Clear Sky Science · ar
إطار هجين قائم على الشبكات الالتفافية والتعلم المعزز لتحديد المتحدث باستخدام ميزات الطيفية ميل وتحويل المويجة المستمر
لماذا يمكن أن يكون صوتك مفتاحًا رقميًا
تخيل فتح حسابك البنكي أو باب منزلك أو هاتفك باستخدام صوتك فقط. لكي يكون ذلك آمنًا، يجب أن تميّز الحواسيب بين الأشخاص بدقة، حتى في وجود ضوضاء خلفية أو عاطفة أو ميكروفون رديء. تستكشف هذه الورقة طريقة جديدة لتعليم الآلات التعرّف على المتكلم، وليس فقط ما يُقال، من خلال دمج حيل التعلم العميق الحديثة مع شكل من أشكال التعلم بالتجربة والخطأ المستعار من علم الروبوتات.
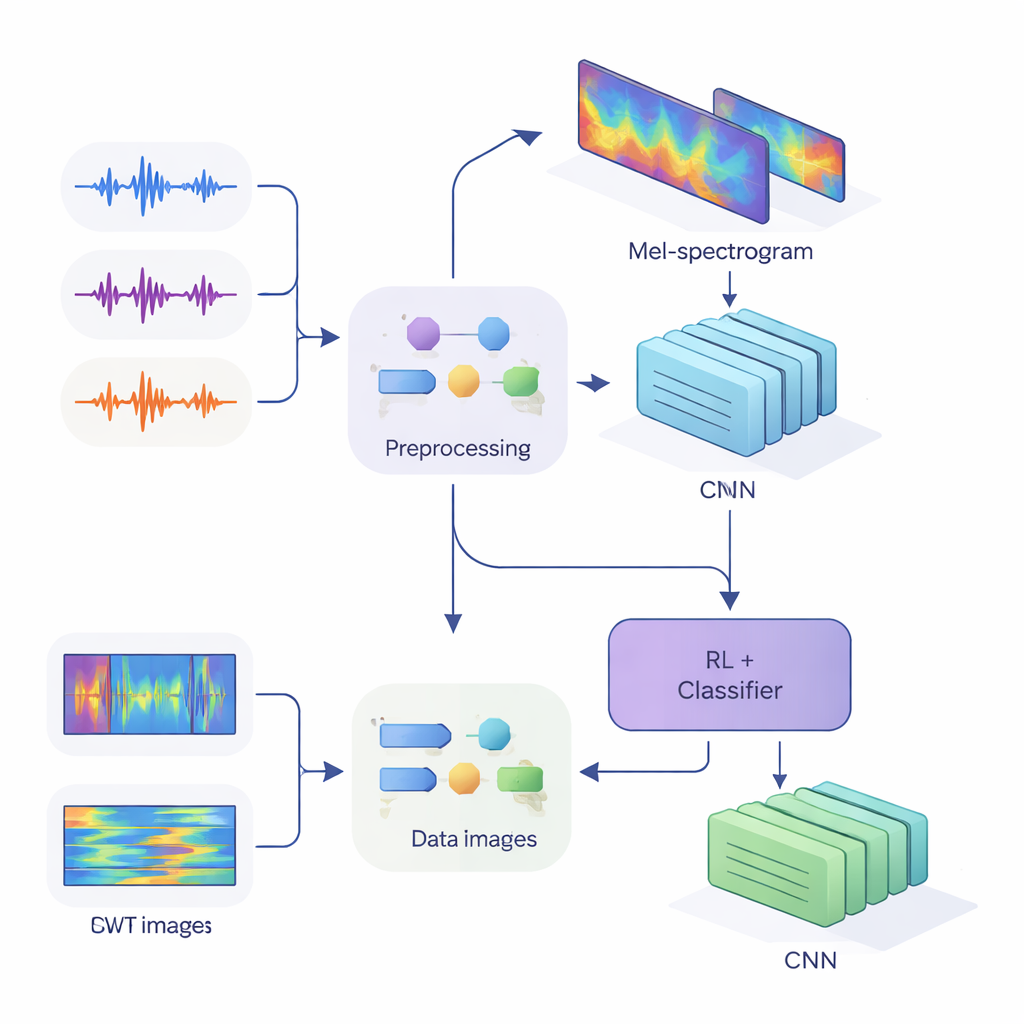
من موجات الصوت إلى بصمات صوتية
يحمل صوت كل شخص دلائل دقيقة تتشكل بحجم وشكل قناة الكلام، وطريقة اهتزاز الأحبال الصوتية، وأسلوب النطق. بدأ الباحثون بطرح سؤال: أي الخصائص القابلة للقياس في التسجيل الصوتي تختلف فعليًا من شخص لآخر؟ باستخدام 2703 مقطعًا صوتيًا من 40 متحدثًا باللغة الإنجليزية من مجموعة بيانات LibriSpeech، حللوا 22 ميزة صوتية بسيطة، مثل تباين الشدة، والطاقة في نطاقات ترددية مختلفة، والإيقاع، وقياس يسمى الإنتروبيا الذي يعكس مدى تعقيد أو عدم قابلية التنبؤ بالصوت. أظهرت الاختبارات الإحصائية أن 21 من هذه الميزات الـ22 تحمل معلومات مميزة عن المتحدث، مع بروز الإنتروبيا والطاقة عالية التردد كعوامل مميزة بشكل خاص. بكلمات أخرى، «بصمة» صوت الشخص موزعة عبر جوانب متعددة من الصوت، وليست مقتصرة على النغمة أو الحجم فقط.
طريقتان لتحويل الصوت إلى صور
لإدخال هذه الأدلة إلى الشبكات العصبية الحديثة، حوّل الفريق الصوت أحادي البعد إلى صور ثنائية البعد تلتقط كيف تتغير الطاقة عبر الزمن والتردد. في الطريقة الأولى، استخدموا طيفيات ميل، التي تحاكي كيف يجمع الأذن البشرية الترددات وتُستخدم عادة في تكنولوجيا الكلام. في الطريقة الثانية، استخدموا تحويل المويجة المستمر، وهو أسلوب أكثر مرونة يتيح التكبير على الأصوات القصيرة الحادة والصوائت الطويلة على حد سواء. بعد تنظيف الصوت بعناية—إزالة الصمت، وتوحيد مستوى الصوت، وإضافة تشويهات صغيرة مثل الضوضاء وتحويلات في النغمة لجعل النظام أكثر متانة—أنتجوا "صور" ميل بحجم 80×313 و"صور" مويجة بحجم 128×128، جاهزة للمعالجة بواسطة الشبكات الالتفافية (CNNs).
تعليم الشبكات على الاستماع والشك
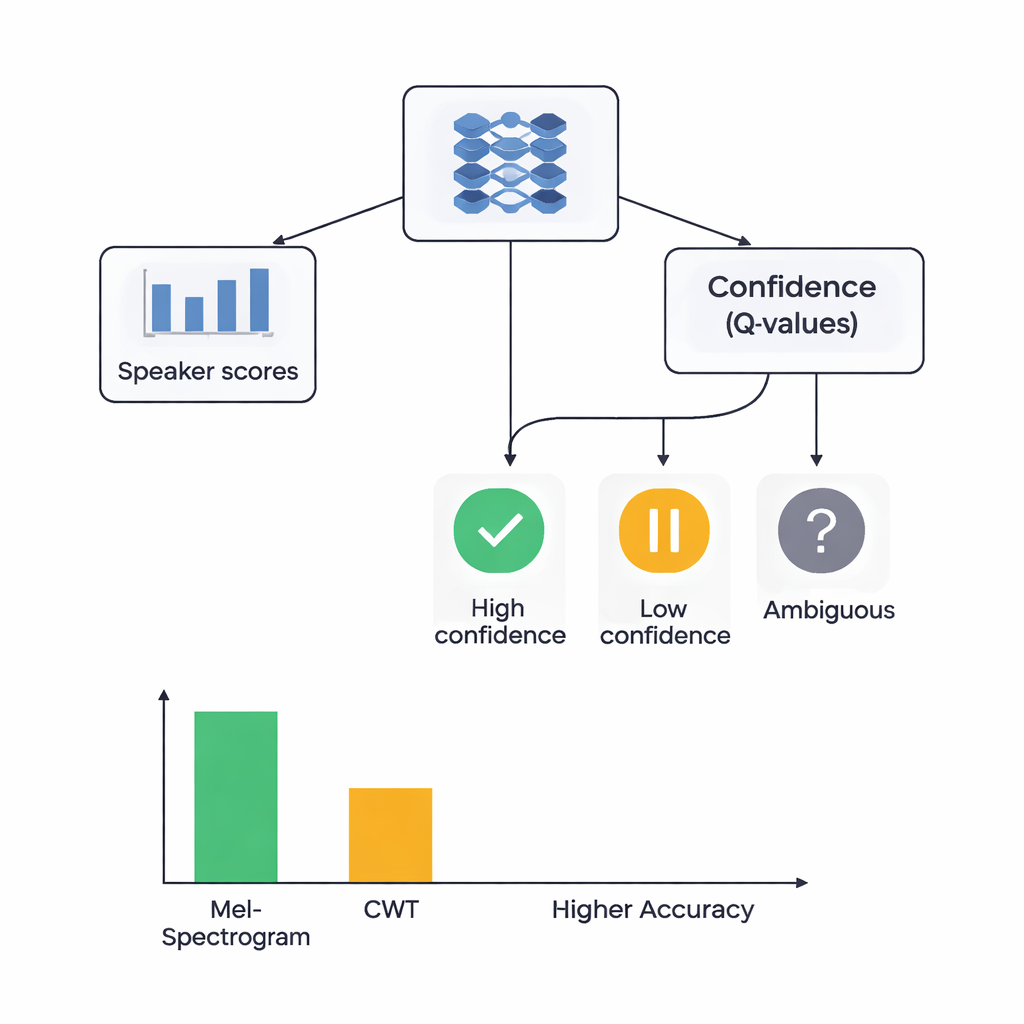
في جوهر الدراسة بنية هجينة تجمع بين نمطي تعلم. أولًا، تقوم الشبكات الالتفافية بمسح صور الميل أو المويجة لاستخراج أنماط تميل إلى الانتماء لمتحدثين محددين، على نحو مشابه لكيفية تعلم شبكات التعرف على الصور تمييز العيون أو الحواف. للنظام القائم على الميل، أضاف المؤلفون وحدة اهتمام ذاتي تسمح للشبكة بالتركيز على مقاطع الزمن الأكثر معلوماتية. وفوق مستخرجات الميزات هذه، وضعوا مكونًا من التعلم المعزز يتعلم مدى ثقة النظام في كل قرار. بدلًا من اتخاذ خيار حازم دائمًا، يخصص جزء التعلم المعزز قيمًا لإجراءات مثل «قبول هذا كخَمن عالي الثقة»، «التعامل معه كخَمن منخفض الثقة»، أو «وضع علامة كمبهم». على مدار جولات تدريبية عديدة، يكافأ عندما تكون القرارات الواثقة صحيحة، مما يدفع الشبكة نحو أحكام أفضل المعايرة.
ما مدى فعالية النظام الهجين؟
قارن الباحثون بين أربعة نماذج: نظام قائم على الميل مع التعلم المعزز، وآخر قائم على الميل بدون التعلم المعزز، ونظام قائم على المويجة مع التعلم المعزز، ونظام المويجة بدون التعلم المعزز. تم اختبارها جميعًا باستخدام تحقق متقاطع من خمس طيات بعناية، مما يعني أن كل مقطع صوتي خدم للتدريب والاختبار في جولات مختلفة. قدم نظام الميل مع التعلم المعزز أفضل أداء، حيث تعرف على المتحدث بشكل صحيح حوالي 88% من الوقت وأظهر فصلًا شبه مثالي بين المتحدثين وفق مقياس قياسي للقوة التمييزية. وصل نظام المويجة مع التعلم المعزز إلى نحو 78% دقة. والأهم من ذلك، أن إضافة مكون التعلم المعزز حسّن الأداء لكلا نوعي الميزات بحوالي 3 نقاط مئوية وجعل النتائج أكثر اتساقًا عبر تقسيمات البيانات المختلفة. حققت فئات متحدثين أكثر جودة تعرف عالية عندما شُمل التعلم المعزز، ما يشير إلى أن القرارات الواعية بالثقة ساعدت خصوصًا مع الأصوات الصعبة المتشابهة بسهولة.
ماذا يعني هذا لأمن الصوت في الحياة اليومية
لغير المتخصصين، الخلاصة أن فحوصات الهوية القائمة على الصوت الموثوقة تتطلب تمثيلات غنية للصوت وإحساسًا صحيًا بالشك من الآلة. تُظهر هذه العمل أن طيفيات الميل المستوحاة من الأذن، المجمعة مع وحدة اهتمام ومعلم معزز قادر على القول «لست متأكدًا»، تتفوق على صور المويجة الأكثر غرابة في مهمة تمييز المتحدثين. في حين أن الدراسة تستخدم مجموعة بيانات صغيرة ونظيفة نسبيًا وليست مُعدّة بعد لظروف العالم الحقيقي الصاخبة، فإنها تُبرهن أن إضافة طبقة واعية بالثقة فوق الشبكات العميقة يمكن أن يجعل مصادقة الصوت أكثر دقة ومصداقية—خطوة مهمة إذا كان من المقرر أن تصبح أصواتنا مفاتيح رقمية آمنة.
الاستشهاد: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
الكلمات المفتاحية: تحديد المتحدث, قياسات حيوية صوتية, التعلم العميق, التعلم المعزز, طيفيات ميل