Clear Sky Science · ar
متعقب سيامي ذو فرعين معزز بالمحولات مع انحدار واعٍ بالثقة وتحديث قالب تكيفي
تدريب الحواسيب على تتبع جسم واحد في مشهد مزدحم
من السيارات الذاتية القيادة إلى كاميرات الأمن المنزلية والطائرات المسيرة، تحتاج العديد من الأجهزة الحديثة إلى تتبع جسم متحرك واحد عبر عالم مزدحم ومتغير. هذه المهمة، المسماة تتبع الأجسام البصرية، تبدو بسيطة للبشر لكنها صعبة بشكل مدهش للآلات: قد يمر أشخاص أمام الكاميرا، يتغير الإضاءة، يصغر الجسم بالابتعاد أو يختفي مؤقتًا. تقدم هذه الورقة نظام TSDTrack الجديد الذي يستفيد من التطورات الحديثة في التعلم العميق والمحولات للبقاء متشبثًا بالهدف بمزيد من الاعتمادية في مثل هذه ظروف العالم الحقيقي.
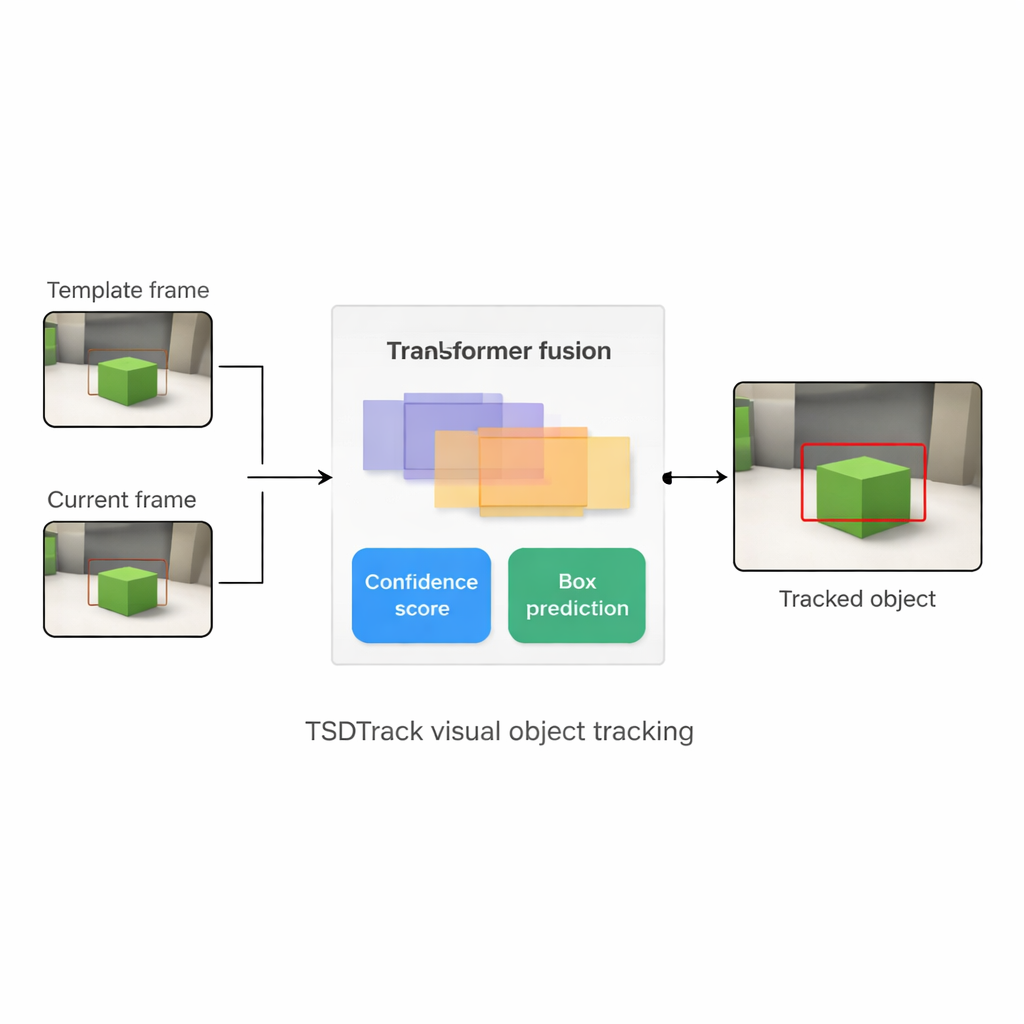
لماذا تتبع شيء واحد صعب جدًا
عادة يرى المتعقب الجسم بوضوح فقط في الإطار الأول من الفيديو، ثم يجب عليه الاستمرار في إيجاده مع تغير المشهد. اعتمدت الطرق التقليدية إما على ميزات صورة مصممة يدويًا أو على شبكة عصبية تقارن الإطار الأول ("القالب") بكل إطار جديد. كانت لهذه الأنظمة القديمة ثلاث نقاط ضعف كبيرة. أولًا، غالبًا ما بقي القالب الأصلي ثابتًا، فإذا استدار الجسم أو تعرض للتغطية جزئيًا أو تغير حجمه، واجه المتعقب صعوبة. ثانيًا، ركزت كثيرًا على مستوى واحد من التفاصيل في الصورة، مفقِدةً مزيج الحواف الدقيقة والسياق الأوسع الذي يساعد البشر على التعرف على الأشياء. ثالثًا، لم تكن تعرف متى تشك في نفسها: كانت تنتج صندوقًا حول الجسم المفترض بدون شعور واضح بمدى موثوقية هذه النتيجة، مما جعلها عرضة للانحراف نحو الخلفية.
مزاوجة السياق العام مع التفاصيل الدقيقة
يتعامل TSDTrack مع هذه المشكلات من خلال دمج إعداد تتبع "سيامي" التقليدي مع محول، وهو نفس نوع النموذج المعتمد على الانتباه الذي غيّر مهام اللغة والرؤية. يستخدم النظام شبكة عميقة لاستخراج الميزات من مدخلين: قطعة صغيرة تحدد الهدف وقطعة أكبر تحتوي منطقة البحث الحالية. بدلاً من الاعتماد على مقياس ميزة واحد، يستخلص معلومات من طبقات متعددة في الشبكة، تمثل الحواف والأشكال ونماذج المستوى الكائني. ثم يتعلم وحدة دمج معتمدة على المحول كيفية مزج هذه الطبقات بحيث يفهم المتعقب أين الأشياء في الصورة وكيف ترتبط بالسياق الأوسع. يساعد ذلك على تمييز الهدف عن الأشياء المتشابهة والفوضى، حتى عندما تكون الرؤية ضوضائية أو مُسدَلة جزئيًا.
معرفة مدى ثقة المتعقب في نفسه
جوهر TSDTrack هو رأس تنبؤ ذو فرعين يقسّم المهمة إلى سؤالين مترابطين: "أين الجسم؟" و"إلى أي مدى يجب أن نثق في هذه الإجابة؟" يقدر أحد الفروع درجة الثقة التي تعكس ليس فقط مدى تشابه مظهر الهدف، بل أيضًا مدى تداخل المربع المتوقع مع المناطق المرجحة أن تكون جسمًا. يعامل الفرع الآخر إحداثيات الصندوق ليست كتخمين واحد صلب، بل كتوزيع احتمالي على عدة مواضع ممكنة، مما يسمح للنموذج بتمثيل عدم اليقين. عندما تكون الصورة واضحة، يصبح التوزيع حادًا ويكون الصندوق دقيقًا؛ عندما يكون الجسم ضبابيًا أو مخفيًا جزئيًا، ينتشر التوزيع. تقود هذه النظرة الاحتمالية إلى وضع صناديق أكثر سلاسة واستقرارًا مقارنةً بالمتعقبين الأقدم الذين كانوا يقدمون تنبؤًا واحدًا جامدًا.
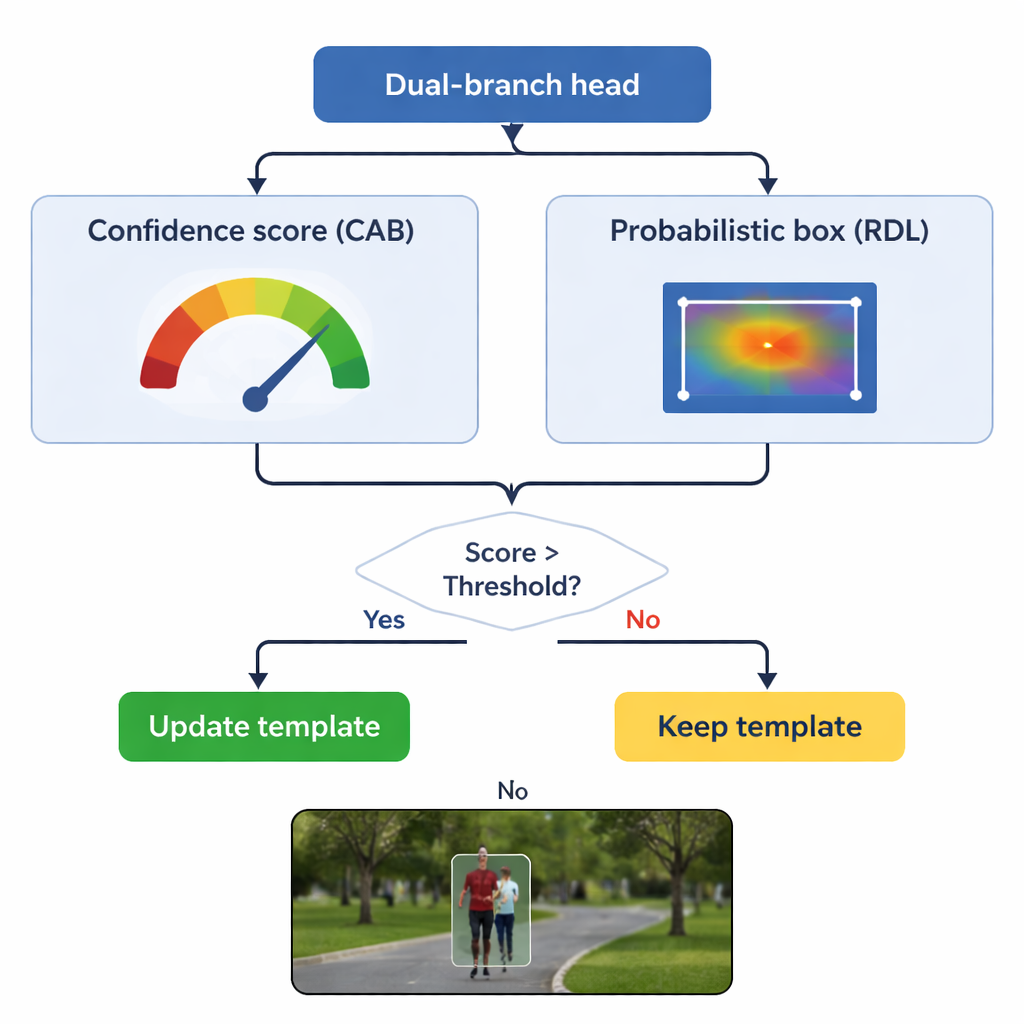
تحديث الذاكرة دون نسيان الأصل
خطر رئيسي في التتبع هو "انحراف القالب": إذا استمر النموذج في تحديث فكرته عن الجسم باستخدام إطارات سيئة، فقد يتعلم تدريجيًا الخلفية بدلًا من الهدف. يتعامل TSDTrack مع هذا من خلال جعل فرع الثقة يعمل كحارس بوابة. يحدث النظام قالبَه الداخلي فقط عندما تكون درجة الثقة فوق عتبة مختارة، وحتى في تلك الحالة يمزج المعلومات الجديدة بلطف مع العرض الأصلي بدلاً من استبداله تمامًا. يسمح هذا التحديث الانتقائي للمتعقب بالتكيف مع التغيرات الحقيقية، مثل استدارة شخص أو دوران سيارة، دون أن يخدعه الانسدادات المؤقتة أو التشتيتات. كما يُحتفظ بالقالب الأصلي كمرجع مستقر في حال تبين أن التحديثات اللاحقة مضللة.
ماذا تعني النتائج على أرض الواقع
اختبر المؤلفون TSDTrack على عدة معايير تتبع مستخدمة على نطاق واسع، بما في ذلك الفيديوهات الطويلة، والحركات السريعة، ولقطات جوية من طائرات مسيرة، والمشاهد ذات الفوضى الشديدة. عبر هذه الاختبارات، تفوق الأسلوب الجديد باستمرار على العديد من المتعقبين الرائدين من حيث الدقة (مدى قرب الصندوق من الجسم الحقيقي) والموثوقية (مدى ندرة فقدان الجسم تمامًا)، بينما ظل سريعًا بما يكفي للاستخدام في الزمن الحقيقي على الأجهزة الحديثة. للخلاصة غير المتخصصة: يمكن لـ TSDTrack أن يحافظ على تتبعه لهدف مختار بمزيد من الاعتمادية في ظروف الكاميرات الواقعية والفوضوية. من خلال مزج استدلال متعدد المقاييس بالمحول، وإحساس بالثقة الذاتية، وتحديثات قالب حذرة، يقدم هذا العمل لبنة أكثر موثوقية لتطبيقات مثل القيادة الذاتية، والمراقبة الذكية، والروبوتات الذكية.
الاستشهاد: Sachin Sakthi, K.S., Jeong, J.H. & Choi, W.Y. Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating. Sci Rep 16, 5170 (2026). https://doi.org/10.1038/s41598-026-35692-2
الكلمات المفتاحية: تتبع الأجسام البصرية, التتبع المبني على المحولات, شبكات سيامي, رؤية حاسوبية, أنظمة مستقلة