Clear Sky Science · ar
توليد صور فنية ملونة موجهة بصريًا باستخدام GAN محسن
لماذا تهم آلات الفن الأكثر ذكاءً
يمكن للأدوات الرقمية الآن رسم بورتريهات ومناظر طبيعية ومشاهد تجريدية في ثوانٍ، ومع ذلك تبدو العديد من هذه الأعمال الفنية التي يولدها الذكاء الاصطناعي غير دقيقة قليلًا—تتعارض الألوان، وتشعر الخامات بمستوى سطحي، أو لا يطابق «الأسلوب» ما يتصوره الناس تمامًا. تعرض هذه الورقة طريقة جديدة لتعليم الحواسيب إنشاء أعمال ملونة أكثر غنىً وتماسكًا وأقرب إلى اللوحات الحقيقية، مع السماح للمستخدمين بتوجيه النتيجة بإشارات بصرية بسيطة مثل الرسومات والخيارات اللونية. الهدف هو جعل الذكاء الاصطناعي شريكًا إبداعيًا أكثر موثوقية للفنانين والمصممين والمستخدمين العاديين الذين يريدون فنًا مخصصًا دون الحاجة لسنوات من التدريب.
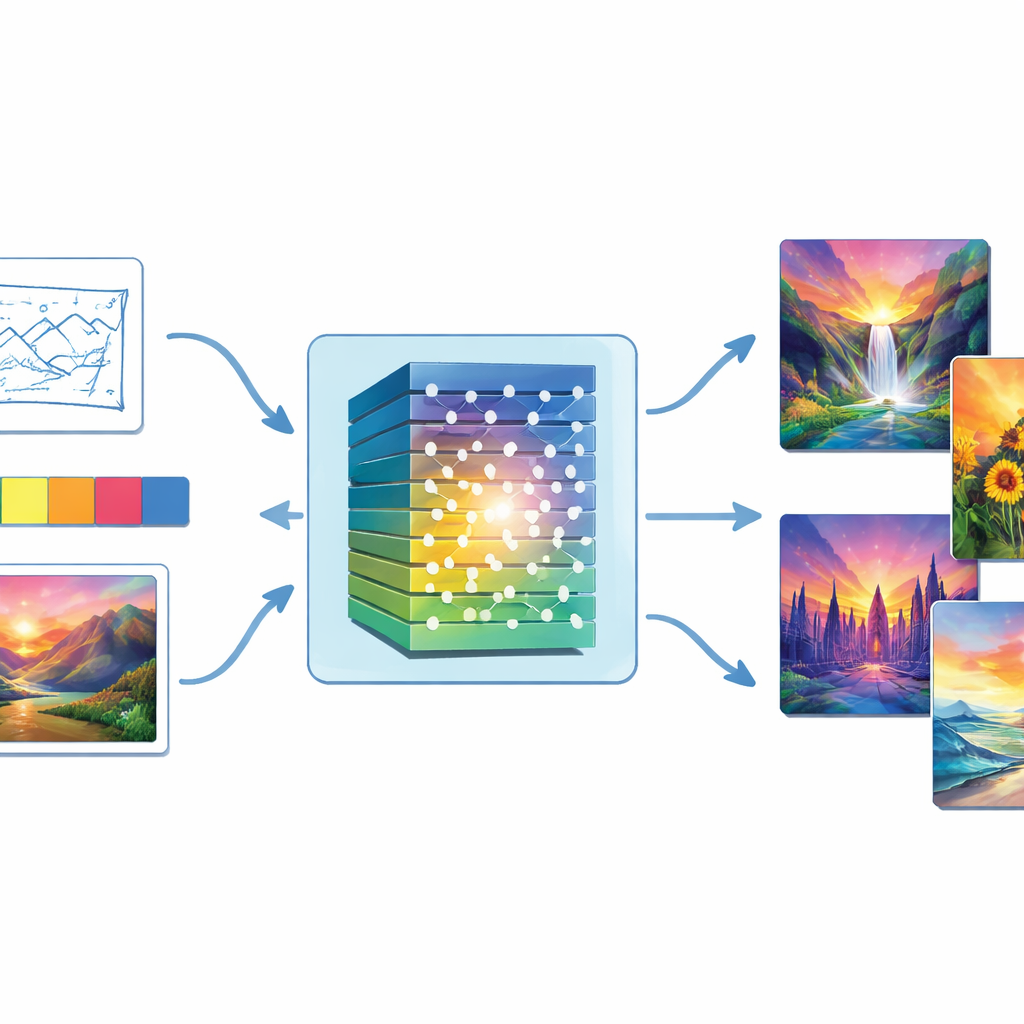
من الضوضاء العشوائية إلى اللوحات المكتملة
في قلب الدراسة نوع من الذكاء الاصطناعي يسمى الشبكة التنافسية التوليدية، أو GAN. تُبنى GAN من جزأين متقابلين: «المولّد» الذي يحاول إنتاج صور مقنعة من ضوضاء عشوائية، و«المميّز» الذي يقيم ما إذا كانت الصورة تبدو حقيقية أم مزيفة. عبر جولات عديدة من التدريب التفاعلي، يتحسن المولّد في خداع المميّز، وتصبح الصور تدريجيًا أكثر واقعية. يعزز المؤلفون هذه الفكرة الأساسية بإدراج طبقة معالجة صور عميقة—تُدعى شبكة عصبية التفافية—داخل كل من المولّد والمميّز، حتى يتمكن النظام من التقاط كل شيء من الأشكال العامة وصولًا إلى التفاصيل الدقيقة شبيهة الفرشاة.
تعليم النظام أين ينظر
بينما يمكن للشبكات التنافسية التقليدية إنتاج صور حادة، غالبًا ما تفوتها الصورة الكبرى: فقد تفرط فيما يتعلق بالتفاصيل الصغيرة وتفقد البنية العامة، أو تفشل في الحفاظ على أسلوب فني متسق. لمعالجة ذلك، أضاف الفريق آلية انتباه تكيفية. يحلل هذا المكوّن خرائط الميزات الداخلية للمولّد ويتعلم، أثناء التدريب، أي مناطق الصورة هي الأكثر أهمية في كل لحظة. ثم يعزز تلك المناطق الرئيسية—مثل الحواف والخامات والأجسام المحورية—بينما يخفف من المناطق الخلفية الأقل أهمية. تقيس وظائف خسارة خاصة مدى تطابق الصورة المولّدة مع أسلوب وملمس العمل الفني المرجعي، مما يدفع النموذج لموازنة المحتوى القابل للتعرف مع مظهر فني متماسك.
توجيه الآلة بإشارات بصرية
على عكس الأنظمة المعتمدة على النص فقط، تتيح هذه المقاربة للناس توجيه العمل الفني بإرشاد بصري مباشر. يمكن للمستخدمين تقديم رسمة لتحديد التكوين، لوحة ألوان لتعيين المزاج، صورة نمطية للاقتداء بها، أو علامات بسيطة للمشهد. تدخل هذه المدخلات إلى المولّد جنبًا إلى جنب مع الضوضاء العشوائية. ثم يحسب النموذج خواص لونية مثل الصبغة والتشبع والسطوع، ويعدّل مخرجه بحيث تحترم اللوحة النهائية نوايا المستخدم اللونية والأسلوب المرجعي معًا. كما يقوم هدف مطابقة الألوان بتقوية الصلة بين ما يشير إليه المستخدم وما ينتجه النظام، حتى لا تتحول، على سبيل المثال، مشهد بحري أزرق بارد إلى غروب دافئ بشكل غير متوقع.
التعلّم للتحسن من خلال المحاولة والخطأ
يذهب النظام خطوة أبعد باستخدام التعلم التعزيزي العميق، وهي تقنية مستوحاة من التعلم بالمحاولة والخطأ. هنا، يتعامل مكوّن اتخاذ القرار المنفصل مع الفجوة بين المخرج الحالي والإرشاد المستهدف كـ«حالة»، ويقترح تعديلات صغيرة على عناصر مثل قوة الرسمة أو أوزان لوحة الألوان كـ«إجراءات». بعد كل تغيير، يقيس النظام مقدار تحسن مقاييس جودة الصورة المهمة—مثل نسبة الإشارة لأعلى نسبة للضوضاء، والتشابه البنيوي، وخسارة الأسلوب—ويستخدم ذلك كإشارة مكافأة. مع مرور الوقت، يتعلم هذا الحلقة سياسة تضبط الإرشاد تلقائيًا لدفع المولّد نحو صور دقيقة بصريًا ومتسقة فنيًا.
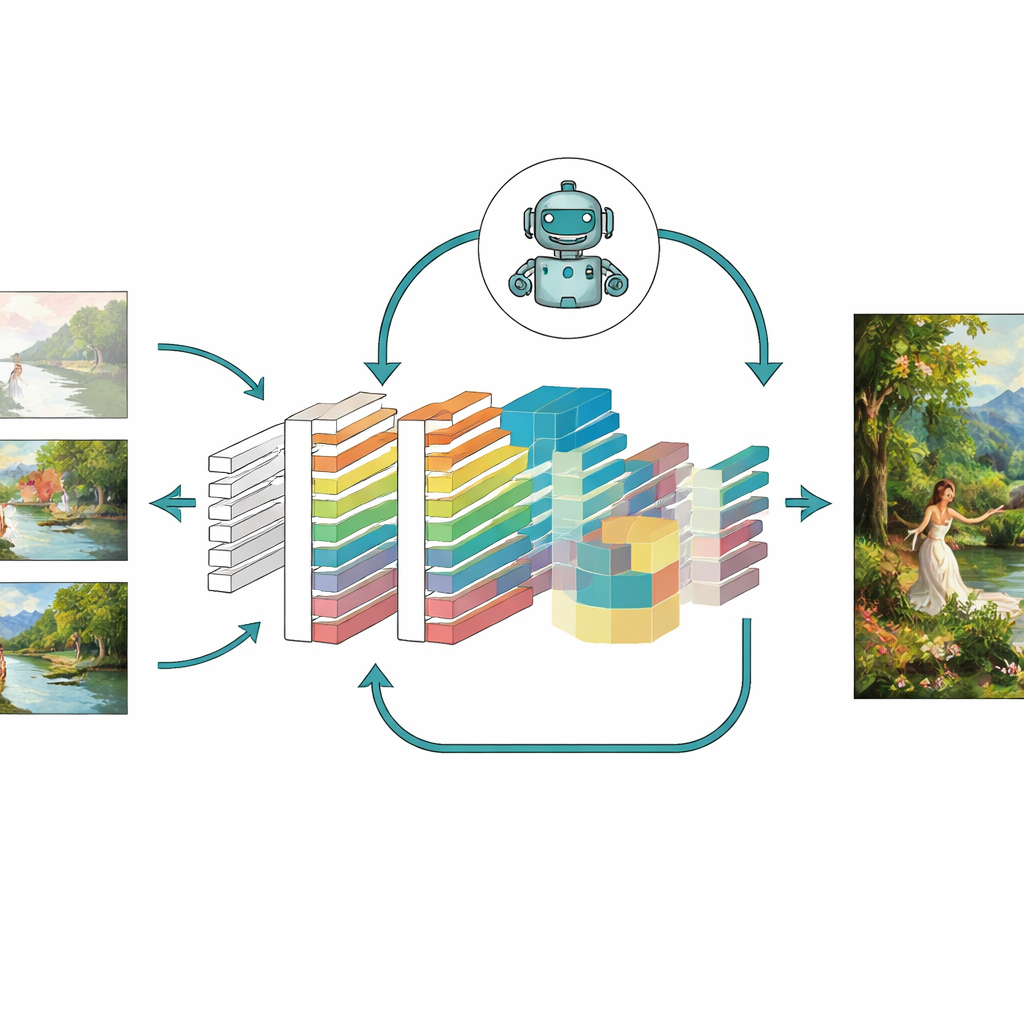
اختبار النموذج
لتقييم ما إذا كانت هذه الأفكار مفيدة فعلاً، اختبر المؤلفون نموذجهم المحسن—الذي أسموه CNN-GAN—على مجموعة كبيرة من اللوحات من جامعة أكسفورد وعلى مجموعة مخصصة تضم أكثر من 5000 عمل ملون بأنماط مثل البورتريه والمناظر الطبيعية والمشاهد التجريدية. قارنوا النتائج مع عدة أنظمة معروفة، بما في ذلك متغيرات GAN الكلاسيكية، والمشفّرات التلقائية، وحتى مولّدات حديثة قائمة على الانتشار. عبر العديد من المقاييس، أنتج النموذج الجديد صورًا أكثر حدة مع تشوّهات أقل، وتطابقًا بنيويًا أقرب للأعمال الحقيقية، ومسافة إدراكية أقل عن الصور المرجعية، وتنوعًا أعلى في أنواع المشاهد التي يمكنه توليدها. أظهرت دراسات الإزالة، التي أزالت مكوّنًا واحدًا في كل مرة، أن الانتباة والتعلم التعزيزي وتصميم الخسارة المدمج أسهم كلٌ منها بتحسينات ذات مغزى، ومعًا قدمن أقوى أداء.
ما الذي يعنيه هذا لأدوات الإبداع المستقبلية
بعبارات يومية، تصف الورقة آلة رسم لا تتعلم فقط من آلاف الأعمال الفنية، بل تولي أيضًا اهتمامًا خاصًا للمناطق المهمة، وتستمع إلى التلميحات البصرية للمستخدمين، وتعلّم تدريجيًا كيفية تعديل هذه التلميحات لتحقيق نتائج أفضل. النتيجة هي ذكاء اصطناعي قادر على توليد صور عالية الجودة وموحدة الأسلوب بشكل أكثر موثوقية من الطرق السابقة، مع ترك مساحة للتوجيه البشري. على الرغم من أن النظام لا يزال يواجه صعوبة مع الخامات المعقدة للغاية ويعتمد على بيانات تدريب كبيرة، يقترح المؤلفون امتدادات مستقبلية—مثل وحدات متعددة المقاييس وشبكات أخف وزناً—لجعله أكثر كفاءة وقابلية للاستخدام على نطاق واسع. تشير هذه التقدّمات معًا إلى أدوات فنية بالذكاء الاصطناعي أسرع، وأكثر وفاءً لنوايا المستخدم، وأفضل في التقاط الطابع الدقيق للوحات البشرية الصنع.
الاستشهاد: Wu, Z. Visual guided AI color art image generation using enhanced GAN. Sci Rep 16, 9345 (2026). https://doi.org/10.1038/s41598-026-35625-z
الكلمات المفتاحية: توليد الفن بالذكاء الاصطناعي, نقل نمط الصورة, الشبكات التنافسية التوليدية, الإبداع الاصطناعي, توليف الصور العصبي