Clear Sky Science · ar
إطار عام لتقليص الأبعاد غير المعلمي بشكل تكيفي
لماذا يهم تصغير البيانات الكبيرة
الحياة الحديثة تعمل بالبيانات: صور طبية، سجلات تسوق عبر الإنترنت، صور فوتوغرافية، خلاصة الأخبار، وغير ذلك. قد يحتوي كل سجل على مئات أو آلاف القياسات، ما يجعل تخزينها أو تحليلها أو حتى تصورها أمراً صعباً. يستخدم العلماء «تقليص الأبعاد» لضغط هذه التعقيدات إلى صور ونماذج أبسط مع الحفاظ على الأنماط المهمة. لكن الأدوات الشائعة اليوم غالباً ما تتطلب اختيارات يدوية كثيرة وتجارب متكررة. تقدم هذه الورقة طريقة تتيح للبيانات نفسها أن تقرر أفضل سبل التصغير، بهدف الحصول على صور أكثر وضوحاً، تعلم أدق، وقلّة تخمينات من جانب المستخدم.
من خطوط بسيطة إلى واقع منحنٍ
أداة كلاسيكية لتبسيط البيانات، تحليل المركبات الرئيسية، تعمل مثل تسليط ضوء على جسم وملاحظة ظله: تجد الاتجاهات المستوية الأفضل التي تفسر أكبر قدر من التباين. هذا يكون قويًّا عندما يكون بنية البيانات مستقيمة أو مستوية تقريباً. لكن البيانات الحقيقية — مثل الصور، النصوص، أو قراءات المستشعرات — غالباً ما تقع على أسطح منحنية مخفية داخل فضاء عالي الأبعاد. خلال العقدين الماضيين، صُممت طرق «غير خطية» جديدة مثل Isomap وLocally Linear Embedding (LLE) والتضمين الطيفي وUMAP خصيصاً لكشف هذه الأشكال المتعرجة. تعتمد على الجوار المحلي: لكل نقطة، ينظرون إلى أقرب جيرانها ويحاولون المحافظة على تلك العلاقات صغيرة النطاق عند رسم تمثيل منخفض البعد. مع ذلك، تجبر هذه الطرق المستخدم على اختيار مفتاحين أساسيين: كم عدد الجيران المراد استخدامها وكم بعداً للخفض. إذا خُيرت بشكل سيئ، يمكن أن تكون النتيجة مضللة أو مكلفة حسابياً.
السماح للبيانات باختيار جوارها بنفسها
يبني المؤلفون على أداة إحصائية حديثة تسمى مقدِّر البُعد الذاتي، الذي يحاول الإجابة عن سؤال بسيط: كم عدد الاتجاهات المستقلة التي تتباين البيانات فيها فعلاً، بعد إزالة الضوضاء؟ يمتد مقدِّرهم، المسمى ABIDE، إلى أبعد من ذلك. حول كل نقطة، يبحث تلقائياً عن جوار يبدو متجانساً نسبياً — لا صغيراً جداً ومليئاً بالضجيج ولا كبيراً جداً ومشوَّهاً. أثناء ذلك، يعيد معلومتين: تقديرًا عالمياً للبُعد الحقيقي للبيانات وحجم جوار مُخصص لكل نقطة. يحوّل هذا العدد الثابت المعتاد لـ«عدد الجيران» إلى كمية تكيفية محلياً يمكن أن تكبر في المناطق قليلة الكثافة وتتقلص في المناطق المكتظة، مواكبةً لكثافة البيانات الفعلية.
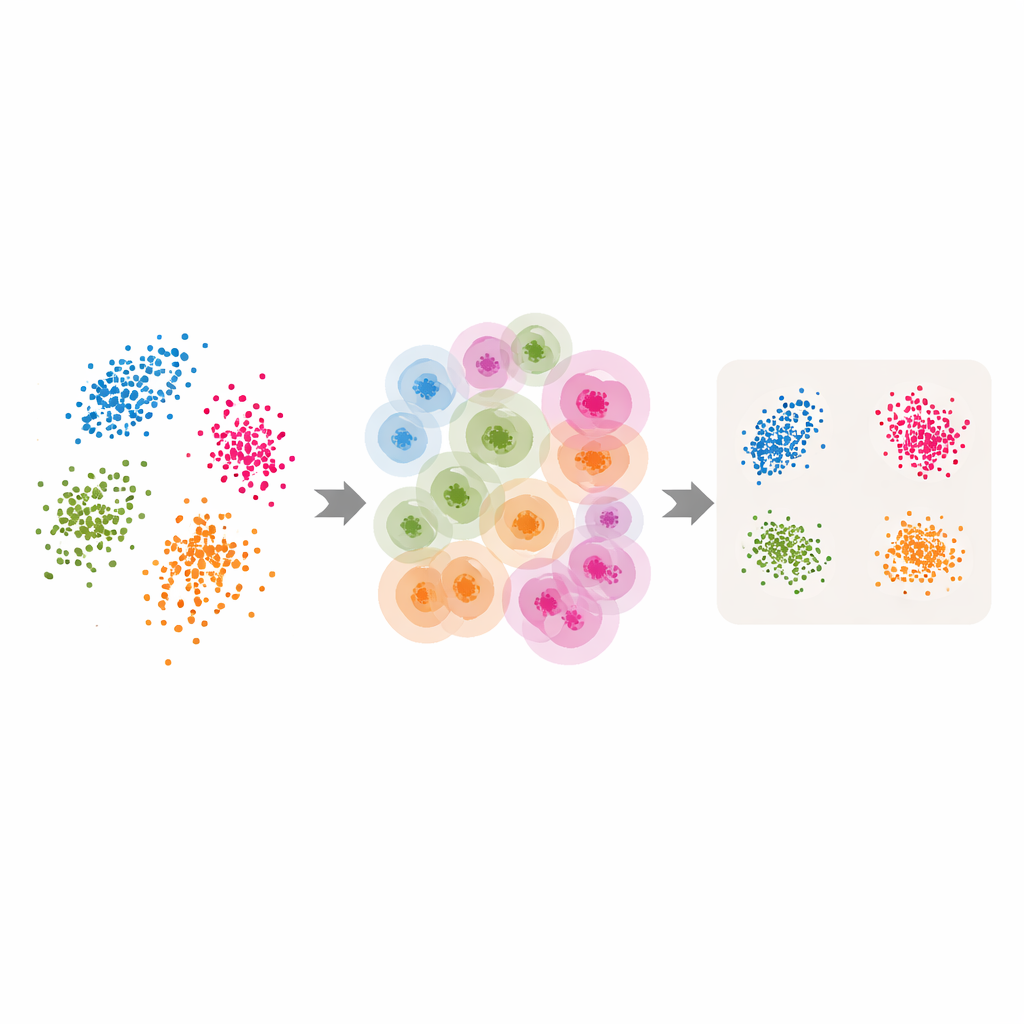
تحويل الأدوات الكلاسيكية إلى أدوات تكيفية
مزوَّدين بهذه الجوار التكيفية وتقدير البُعد الذاتي، يقوم المؤلفون بتعديل العديد من طرائق تقليص الأبعاد والتجميع الشّائعة. بالنسبة لـLLE، يستبدلون عدد الجيران الواحد الذي يختاره المستخدم بقيم لكل نقطة يعيدها ABIDE، ويضبطون البعد المستهدف ليطابق البُعد الذاتي المُقدّر. يتعلم الخوارزم كيفية إعادة بناء كل نقطة من مجموعة محلية مختارة بعناية قبل العثور على ترتيب منخفض البعد عالمي يحافظ بأفضل شكل على هذه البنايات المحلية. تُطبَّق أفكار مماثلة على التجميع الطيفي — حيث يُستخدم رسم بياني للتشابهات بين النقاط للتجميع — وعلى UMAP، الذي يبني خريطة غامضة لكيفية ترابط النقاط. في كل حالة، يُستبدل حجم الجوار الصارم بهيكل مرن مدفوع بالبيانات يتبع الهندسة الطبيعية للبيانات.
الاختبار على زهور وأرقام ونصوص وأشكال صناعية
لاختبار ما إذا كان هذا النهج التكيفي مجدياً، أجرى المؤلفون تجارب على عدة مجموعات معيارية: قياسات زهرة Iris الكلاسيكية، صور أرقام مكتوبة بخط اليد (MNIST)، مقالات إخبارية ممثلة بتضمينات نموذج اللغة، وأشكال ثلاثية الأبعاد صناعية مع ضوضاء مضافة. يقارنون النسخ التكيفية مقابل إعدادات البرامج القياسية وضد شبكات من المعاملات المضبوطة بعناية. في المهام غير المراقبة مثل التجميع والتصوير، تُنتج الطرق التكيفية عادةً مجموعات أوضح، تجمعات أكثر إحكاماً، ودرجات أفضل في مقاييس الجودة القياسية. على سبيل المثال، في متعددات السطوح المعقدة ذات كثافة نقاط غير متساوية، تستعيد الطرق التكيفية البنية الحقيقية أفضل بكثير من النسخ ذات الجيران الثابتين. في الاختبارات المراقبة، حيث تُغذى البيانات المُخفضة إلى مُصنِّف، يطابق النهج التكيفي أو يتفوق مرة أخرى على أفضل الخيارات ذات الإعداد الثابت، دون الحاجة إلى ضبط موسع.
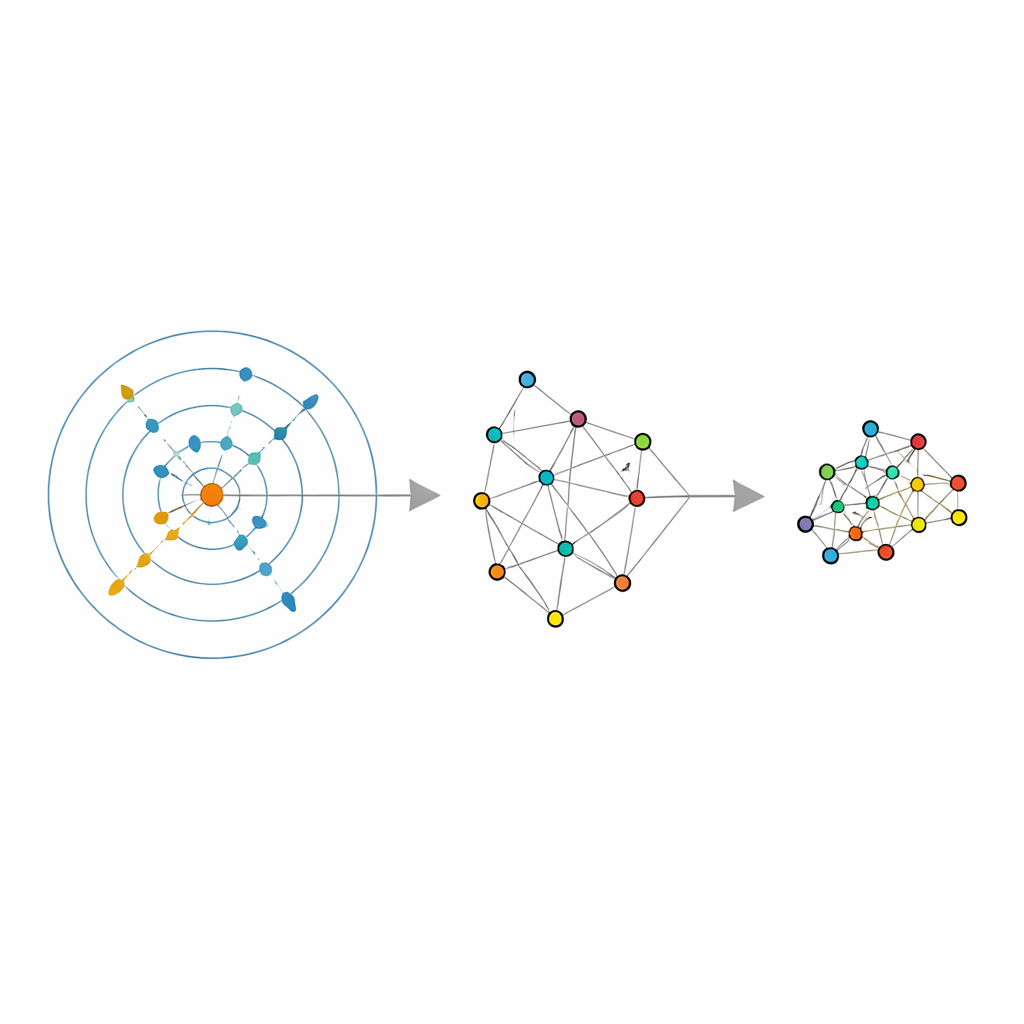
ماذا يعني هذا لتحليل البيانات اليومي
لغير الخبراء والممارسين على حد سواء، الرسالة الرئيسة هي أن تصغير البيانات لا يجب أن يعتمد على التخمين. باستخدام هندسة البيانات نفسها لتقرير «كم عدد الجيران» و«كم بعداً»، يحول هذا الإطار أدوات مستخدمة على نطاق واسع مثل LLE والتجميع الطيفي وUMAP إلى نسخ أذكى وأكثر متانة من نفسها. النتيجة هي مشاهد منخفضة البعد أكثر موثوقية — مخططات وسمات تعكس بشكل أفضل الشكل الحقيقي للبيانات — بينما تقل غالباً المدة المخصصة لعمليات البحث اليدوية عن المعاملات الفائقة. عملياً، يعني هذا أن مهام مثل تصور مجموعات صور كبيرة، تجميع الوثائق، أو تحضير مُدخلات لنماذج تنبؤية يمكن أن تصبح أسهل وأكثر موثوقية، ببساطة عبر ترك البيانات توجه بشكل تكيفي كيفية ضَغْطها.
الاستشهاد: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
الكلمات المفتاحية: تقليص الأبعاد, تعلم متعدد الأبعاد (manifold learning), أقرب الجيران, البُعد الذاتي, تصوير البيانات