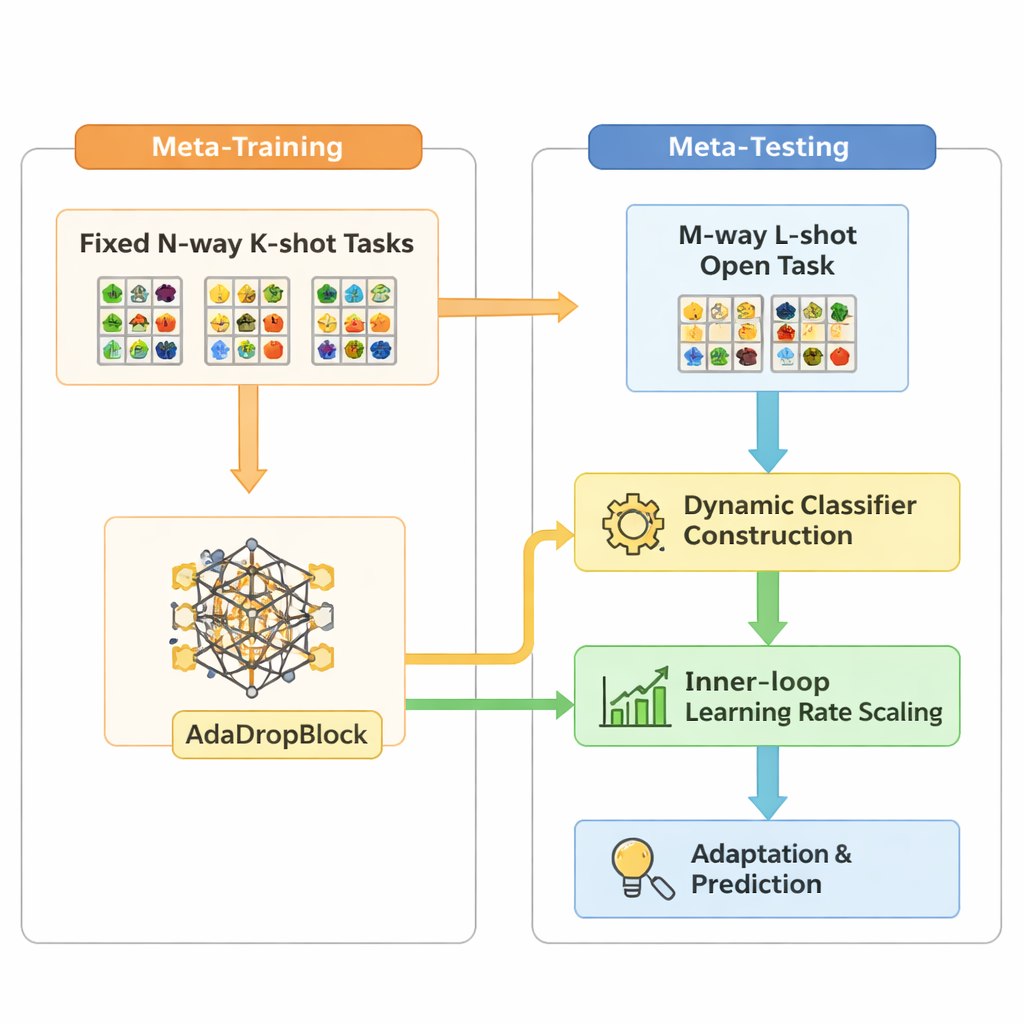
اختبار التعلّم المرن
يقيم الباحثون Open-MAML على معايير قليلة-اللقطات القياسية وكذلك في سيناريوهات المهمة المفتوحة الجديدة، ويقارنونه بعدة طرق أساسية معروفة. تشمل هذه نماذج تُدرّب من الصفر لكل مهمة، ونماذج تستخدم مُستخرِج ميزات قوي مُدرّب مسبقًا مع مُصنّف يُعاد ضبطه، وطرق قائمة على القياس تُصنّف الصور اعتمادًا على المسافة إلى «نماذج فئة» (prototypes). جميع الطُرُق تشترك في نفس الشبكة الأساسية حتى تأتي الفروقات من استراتيجية التعلّم لا من البنية. عبر عشرات الآلاف من مهام الاختبار، يحقق Open-MAML دقة أعلى باستمرار—عادةً أفضل بنحو 1–7 نقاط مئوية عندما يتغير عدد الفئات أو الأمثلة فقط، و3–6 نقاط أفضل عندما يتغيران معًا. تزيد المكاسب في الإعدادات الأصعب ذات الفئات الأكثر أو اللقطات الأكثر أو عند التحول إلى مجموعة بيانات الطيور، مما يوحي بأن آليات التكيّف فيه فعلاً تفيد في ظروف معقّدة وغير مألوفة.
ما يعنيه هذا لأنظمة الذكاء الاصطناعي في العالم الحقيقي
للقارئ العام، الخلاصة هي أن ليس كل متعلّمات اللقطات القليلة متماثلات بمجرد أن نخرج من منطقة الراحة في المختبر. قد تتعثّر طريقة تؤدي جيدًا على معيار ثابت واحد عندما يتغير عدد الفئات أو كمية البيانات المعلّمة. يُظهر Open-MAML أنه من خلال التخطيط صراحةً لمثل هذه التغييرات البنيوية—بجعل المصنّف ينمو أو يتقلّص، وموازنة معدل التعلّم حسب حجم المهمة، وتنظيم السمات بطريقة لا تعتمد على المهمة—يمكن لأنظمة الذكاء الاصطناعي التعامل بشكل أفضل مع الظروف المتغيرة التي ستواجهها عمليًا. في مجالات مثل تصوير الطب، ورصد الأقمار الصناعية، أو الفحص الصناعي، حيث تتغيّر مجموعات الفئات وتوافر العلامات باستمرار، قد تجعل هذه النوعية من المتانة للمهمة المفتوحة التعلّم بعدد قليل من الأمثلة أكثر قابلية للاستخدام خارج مجموعات المعايير البحثية المناقَبة بعناية.
الاستشهاد: Han, X., Shi, D., Wang, Z. et al. Meta-learning for few-shot open task recognition. Sci Rep 16, 5624 (2026). https://doi.org/10.1038/s41598-026-36291-x
الكلمات المفتاحية: التعلّم بعدد قليل من الأمثلة, التعلّم الفوقي, التعرّف على مهام مفتوحة, تصنيف الصور, التعميم