Clear Sky Science · ar
استراتيجية تحسين ديناميكية مدفوعة بالتعلم المعزز لتصميم نماذج ثلاثية الأبعاد معامِدية
تصاميم ثلاثية الأبعاد أذكى مع جهد تخمين أقل
من المباني اللافتة للانتباه إلى أجزاء ميكانيكية صغيرة داخل هاتفك، يبدأ العديد من الأشياء الحديثة حياتها كنماذج ثلاثية الأبعاد على الحاسوب. غالبًا ما يستخدم المصممون نماذج «معاملية» حيث تتحكم أشرطة التمرير والصيغ في الأشكال والأحجام والأنماط. هذا يجعل استكشاف العديد من الخيارات سهلاً — لكنه أيضًا يخلق متاهة من الاحتمالات من المستحيل تفقدها يدويًا. تعرف هذه الورقة منهجًا جديدًا للذكاء الاصطناعي يُسمى HRL‑DOS يساعد الحواسيب على التنقل في تلك المتاهة، محسنًا تلقائيًا التصاميم الثلاثية الأبعاد من حيث القوة واستهلاك المواد وسهولة التصنيع.
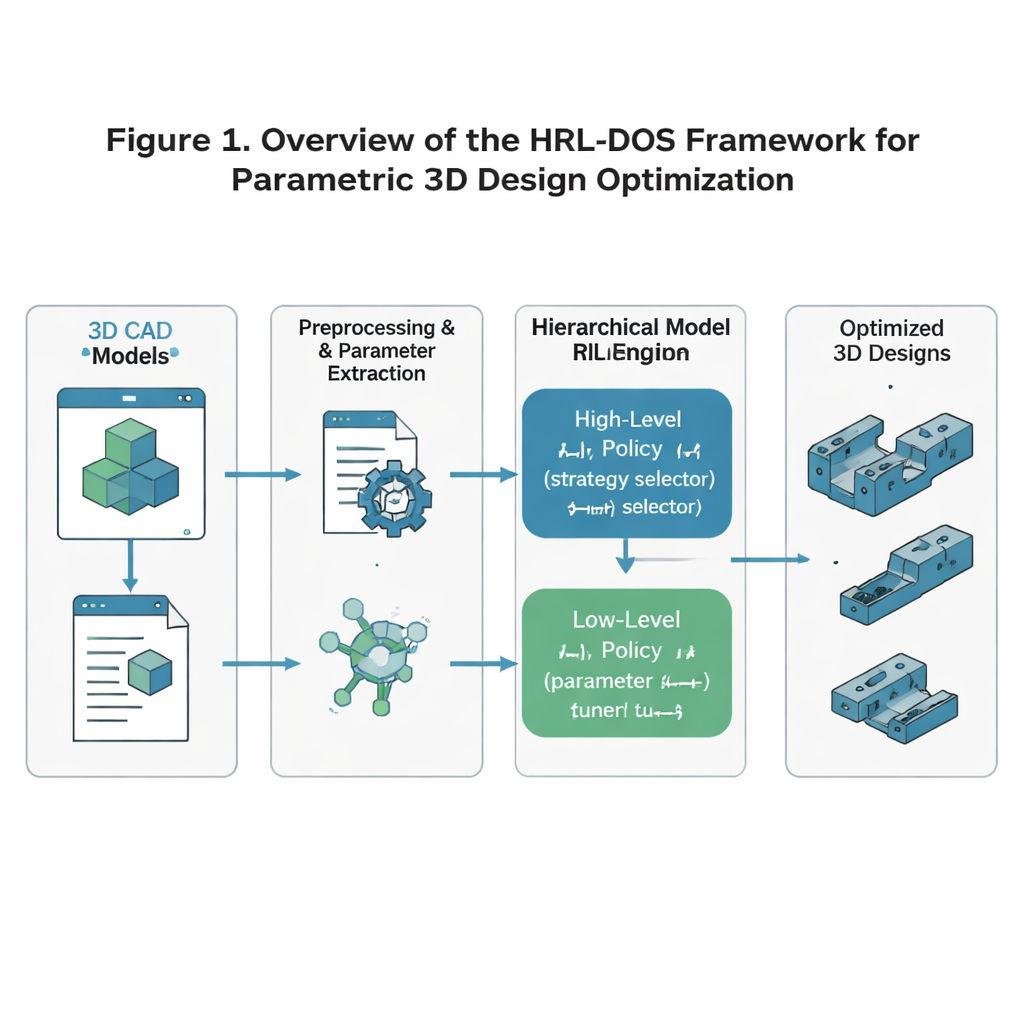
تحدي كثرة الخيارات
في التصميم المعامِدي، قد يعتمد جسم واحد على عشرات أو مئات المعاملات المترابطة: سمك الجدران، أحجام الثقوب، المنحنيات، وقواعد المحاذاة. مع تعقّد النماذج، تتفاعل هذه المعاملات بطرق غير بديهية. أدوات التحسين التقليدية إما تعتمد على دوال رياضية ملساء، والتي تنهار عندما تكون التصاميم غير منتظمة أو مشوشة، أو على أساليب بحث تعتمد على التجربة والخطأ، والتي يمكن أن تكون بطيئة للغاية للمشكلات الكبيرة. حتى التعلم المعزز القياسي — حيث يتعلم وكيل الذكاء الاصطناعي من التجربة والتغذية الراجعة المتكررة — يواجه صعوبة عندما يجب عليه مراعاة كل تركيبة ممكنة من قرارات التصميم دفعة واحدة.
ذكاء اصطناعي ذو مستويين يفكر مثل المصمم
يقترح المؤلفون استراتيجية التحسين الديناميكية المعتمدة على التعلم المعزز الهرمي، أو HRL‑DOS، للتعامل مع هذا التعقيد. بدلًا من اعتبار التصميم قرارًا هائلاً واحدًا، تقسم HRL‑DOS المهمة إلى طبقتين. تختار سياسة عليا اتجاهًا عامًا للتصميم — مثل تفضيل خفة الوزن، أو زيادة التماثل، أو هامش أمان أكبر. ثم تقوم سياسة دنيا بضبط المعاملات الفردية، مثل الأبعاد المحددة أو مواضع الميزات، ضمن ذلك المخطط الأوسع. تتلقى كلتا الطبقتين تغذية راجعة بناءً على مدى أداء النموذج الحالي بالنسبة لثلاثة أهداف رئيسية: الاستقرار الهيكلي، الكفاءة الهندسية، وقابلية التصنيع. تعكس هذه البنية متعددة المستويات طريقة عمل المصممين البشر: أولًا تحديد المفهوم، ثم ضبط التفاصيل بدقة.
تحويل النماذج ثلاثية الأبعاد الخام إلى بيانات قابلة للتعلم
لتدريب هذا النظام، يبدأ الباحثون بمجموع بيانات ABC، وهي مجموعة مفتوحة كبيرة من نماذج ثلاثية الأبعاد صناعية مفصلة مثل قواعد التثبيت، التروس، الروافع، ولوحات التركيب. يقومون بتهيئة كل نموذج بحيث يرى الذكاء الاصطناعي تمثيلًا نظيفًا ومتسقًا: تُعدل الهندسة إلى مقياس واتجاه قياسيين؛ تُستخرج الأبعاد والميزات الأساسية كمعاملات؛ وتُشفّر قواعد التصنيع — مثل الحد الأدنى لسمك الجدران أو زوايا التعليق المسموح بها — كقيود. ثم تتحول هذه المعاملات إلى وصف «كامِن» مضغوط يثني بشكل طبيعي عن الأشكال غير الممكنة أو غير المستقرة. النتيجة هي حالة عددية يمكن للذكاء الاصطناعي تعديلها بأمان مع الالتزام بقواعد هندسية أساسية.
التعلم لتحسين قطع واقعية
ضمن هذه البيئة المحضرة، يقترح الوكلاء الهرميون مرارًا وتكرارًا تصميمات جديدة، ويجرون محاكاة لتقدير الوزن والإجهاد، ويفحصون قابلية التصنيع، ويتلقون درجة مكافأة مجمعة. على مدى حلقات تدريب كثيرة، يتعلم الوكيل العلوي أي الأهداف الاستراتيجية تميل إلى أن تؤدي نتائج جيدة، بينما يكتشف الوكيل السفلي أي تعديلات للمعاملات تحقق تلك الأهداف فعليًا. اختبرت الفريق HRL‑DOS على عدة قطع ممثلة من المجموعة — مثل قاعدة مدعمة أضلاعياً، قرص تروس، مسكة رافعة، ولوحة تثبيت — وقارنت أداءه بعدة بدائل متقدمة، بما في ذلك التعلم المعزز المسطح، هجائن الخوارزميات الجينية، وأدوات تصميم مدعومة بالذكاء الاصطناعي الأخرى. وصلت HRL‑DOS إلى حلول جيدة أسرع بنحو 27% وأنتجت نماذج ذات درجات جودة كلية أعلى بحوالي 18%.
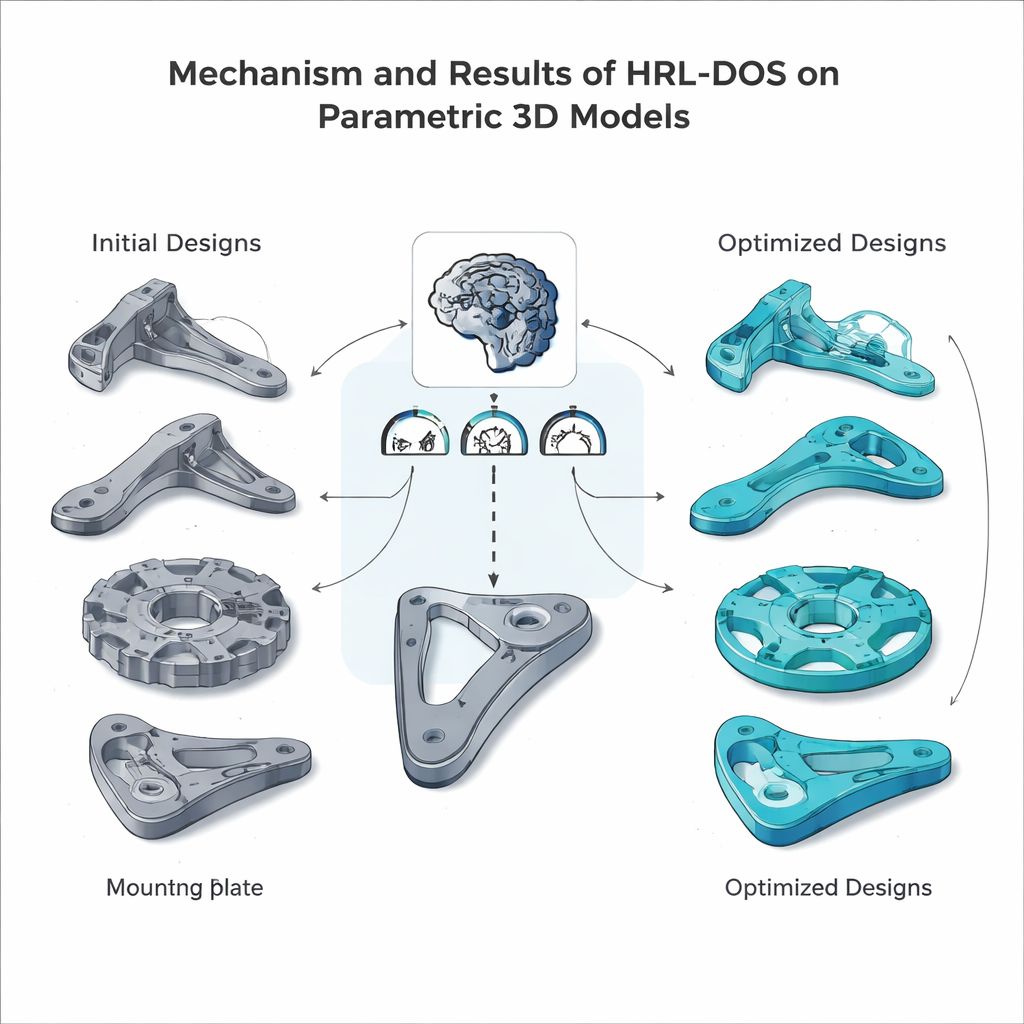
تصاميم قوية، قابلة للبناء ومرنة
بعيدًا عن الأداء الخام، ثبت أن HRL‑DOS أفضل في الالتزام بالحدود الهندسية الصارمة. ولّد عددًا أقل بكثير من التصاميم التي تنتهك قيود السلامة أو التصنيع وحقق درجات قابلية تصنيع أعلى عبر فحوص مثل زوايا التعليق، التجاويف الداخلية، والتحمّلات. كما عممت الطريقة جيدًا على أنواع قطع جديدة غير مرئية سابقًا وبقت قوية عندما كانت بيانات الإدخال مشوشة أو ناقصة جزئيًا — وهي صفة مهمة لتدفقات عمل التصميم الواقعية. توحي هذه النتائج معًا بأن التعلم المعزز الهرمي يمكن أن يعمل كمحرك عملي للتصميم بمساعدة الحاسوب الذكي، مما يساعد المعماريين والمهندسين على استكشاف خيارات أكثر في وقت أقل مع الحفاظ على نماذجهم آمنة وفعالة وجاهزة للتصنيع.
الاستشهاد: Zhong, G., Vijay, V.C. Reinforcement learning-driven dynamic optimization strategy for parametric design of 3D models. Sci Rep 16, 5041 (2026). https://doi.org/10.1038/s41598-026-35863-1
الكلمات المفتاحية: تصميم ثلاثي الأبعاد معامِدي, التعلم المعزز, تحسين التصميم, التصميم بمساعدة الحاسوب, الهندسة التوليدية