Clear Sky Science · ar
HEViTPose: نحو تقدير وضعية بشرية ثنائي الأبعاد عالي الدقة وفعّال باستخدام انتباه تخفيض فراغي جماعي متسلسل
تعليم الحواسيب قراءة لغة الجسد
من تطبيقات اللياقة البدنية إلى أنظمة مساعدة السائق، تعتمد العديد من التقنيات اليوم على قدرة الحاسوب على فهم كيفية تحرك الأشخاص. تُسمى هذه المهارة تقدير وضعية الإنسان، وتعني العثور على مواقع مفاصل الجسم — مثل الكتفين والركبتين والكاحلين — في صورة أو فيديو. التحدي هو تنفيذ ذلك بدقة وفي وقت كافٍ ليعمل بشكل فوري على أجهزة يومية. تقدم هذه الورقة HEViTPose، طريقة جديدة تهدف إلى الحفاظ على دقة عالية مع استخدام طاقة حسابية أقل مقارنةً بالعديد من الأنظمة الحالية.
لماذا يصعب تحديد المفاصل في الصور
قد يبدو تحديد مواقع مفاصل الجسم ببساطة: ابحث عن الذراعين والساقين. في الواقع، يظهر الأشخاص بأحجام مختلفة، وفي أوضاع غير اعتيادية، وفي مشاهد مزدحمة، وغالبًا خلف أشياء مثل الأثاث أو السيارات. تتعامل أنظمة تقدير الوضع الحديثة عادةً مع هذا بإنشاء «خريطة حرارية» مفصّلة لكل مفصل، حيث تشير البقع الساطعة إلى المواقع المحتملة. الخرائط الحرارية دقيقة جدًا لكنها مكلفة حسابيًا. تعتمد الأنظمة التقليدية في المقام الأول على الشبكات العصبية الالتفافية، التي تجيد اكتشاف الأنماط المحلية لكنها تحتاج لأن تصبح أعمق وأثقل لالتقاط العلاقات بعيدة المدى عبر الجسم بالكامل. النماذج المعتمدة على المحولات الأحدث متفوقة في التقاط تلك العلاقات بعيدة المدى، لكنها غالبًا ما تتطلب مجموعات بيانات كبيرة وحوسبة كثيفة، مما يصعّب استخدامها بشكل فوري أو على أجهزة أصغر.
لمحات متداخلة لرؤية أكثر سلاسة
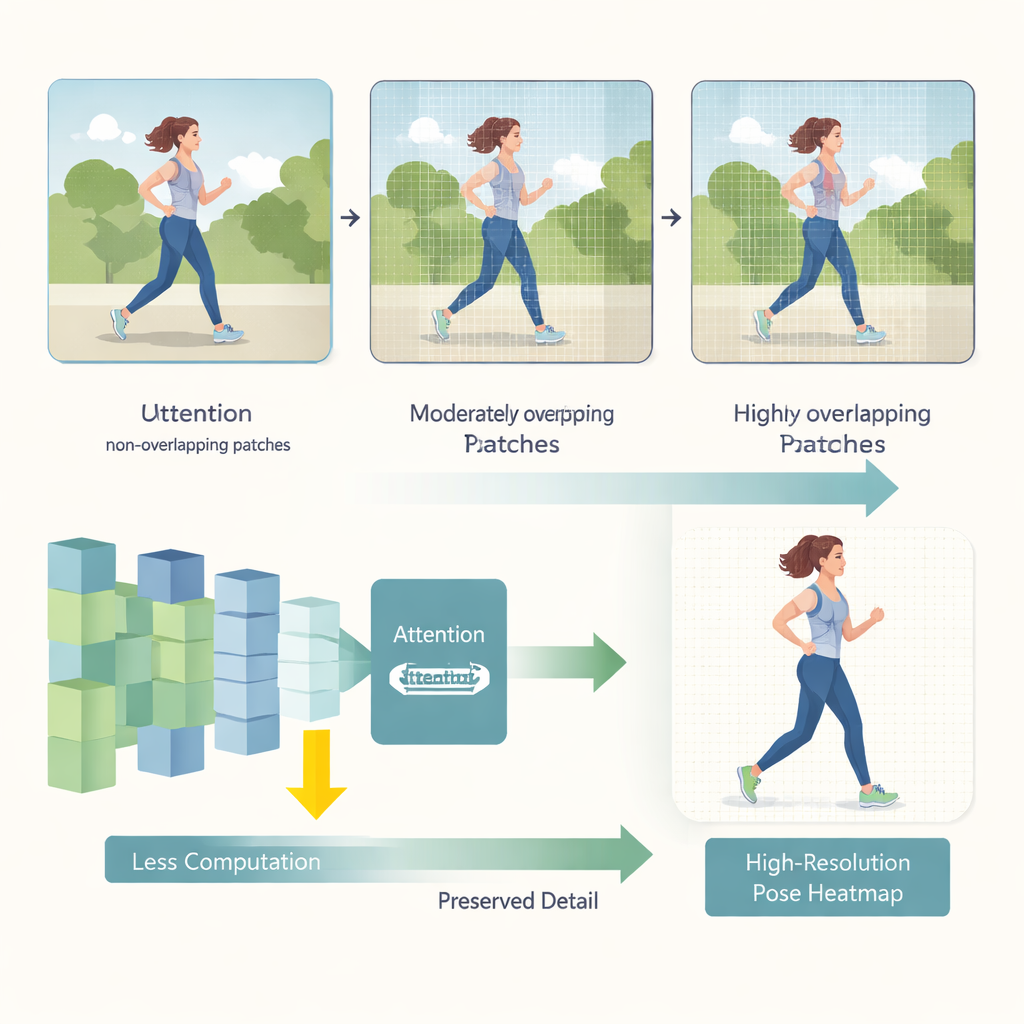
تبدأ HEViTPose بإعادة التفكير في كيفية تقطيع الصورة إلى قطع للتحليل. كثير من نماذج المحولات القديمة تقطع الصور إلى بلاطات غير متداخلة، مما قد يقطع الاستمرارية البصرية بين المناطق المجاورة — مثل قطع ذراع الشخص عند حافة بلاطة. تبني HEViTPose على فكرة تضمين البلاطات المتداخلة وتقدم مقياسًا أوضح وقابلًا للضبط يسمى عرض تداخل تضمين البلاطة (PEOW). يحصي PEOW ببساطة عدد البكسلات التي تتشاركها البلاطات المجاورة على طول حدودها. من خلال تغيير هذا التداخل بشكل منهجي، يبين المؤلفون أن تداخلاً معتدلاً يسمح للشبكة بـ"إحساس" أفضل بالتغير السلس في اللون والشكل من بلاطة إلى أخرى. تؤدي تلك الاستمرارية المحلية الأكثر ثراءً إلى تحديد مواقع المفاصل بدقة أكبر، دون زيادة كبيرة في حجم النموذج أو الحسابات.
انتباه أذكى مع عمل أقل
الابتكار الرئيسي الثاني هو وحدة انتباه جديدة تُسمى الانتباه متعدد الرؤوس بتخفيض فراغي جماعي متسلسل (CGSR-MHA). توجه آليات الانتباه الشبكة إلى أي أجزاء الصورة يجب أن تؤثر على كل توقع، لكنها عادةً ما تتوسع بشكل سيئ مع زيادة حجم الصور. يتعامل CGSR-MHA مع ذلك بثلاثة أساليب. أولاً، يقسم الميزات إلى مجموعات، بحيث يتعامل كل مجموعة مع جزء فقط من المعلومات بدلاً من كل شيء دفعة واحدة. ثانيًا، يقلل الدقة المكانية داخل كل مجموعة قبل حساب الانتباه، مما يخفض بشكل كبير عدد العمليات. ثالثًا، يستخدم عدة رؤوس انتباه صغيرة بدلًا من عدد قليل من الرؤوس الكبيرة، محافظًا على تنوّع ما يمكن أن "ينتبه" له النموذج مع إبقاء التكلفة منخفضة. وتحقق إعدادات مُختارة بعناية لعدد المجموعات ومعدل التخفيض وعدد الرؤوس توازنًا بين السرعة والدقة.
نماذج خفيفة لا تزال تنافس القمة
لاختبار HEViTPose، يقيم المؤلفون أداؤها على معيارين مستخدمين على نطاق واسع: مجموعة بيانات MPII للنشاطات البشرية اليومية ومجموعة COCO الأكبر التي تضم أشخاصًا في مشاهد متنوعة. عبر عدة أحجام للنماذج، تحقق HEViTPose دقة مساوية أو قريبة من أنظمة تقدير الوضع الرائدة مع استخدام عدد معاملات وعمليات حسابية أقل بكثير. على سبيل المثال، يصل أحد الإصدارات إلى دقة مماثلة لشبكة شهيرة عالية الدقة (HRNet) بينما يختصر عدد المعاملات القابلة للتعلم بأكثر من 60% ويقلل كمية الحساب بأكثر من 40%. بالمقارنة مع نموذج هجين حديث يمزج الالتفافات والمحولات، يقدم HEViTPose أداءً مشابهًا لكنه يعمل بسرعة أكبر بحوالي 2.6 مرة على معالج رسومي. تترجم هذه التوفيرات مباشرةً إلى أداء فوري أكثر سلاسة ومتطلبات أجهزة أقل.
ما يعنيه ذلك للتطبيقات اليومية
بعبارات بسيطة، تُظهر HEViTPose أننا لا نحتاج إلى الاختيار بين الدقة والكفاءة عند تعليم الحواسيب قراءة لغة جسم الإنسان. من خلال تداخل قطع الصورة التي تفحصها بعناية، وإعادة تصميم كيفية حساب الانتباه داخل الشبكة، يمكن للنظام تحديد المفاصل بدقة عالية مع البقاء صغيرًا وسريعًا. يجعل هذا النظام جذابًا للاستخدامات العملية مثل تتبع الرياضة، والمراقبة الفيديوية، والتفاعل بين الإنسان والروبوت، والرصد داخل السيارة، حيث تهم كل من السرعة واستهلاك الطاقة. كما أن الأفكار وراء HEViTPose — التداخل الأذكى والانتباه الفعّال — يمكن تكييفها أيضًا لمهام ذات صلة مثل تتبع وضعية الحيوانات أو اكتشاف معالم الوجه، مما قد يجلب "عيونًا رقمية" أكثر حدة إلى العديد من الأجهزة دون الحاجة إلى حوسبة بمستوى حاسوب فائق.
الاستشهاد: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
الكلمات المفتاحية: تقدير وضعية الإنسان, رؤية حاسوبية, محول بصري, تعلم عميق فعّال, آلية الانتباه