Clear Sky Science · ar
الخلاف بين تقييم البشر والذكاء الاصطناعي لخطط العلاج
لماذا يهم هذا في الرعاية الطبية اليومية
مع بداية استخدام أدوات الذكاء الاصطناعي لمساعدة الأطباء في اختيار العلاجات، يبرز سؤال رئيسي: على أي حكم نثق أكثر — البشر أم الآلات؟ تدرس هذه الدراسة إمكانية بسيطة لكنها مقلقة: قد يختلف الأطباء وأنظمة الذكاء الاصطناعي ليس فقط بشأن أي علاج هو الأفضل، بل أيضاً بشأن ما يُعتبر خطة علاج "جيدة" من الأساس. فهم هذه الفجوة أمر أساسي إذا أردنا أن يدعم الذكاء الاصطناعي، بدلاً من أن يشوّه بهدوء، قرارات الطب الواقعية.
اختبار مباشر لنصائح العلاج
ركز الباحثون على الأمراض الجلدية، وهو مجال يدير فيه الأطباء حالات جلدية طويلة الأمد نادراً ما يكون لها إجابة "صحيحة" وحيدة. طُلِب من عشرة أطباء جلدية ذوي خبرة ونموذجي لغة كبيرين (نموذج عام ونموذج مُركّز على الاستدلال) كتابة خطط علاجية لخمس حالات مختلقة وتحدّية، مثل الإكزيما الشديدة، والصدفية مع أمراض أخرى، وحب الشباب المرتبط بالحمل. للحفاظ على النزاهة، تم تحرير جميع الخطط الستين إلى صيغة مشتركة: طول وبنية ونبرة متشابهة. أُزيلت أي دلائل واضحة على ما إذا كانت الخطة مكتوبة من قِبَل إنسان أو ذكاء اصطناعي، حتى يقوم الحكّام لاحقاً بتقييم المحتوى لا الأسلوب.
كيف قام البشر والذكاء الاصطناعي بالتقييم
ثم خضعت الخطط لجولتين من التسجيل الأعمى باستخدام نفس المعيار. أولاً، قيّم نفس مجموعة أطباء الجلدية العشرة كل خطة على الجودة الشاملة من 0 إلى 10، مع مراعاة مدى الفاعلية والسلامة والعملية وتركيزها على المريض. ثانياً، نموذج ذكاء اصطناعي منفصل — استُخدم كحاكم فقط، وليس ككاتب خطط — قيّم نفس الخطط نفسها بنفس التعليمات. والأهم أن لا المقيمين البشريين ولا حاكم الذكاء الاصطناعي عرفوا من كتب أي خطة. سمح هذا الإعداد للمؤلفين بعزل عامل واحد رئيسي: ما إذا كان المقيم إنساناً أم ذكاءً اصطناعياً.
البشر يدعمون البشر، والذكاء الاصطناعي يدعم الذكاء الاصطناعي
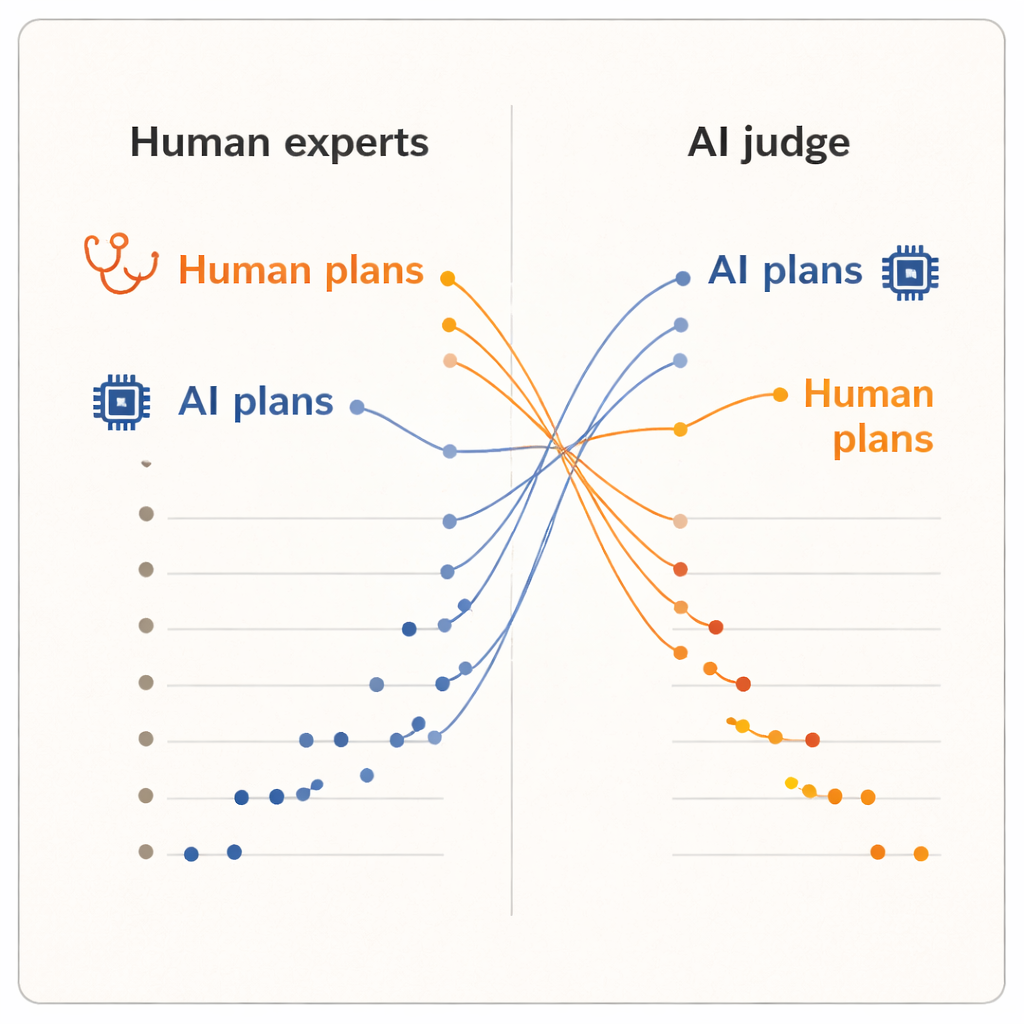
أظهرت النتائج «تأثير المقيم» بوضوح. عندما قيّم البشر الخطط، منحوا درجات أعلى للخطط التي كتبها زملاؤهم من أطباء الجلد مقارنة بتلك التي كتبها أي من أنظمة الذكاء الاصطناعي. حصلت الخطط التي أنتجها البشر على متوسط أعلى قليلاً واحتلت المراكز الخمسة الأولى في الترتيب. أحد نماذج الذكاء الاصطناعي، نظام الاستدلال المتقدم، وجد نفسه قرب القاع. لكن عندما تولى حاكم الذكاء الاصطناعي التقييم، انقلبت الصورة. ارتفعت الآن خطتان مكتوبتان بواسطة الذكاء الاصطناعي إلى قمة الترتيب، وهبطت خطط كل أطباء الجلد تحتها. في المتوسط، قيّم حاكم الذكاء الاصطناعي الخطط المولَّدة بواسطة الذكاء الاصطناعي أعلى من تلك المولَّدة بواسطة البشر، على الرغم من أنه كان يقرأ نفس النص الموحد تماماً الذي اطلع عليه أطباء الجلد.
أفكار مختلفة حول ما يجعل الخطة "جيدة"
نظرًا لأن الخطط تم توحيدها من حيث الصياغة وحُفظ غياب معرفة المصدر عن الحكّام، يجادل المؤلفون بأن هذا الانقسام لا يمكن تفسيره بالتلميع السطحي. بدلاً من ذلك، فإنه يوحي بأن البشر وأنظمة الذكاء الاصطناعي يجلبون مقاييس داخلية مختلفة. من المرجح أن يميل الأطباء إلى الخبرة الواقعية: ما الذي يكون قابلاً للتنفيذ في عياداتهم، كيف يستجيب المرضى، وأي تنازلات تبدو مقبولة عملياً. بالمقابل، قد يفضّل حكم الذكاء الاصطناعي المدرب على مجموعات نصية واسعة الخطط التي تتبع أنماطاً شائعة في الأدبيات الطبية أو الإرشادات، حتى لو أن تلك الأنماط لا تلتقط بالكامل القيود المحلية أو تفضيلات المرضى. الدراسة متواضعة في حجمها — فقط عشرة أطباء، خمس حالات وحاكم ذكاء اصطناعي واحد — وتقيس الجودة المتصورة، وليس نتائج المرضى الفعلية. ومع ذلك، فإن الانقلاب لافت بما يكفي ليطرح أسئلة أعمق حول كيفية تقييمنا للذكاء الاصطناعي السريري.
إعادة التفكير في كيفية اختبار واستخدام الذكاء الاصطناعي السريري
من هذه النتائج، يستخلص المؤلفون درسين عامين. أولاً، الاختبارات التقليدية القائمة على "الإجابة الصحيحة" للذكاء الاصطناعي الطبي تغفل الكثير مما يهم في الرعاية الواقعية، حيث يجب أن توازن الخطط بين الفاعلية والسلامة والتكلفة واللوجستيات ورغبات المريض. وهم يدعون إلى أطر تقييم أغنى ومتعددة المقاييس تُقَيّم هذه الأبعاد صراحةً، وتستخدم عدة حكّام بشريين وذكاء اصطناعياً، وتحلل أين ولماذا تنشأ الخلافات بدلاً من اختزال كل شيء إلى درجة واحدة. ثانياً، يقترحون أن الاختلافات بين أحكام البشر والآلات يمكن أن تكون ميزة لا مجرد عيب. إذا استُخدمت بحذر، قد تخدم الخطط المولّدة آلياً كرأي ثانٍ متأمّل يدفع الأطباء لإعادة النظر في افتراضاتهم، بينما يوفر الأطباء السياق الواقعي والحكم الأخلاقي الذي يفتقده الذكاء الاصطناعي. قد يساعد بناء واجهات موثوقة وشفافة تكشف الافتراضات، وتسمح للأطباء بضبط الأولويات ودعوتهم للمراجعة النقدية في تحويل هذا التوتر بين وجهات نظر البشر والذكاء الاصطناعي إلى صنع قرار أكثر أماناً وتوازناً.
الاستشهاد: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
الكلمات المفتاحية: دعم القرار السريري, الذكاء الاصطناعي في الطب, تعاون البشر والذكاء الاصطناعي, تخطيط العلاج, انحياز التقييم