Clear Sky Science · ar
التحكم التنبؤي القائم على التعلم المعزز لتحسين محرك متزامن ذو مغناطيس دائم يدور بالاتجاهين للدفع تحت الماء
محركات أذكى لغواصات أكثر تخفياً
تعتمد الغواصات الحديثة على دفع هادئ وفعال لاستكشاف المحيطات وأداء مهام علمية أو تجارية أو دفاعية. تبحث هذه الدراسة في نوع خاص من المحركات الكهربائية يدير دفّتين في اتجاهين متعاكسين، مما يساعد الغواصة على التحرك بسلاسة وبصمت عبر الماء. يظهر الباحثون كيف أن دمج أدوات تنبؤ متقدمة مع خوارزمية تعلم يمكن أن يحافظ على استقرار هذه المحركات وكفاءتها، حتى عندما تزعجها الأمواج والتيارات والمناورات المفاجئة.
دفّتان، غواصة واحدة مستقرة
يمكن لأنظمة الدفّ الواحد التقليدية أن تسبب التواءً وتمايلاً في الغواصة، خاصة عند السرعات العالية، مما يصعّب القيادة ويزيد إمكانية اكتشافها. لتجنب ذلك، يستخدم المهندسون أنظمة دفع ذات دفّتين تدوران في اتجاهين متعاكسين: دفّتان مثبتتان على نفس العمود لكن تدوران بعكس بعضهما. في قلب هذا التصميم يوجد المحرك المتزامن ذو المغناطيس الدائم الدوار في اتجاهين معاكسين (CRPMSM)، وهو في الأساس محركان كهربائيان مدمجان عاليان العزم مكدسان معًا. تلغي هذه التركيبة القوى الالتوائية غير المرغوبة، وتحسّن استخدام الطاقة، وتقلّل الضوضاء — وكلها عوامل حاسمة للتخفّي والمهام الطويلة تحت الأمواج. ومع ذلك، عندما يصبح الحمل على الدوارات غير متوازن، كما في المياه الاضطرابية أو المنعطفات الحادة، يصبح الحفاظ على تزامن دوران الجانبين تحديًا تحكمياً جديًا. 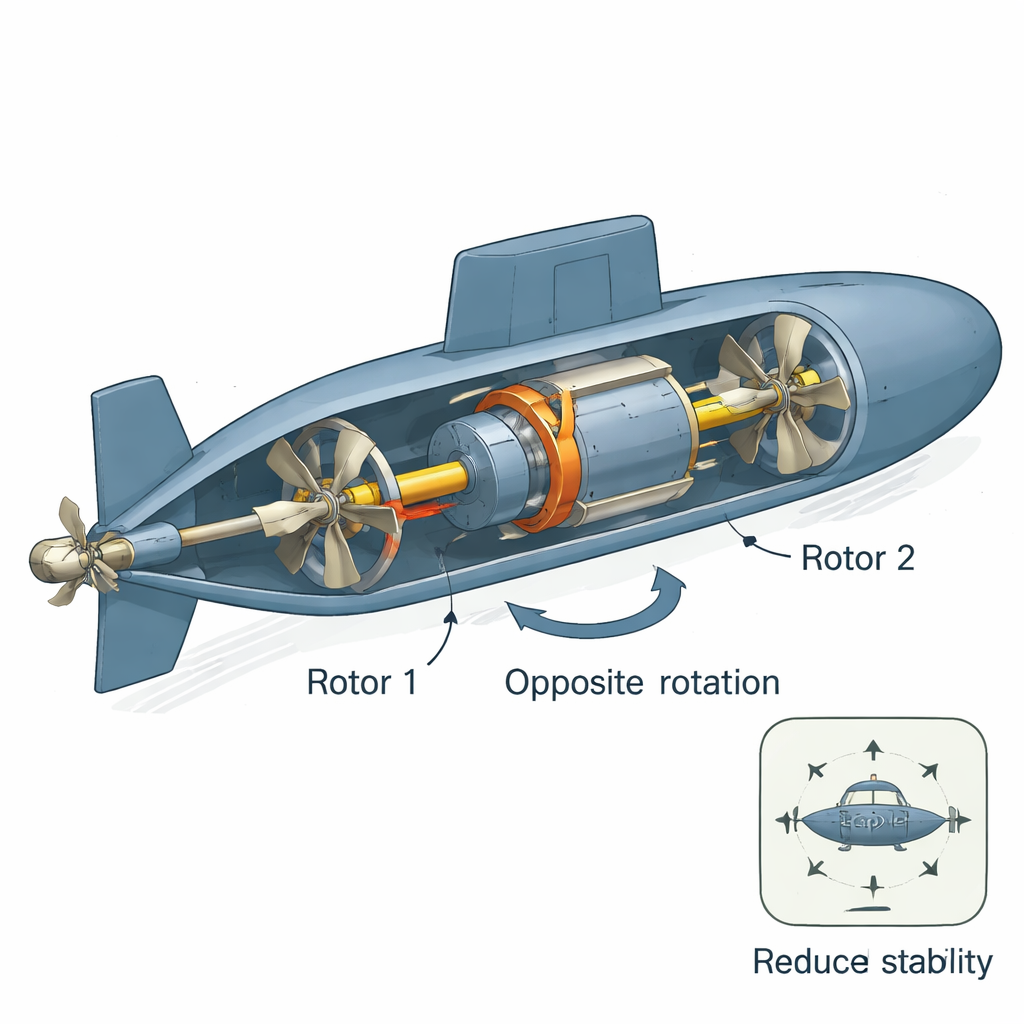
لماذا تقصّر الطرق التقليدية
جرّب المهندسون العديد من استراتيجيات التحكم للحفاظ على تزامن دوارات CRPMSM وكفاءتها. يمكن لأساليب مثل التحكم الموجه بالمجال والتحكم المباشر بالعزم أن تعمل جيدًا في ظروف هادئة ومتوقعة، لكنها تواجه صعوبة عندما يتغير بيئة العمل تحت الماء بسرعة أو تصبح غير متساوية بشدة. تحسّن تقنيات أكثر تطورًا مثل التحكم بحالة الانزلاق، والتحكم الضبابي، والتحكم التكيفي من المتانة، لكنها غالبًا ما تعتمد على نماذج رياضية دقيقة للغاية للمحرك والمياه المحيطة. عمليًا، لا تكون تلك النماذج مثالية، ويمكن أن يؤدي عدم التطابق إلى زيادة تموج العزم، وإبطاء التعافي بعد الاضطرابات، وإهدار الطاقة. يوفر التحكم التنبؤي النموذجي (MPC)، الذي يخطط حركات تحكم مثلى على نافذة مستقبلية قصيرة، استجابة سريعة لكنه لا يزال مرتبطًا ارتباطًا وثيقًا بجودة النموذج المستخدم.
متحكم هجين يتعلّم أثناء العمل
يقترح المؤلفون إطارًا هجينًا يجمع بين التعلم المعزز والتحكم التنبؤي النموذجي (RL-MPC) يجمع مزايا النهجين. يستخدم MPC نموذجًا رياضيًا لـ CRPMSM للتنبؤ بكيفية تطور التيارات والعزم والسرعة على مدى خطوات تحكم مستقبلية قليلة، ويختار أوامر الفولتية التي ينبغي أن تتتبع أهداف السرعة والتيار مع احترام الحدود. فوق ذلك، يراقب وكيل تعلم معزز مبني على خوارزمية Twin Delayed Deep Deterministic Policy Gradient (TD3) سلوك المحرك الحقيقي. عبر تلقي مكافآت عندما تكون أخطاء السرعة، وأخطاء التيار، وجهد التحكم صغيرة، يقوم الوكيل التعلمي تدريجيًا بتعديل مخرجات MPC للتعويض عن أخطاء النمذجة، والأحمال غير المتوازنة، والاضطرابات الخارجية. ثم تحول مرحلة تعديل عرض النبضة متجهة الفضاء هذه الأوامر الفولتية المُحسَّنة إلى إشارات تبديل للعاكس الذي يشغّل المحرك.
اختبار المحرك الذكي
لتقييم نهجهم، بنى الباحثون محاكاة مفصلة لنظام محرك يدور باتجاهين بقدرة 120 كيلوواط في MATLAB/Simulink واختبروها تحت ثلاث سيناريوهات تشغيل واقعية. في السيناريو الأول، عمل المحرك بسرعة ثابتة بينما تغير الحمل على كلتا الدوارتين لكنه ظل متوازنًا؛ في الثاني، تغيرت السرعة تحت حمل ثابت؛ وفي الثالث، وهو الحالة الأكثر تطلبًا، تعرضت الدوارات لأحمال مختلفة بينما كانت قيمة السرعة ثابتة. في كل حالة، قورن RL-MPC مباشرةً مع MPC التقليدي باستخدام نفس نوافذ التنبؤ والتحكم. 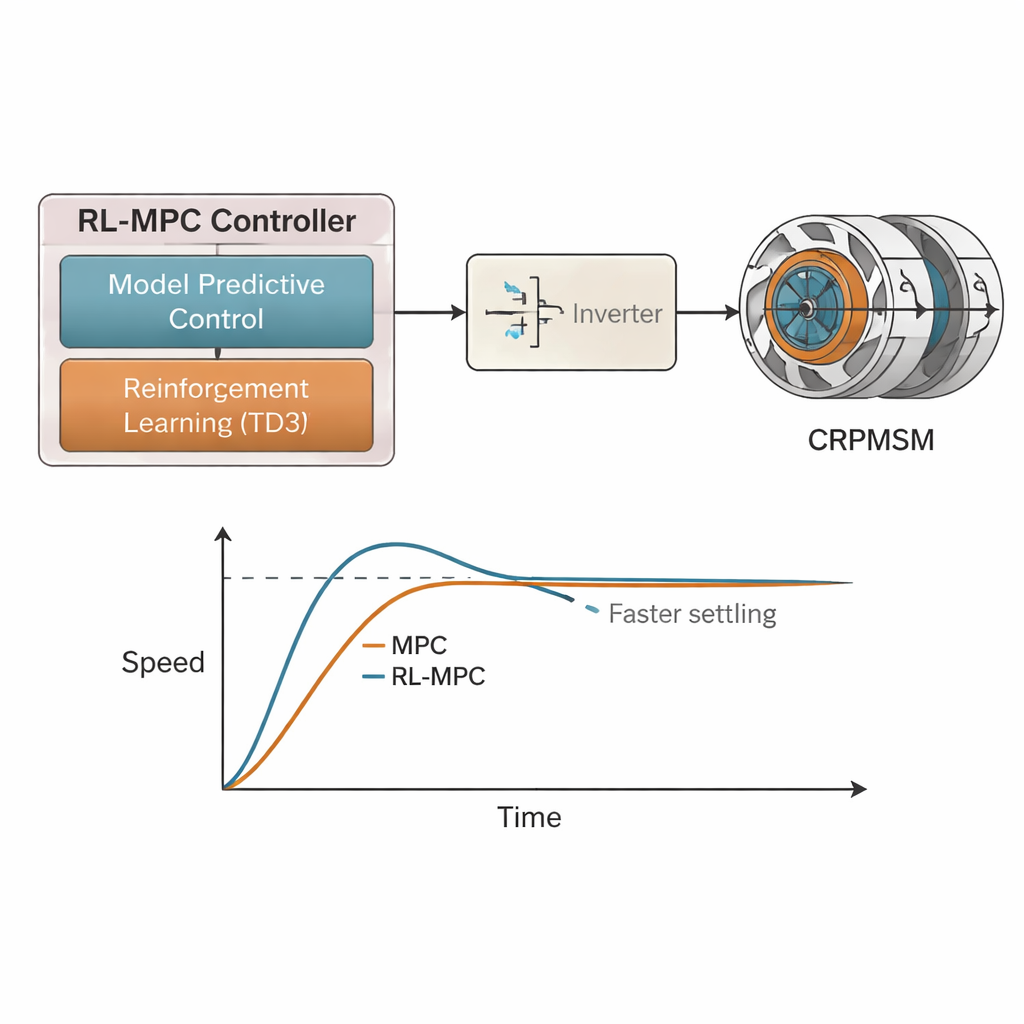
استجابة أسرع، تيارات أنظف، تزامن أفضل
تفوق المتحكم الهجين RL-MPC باستمرار على MPC القياسي في جميع الاختبارات. عندما تغيرت الأحمال أو السرعات فجأة، خفّض RL-MPC تجاوز السرعة من نحو 30% إلى نحو 15–16.6% وقلّص زمن الاستقرار إلى النصف من نحو 1.4 ثانية إلى 0.7 ثانية تقريبًا. كانت تموجات العزم أصغر، وبقيت الدوارات الدوارة في اتجاهين متعاكسين متزامنة عن كثب، حتى عندما حملت إحدى الدوارات حملاً أثقل من الأخرى. وبالمثل، تحسنت جودة تيارات العضو الثابت بشكل ملحوظ: انخفض إجمالي التشوه التوافقي بأكثر من 60% أثناء الانتقالات القاسية الناتجة عن الأحمال غير المتوازنة، من 9.3% في MPC إلى 3.4% في RL-MPC، ووصل إلى نحو 2–3% في حالة الاستقرار. تعني التيارات الأنظف تسخينًا أقل، وعملًا أكثر هدوءًا، وكفاءة أعلى بشكل عام.
ماذا يعني هذا للمركبات تحت الماء في المستقبل
بالنسبة لغير المتخصصين، الرسالة الأساسية هي أن إضافة طبقة تعلم فوق متحكم تنبؤي تجعل محركات الغواصات أذكى وأكثر متانة. بدلًا من الاعتماد فقط على معادلات ثابتة قد تفشل عندما يصبح البحر هائجًا أو تؤدي المركبة مناورات حادة، يستطيع إطار RL-MPC التكيف فورًا، محافظًا على تزامن المحرك ثنائي الدوار واستجابته وكفاءته. بينما ترتكز النتائج حتى الآن على المحاكاة وستحتاج إلى التحقق منها على الأجهزة الحقيقية وفي محيطات حقيقية، تشير هذه الدراسة إلى مركبات تحت الماء مستقبلية تسافر لمسافات أبعد بنفس الطاقة، وتصدر ضوضاء أقل، وتظل مستقرة وقابلة للتحكم في ظروف صعبة.
الاستشهاد: Delelew, E.Y., Dulecha, K.A., Ararso, Z.T. et al. Reinforcement learning-driven model predictive control for optimizing counter-rotating permanent magnet synchronous motor in submarine propulsion system. Sci Rep 16, 5277 (2026). https://doi.org/10.1038/s41598-026-36126-9
الكلمات المفتاحية: دفع الغواصات, محرك يدور في اتجاهين معاكسين, التحكم بالتعلم المعزز, التحكم التنبؤي النموذجي, المركبات تحت الماء