Clear Sky Science · ar
إطار تعلم عميق هجين لتصنيف دقيق للبيانات الجينومية عالية البعد
فهم فيض بيانات الجينوم
تستطيع تقنيات الحمض النووي الحديثة قياس عشرات الآلاف من الجينات في تجربة واحدة، ما يعد بالكشف المبكر عن الأمراض وعلاجات أكثر دقة. ومع ذلك، فإن ثروة البيانات هذه كبيرة للغاية، وصاخبة، ومعقدة لدرجة أن النماذج الحاسوبية القوية غالباً ما تكافح للعثور على أنماط واضحة وموثوقة. يقدم هذا البحث نوعاً جديداً من أنظمة الذكاء الاصطناعي المصممة خصيصاً للتعامل مع مثل هذه البيانات الجينومية المربكة، بهدف تحسين دقة التنبؤات مع توضيح كيفية الوصول إلى هذه التنبؤات.
لماذا من الصعب استخدام البيانات الجينومية
تنتج الدراسات الجينومية روتينياً قياسات أكثر بكثير من عدد المرضى أو العينات. العديد من هذه القياسات غير ذات صلة أو مكررة أو مشوهة بسبب ضوضاء تقنية. تتطلب طرق التعلم الآلي التقليدية إما خبراء بشريين لاختيار الجينات المهمة يدوياً، أو محاولة استخدام كل شيء مع مخاطرة الإفراط في التكيّف — أي أداء جيد على بيانات التدريب لكنه يفشل على حالات جديدة. يمكن للتعلم العميق، الذي غيّر مجالات مثل التعرف على الصور، أن يتعلم تلقائياً الأنماط من البيانات الخام. ومع ذلك، في علم الجينوم غالباً ما يتصرف كصندوق أسود: قد يعطي إجابات دقيقة لكنه يقدم القليل من الفهم حول السبب، مما يحد من اعتماده في الطب حيث الشفافية أمر أساسي.
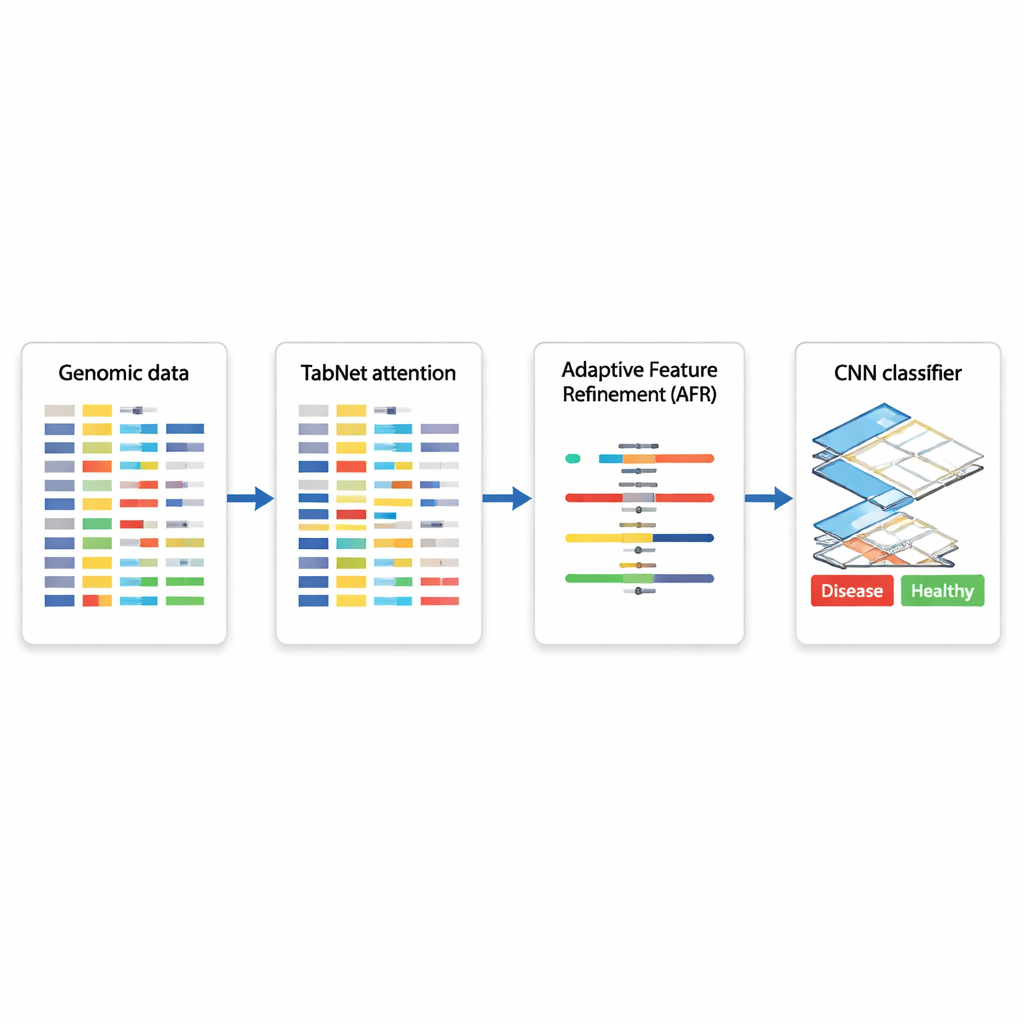
مخطط هجيني لاتخاذ قرار معتمد على الجينات
يقترح المؤلفون بنية تعلم عميق هجينة تربط ثلاث وحدات متخصصة ببعضها. أولاً، مكون يُسمى TabNet يعمل ككشاف، يمسح كل القياسات الجينومية المتاحة ويتعلم أي السمات أكثر إبلاغاً بمهمة معينة — على سبيل المثال التمييز بين نسيج سرطاني وغير سرطاني. بدلاً من معاملة كل جين على قدم المساواة، يركز TabNet الانتباه على مجموعة متفرقة تبدو الأكثر صلة. بعد ذلك، تأخذ طبقة تنقية السمات التكيفية (AFR) هذه الإشارات المختارة وتعيد وزنها، مع تعزيز الأنماط المتسقة والمهمة مع مزيد من تخفيف الضوضاء. أخيراً، يفحص شبك عصبي تلافيفي (CNN)، مستخدم عادة في تحليل الصور، كيف تتفاعل السمات المنقحة محلياً، ملتقِطاً علاقات دقيقة بين مجموعات الجينات قد تشير إلى نوع فرعي معين من المرض أو حالة بيولوجية.
تجريب النموذج
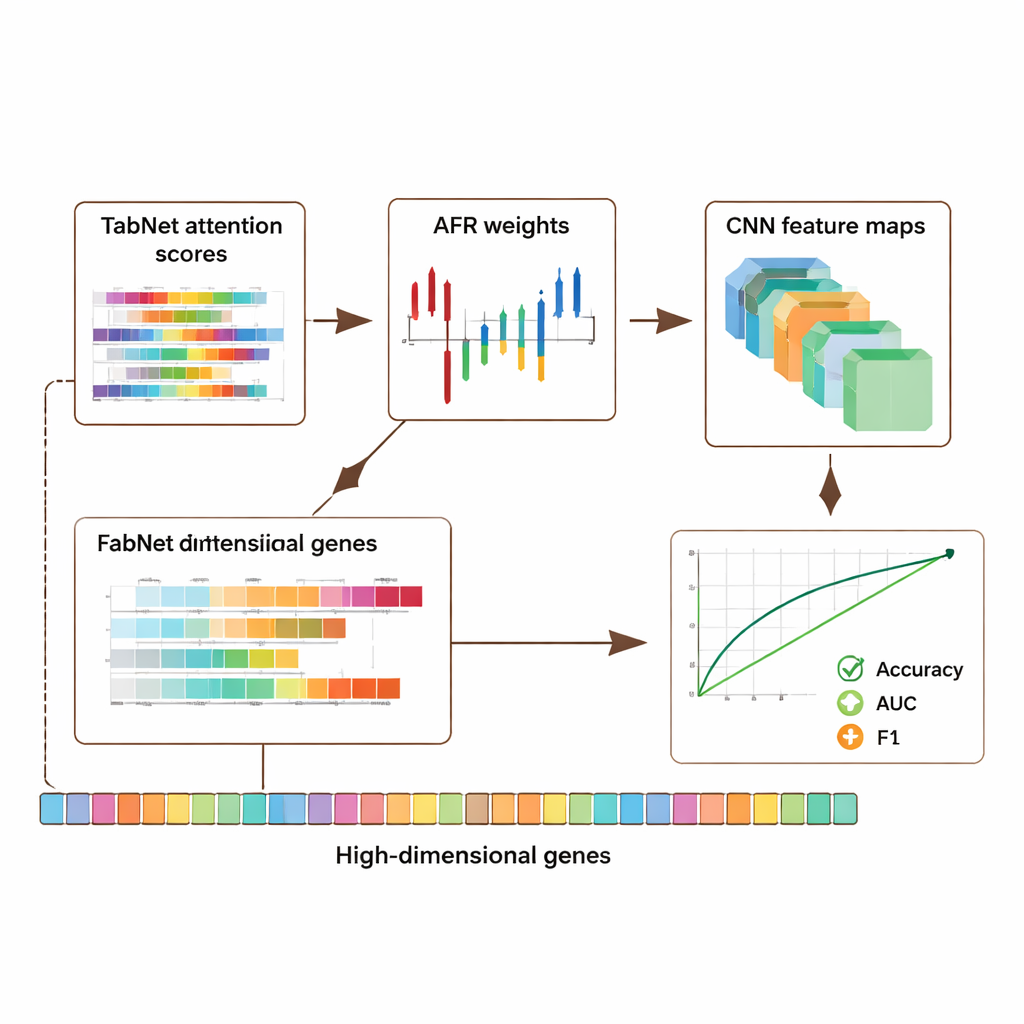
تم تقييم الإطار على ثلاث موارد عامة رئيسية: مجموعة بيانات سرطان الثدي من أرشيف جينوم السرطان (TCGA)، وبيانات خلية مفردة للورم الميلاني من مستودع التعبير الجيني (GEO)، ومجموعة بيانات فوق جينية من مشروع ENCODE. تغطي هذه المجموعات معاً آلاف العينات وعشرات الآلاف من الميزات لكل عينة، بما في ذلك نشاط الجينات والآثار الكيميائية على الحمض النووي. عبر جميع المجموعات، تفوق النموذج الهجين على عدة طرق متقدمة، محققاً تحسناً في الدقة ومقاييس الجودة التصنيفية الرئيسية مثل المساحة تحت منحنى الاستجابة التشغيلي (AUC) ومقياس F1 بحوالي 5–8 نقاط مئوية. والأهم أن هذه المكاسب لم تأتِ على حساب الشفافية: ينتج النموذج خرائط انتباه من TabNet وخرائط تنشيط من الـCNN تبرز الجينات والمناطق الأكثر تأثيراً في كل تنبؤ.
موازنة الدقة والخصوصية والثقة
ولأن البيانات الجينومية شخصية للغاية، درس المؤلفون أيضاً كيف يحميون الخصوصية مع الحفاظ على الإشارة المفيدة. قدموا آلية خصوصية تكيفية تضيف مزيداً من الضوضاء إلى الميزات شديدة الحساسية وأقل إلى غيرها، مقترنة بإخفاء مُدخلات مُنتقاة. أظهرت الاختبارات أنه حتى عند إدخال ضوضاء معتدلة، حافظ النموذج على دقة وتمييز قويين، مع تدهور الأداء تدريجياً كلما زاد مستوى الحماية. في الوقت نفسه، أشارت أنماط الانتباه والتنشيط القابلة للتفسير غالباً إلى جينات معروفة مسبقاً بدورها في السرطان وتنظيم المناعة، مما يوحي بأن النظام لا يحفظ البيانات ببساطة بل يلتقط إشارات ذات معنى بيولوجي. وأكدت دراسة الإزالة — التي تزيل أجزاء من البنية بشكل منهجي — أن كل وحدة، وبالأخص طبقة AFR، ساهمت مساهمة قابلة للقياس في الأداء.
ما الذي يعنيه هذا لمستقبل الطب
بعبارات بسيطة، يقدم هذا العمل طريقة أذكى لنخل مئات الآلاف من الصفوف والحقول الجينومية للعثور على أنماط مرتبطة بالمرض، مع توضيح أي خانات في الجدول كانت الأكثر أهمية. من خلال الجمع بين اختيار السمات المستهدف، والتنقية الحذرة، والتعرف على الأنماط، يحسن النموذج الهجين دقة التوقعات، يظل قابلاً للإدارة حسابياً، ويوفر دلائل مرئية يمكن للأطباء والبيولوجيين تفسيرها. وعلى الرغم من الحاجة لمزيد من الاختبارات على مجموعات أوسع وأكثر تنوعاً من المرضى، قد تساعد مثل هذه الأطر في التعرف على مؤشرات حيوية جديدة، وتحديد أنواع فرعية من الأمراض، ودعم أدوات القرار السريري في الطب الدقيق — ما يقرب تحليلات الذكاء الاصطناعي للحمض النووي خطوة أقرب إلى التطبيق العملي.
الاستشهاد: Swain, M.K., Kamila, N.K., Jena, L. et al. Hybrid deep learning framework for accurate classification of high dimensional genomic data. Sci Rep 16, 5919 (2026). https://doi.org/10.1038/s41598-026-36128-7
الكلمات المفتاحية: التعلم العميق الجينومي, اكتشاف مؤشرات السرطان, الذكاء الاصطناعي القابل للتفسير, الطب الدقيق, علم الجينوم المحافظ على الخصوصية