Clear Sky Science · ar
التعرُّف المؤتمت على الكيانات الطبية الحيوية ذات الصلة سياقيًا باستخدام نماذج لغة كبيرة مؤسَّسة
لماذا يهم وسم الأوراق الطبية بذكاء أكبر
يصدر كل عام آلاف الدراسات الطبية الحيوية، تحوي كل منها تفاصيل عن الجينات وأنواع الخلايا والأمراض والعلاجات. ومع ذلك، يبقى معظم هذه المعلومات محتجزًا داخل ملفات PDF طويلة، مما يصعّب على العلماء الآخرين العثور على البيانات الدقيقة التي يحتاجونها. تستعرض هذه المقالة كيف يمكن للذكاء الاصطناعي الحديث — نماذج اللغة الكبيرة — استخراج المصطلحات الطبية الحيوية الأساسية من الأوراق البحثية تلقائيًا، للمساعدة في تحويل المنشورات المبعثرة إلى موارد منظمة وقابلة للبحث.
من أوراق فوضوية إلى لبِنات قابلة للبحث
تعتمد مراكز البحوث الطبية الحيوية، مثل مراكز الأبحاث التعاونية في ألمانيا، على بيانات واضحة ومهيكلة لجعل الدراسات قابلة لإعادة الاستخدام لسنوات قادمة. تقليديًا، كان على الباحثين وسم مجموعات بياناتهم يدويًا بكيانات مهمة مثل الكائنات، وسلالات الخلايا، والجينات — وهي مهمة مرهقة وتستغرق وقتًا طويلاً. يمكن لنماذج اللغة الكبيرة قراءة النصوص الكاملة وفهم السياق، مما يجعلها أدوات واعدة لأتمتة هذا الوسم. لكن ثمة نقطة مهمة: تحديد أي المصطلحات ذات صلة حقًا يعتمد على السؤال العلمي وكيف ستُعاد استخدام البيانات. عمل المؤلفون ضمن مخطط بيانات وصفية مصمم بعناية من مشروع CRC الموجَّه نحو أمراض الكلى «NephGen»، الذي يوجّه الذكاء الاصطناعي بشأن أنواع الكيانات المطلوب البحث عنها وكيفية تنظيمها.
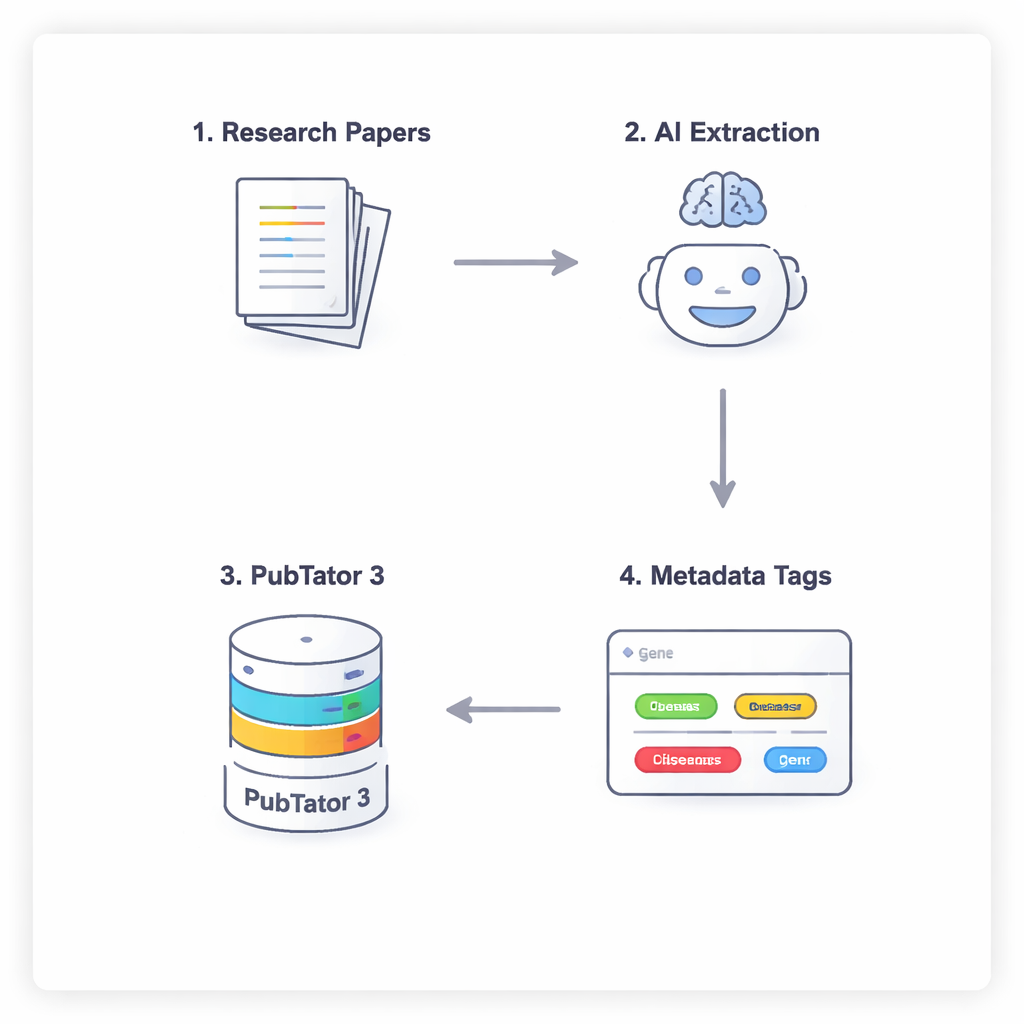
حوار من أربع خطوات بين الذكاء الاصطناعي وقاعدة بيانات حيوية
لمنع الذكاء الاصطناعي من التخمين أو «الهلاوس» في الحقائق الطبية الحيوية، استخدم الباحثون عملية من أربع خطوات تجبر النماذج على الاستدلال بعناية والتحقّق من نفسها. أولاً، يمسح النموذج النص الكامل للورقة (مع تجاهل المناقشة والمراجع) ليقترح كيانات قد تكون ذات صلة. ثانيًا، يجب عليه استشارة أداة خارجية، PubTator 3، وهي قاعدة بيانات طبية حيوية كبيرة، للتأكد من أن كل مصطلح مقترح موجود فعلاً ويحمل معرفًا معترفًا به. ثالثًا، يعيّن الذكاء الاصطناعي كل كيان مؤكد إلى خانة في مخطط البيانات الوصفية لـ NephGen، الذي يجمع الكيانات في بنية هرمية مصممة بواسطة البشر. أخيرًا، يجمع النموذج كل ذلك في مخرَج JSON منظم، وهو ملخّص قابل للقراءة الآلية للكيانات الطبية الحيوية الرئيسية في المقال.
اختبار ثمانية نماذج ذكاء اصطناعي باستخدام أبحاث كلوية حقيقية
طبّق الفريق سير العمل هذا عبر واجهات برمجة تطبيقات لأربعة عشر نموذج لغة كبير مختلف، ووجد أن ثمانية منها فقط قادرة بشكل موثوق على اتباع المتطلبات الصارمة، مثل إرجاع JSON صالح واستخدام الأدوات بشكل صحيح. ثم طبقوا هذه النماذج الثمانية على ستة مقالات بحثية في أمراض الكلى وطلبوا من كل مؤلف مراجعة القائمة النهائية للكيانات التي أنتجها الذكاء الاصطناعي في مقابلة وجهاً لوجه قصيرة. وبما أنه لا يوجد عدد «صحيح» محدد من الكيانات لاستخراجها، ركّز المؤلفون على الدقّة: أي نسبة الكيانات المقترحة التي حكم عليها العلماء بأنها صحيحة. باستخدام أساليب التحليل التلوي الإحصائي المعدلة للنسب القريبة من 100%، قدّروا الدقّة لكل نموذج مع أخذ التباين بين الأوراق في الحسبان.
دقّة عالية، لكن تفاوضات على الجهد والتكلفة والسرعة
عبر جميع النماذج، حققت أنظمة الذكاء الاصطناعي دقّة إجمالية تقارب 91%، مما يعني أن الغالبية العظمى من الكيانات المقترحة تم الحكم عليها صحيحة. سجلت نماذج GPT-4.1 وGPT-4o Mini وGemini 2.0 Flash أعلى نسب دقّة — تقريبًا بين 94% و98% — رغم أن فروقها لم تكن واضحة إحصائيًا. ميّزت نماذج Gemini نفسها باقتراح عدد أكبر من الكيانات إجمالًا، مما أدى إلى مزيد من الوسوم الصحيحة لكنه زاد أيضًا العبء على المراجعة البشرية. بعض النماذج الصغيرة أو الأرخص، مثل GPT-4.1 Nano، كانت أسرع وأقل تكلفة لكنها أقل دقّة بشكل ملحوظ. صور المؤلفون هذه التنازلات باستخدام حدود باريتو، محدّدين مجموعات من النماذج التي توازن بين الدقّة وعدد الكيانات الصحيحة والتكلفة ووقت المعالجة: على سبيل المثال، ظهر GPT-4o Mini كخيار جذاب عند الموازنة بين الدقّة والتكلفة المنخفضة.
لماذا لا يزال البشر جزءًا من الحلقة
رغم الأداء القوي، يبرز البحث قيودًا مهمة. أحيانًا خلطت النماذج بين معلومات متعلقة بالمقال المنشور وتفاصيل لا ترتبط فعليًا بمجموعة البيانات الأساسية التي قد يرغب المستخدمون المستقبليون في إعادة استخدامها. تعكس هذه الارتباك تحديًا أوسع في استخراج النصوص المؤتمت: تناقش الأوراق العلمية أمورًا أوسع بكثير مما ينتهي فعليًا في مجموعة بيانات مشتركة. لذلك يوصي المؤلفون بأن يواصل الخبراء البشر مراجعة الوسوم المولدة آليًا قبل نشرها. كما ينوّهون أن تقييمهم شمل ست مقالات في أمراض الكلى فقط، لذا هناك حاجة لاختبارات أوسع عبر مجالات متعددة. مع مرور الوقت، قد تبني سلسلة عمل روتينية «بوجود الإنسان في الحلقة» مجموعة مرجعية توافقية، ما يجعل من الممكن قياس ليس فقط الدقّة ولكن أيضًا عدد الكيانات التي فاتهم النماذج.
ماذا يعني هذا لمشاركة البيانات الطبية الحيوية مستقبلًا
تُظهر الدراسة أنه عند توجيهها بعناية وربطها بقواعد بيانات موثوقة، يمكن لنماذج اللغة الكبيرة الحديثة أن تساعد بثقة في وسم الأوراق الطبية الحيوية، مخفِّضةً بشكل كبير العبء اليدوي على الباحثين. النماذج الأفضل تقترب من دقّة على مستوى الخبراء بينما تقدم مزيجًا من التنازلات بين الشمولية والتكلفة والسرعة. في الوقت الحالي، يظل المراجعة البشرية ضرورية لضمان تطابق الوسوم فعليًا مع مجموعات البيانات وسياق البحث. لكن مع نضوج الأدوات والنماذج مفتوحة المصدر، قد تصبح سير العمل من هذا النوع العمود الفقري المعتاد لتحويل فيض المقالات الطبية اليوم إلى مرافق بيانات منظمة وقابلة لإعادة الاستخدام غدًا.
الاستشهاد: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
الكلمات المفتاحية: استخراج النصوص الطبية الحيوية, نماذج اللغة الكبيرة, وسم البيانات الوصفية, الذكاء الاصطناعي المؤسَّس, أبحاث أمراض الكلى