Clear Sky Science · ar
نهج تعلم معزز عميق لتحليل حركات الرقص
تعليم الحواسيب مشاهدة الرقص كما نفعل نحن
من الباليه إلى الهيب هوب، تحمل الرقصات انتقالات دقيقة في الإيقاع والوضعيات يلتقطها العين البشرية فوراً — لكن الحواسيب تكافح لرؤيتها. تقدم هذه الدراسة طريقة جديدة للذكاء الاصطناعي «لمشاهدة» فيديوهات الرقص بشكل أقرب إلى خبير بشري، تتخطى الخطوات الروتينية للتركيز على لحظات قصيرة وكاشفة تحدد كل نمط. النتيجة نظام يتعرف على أنواع الرقص بدقة أكبر أثناء مشاهدة قدر أقل بكثير من الفيديو، وهو تقدم محتمل لكل شيء من الأرشيفات الرقمية إلى تكنولوجيا الرياضة والترفيه.
لماذا فيديوهات الرقص صعبة على الآلات
من الوهلة الأولى قد يبدو تدريب الحاسوب على التعرف على أنماط الرقص أمراً بسيطاً: أدخل الفيديوهات ودع التعلم العميق يكتشف الأنماط. في الواقع، يضيع معظم الأنظمة الحالية جهداً كبيراً. نماذج الفيديو التقليدية إما تعالج كل إطار أو تأخذ عينات مقاطع بفترات ثابتة، مفترضة أن كل اللحظات متساوية الأهمية. لكن أنماط الرقص غالباً ما تختلف في تفاصيل صغيرة—كيف تدور القدم، متى يحوّل الشريك اتجاهه، أو توقيت دوران—بدلاً من حركة مستمرة. هذا يعني أن العديد من الإطارات إما متكررة أو غير معبرة، وقد تقع الوضعيات الحاسمة بين نقاط العينة الثابتة، مما يسبب ارتباكاً بين، مثلاً، الفالس والفوxtrot.
طريقة أكثر ذكاءً لتصفح الفيديو
اقترح الباحثون إطار عمل يسمّى الاختيار الزمني اليقظ المعتمد على التعلم المعزز، أو RATS، الذي يعامل تحليل الفيديو كمهمة بحث نشطة بدلاً من مشاهدة سلبية. بدلاً من التقدم إطاراً بإطار، يقسم النظام فيديو الرقص إلى مقاطع قصيرة ويحوّل كل مقطع أولاً إلى وصف مضغوط لحركته باستخدام شبكة تلافيفية ثلاثية الأبعاد متخصصة. تُخزن هذه الملخصات الحركية في ذاكرة. فوق ذلك، يقوم وكيل اتخاذ القرار بالتنقّل عبر تسلسل المقاطع، مختاراً ما إذا كان يتقدّم وقفزة صغيرة، قفزة أكبر، أو أن يتوقف ويصدر توقعاً بالنمط. فعلياً، يتعلم النظام كيف يتصفح عبر الزمن، متوقفاً عند الأنماط الدالة ومتجاوزاً المقاطع الأقل فائدة.
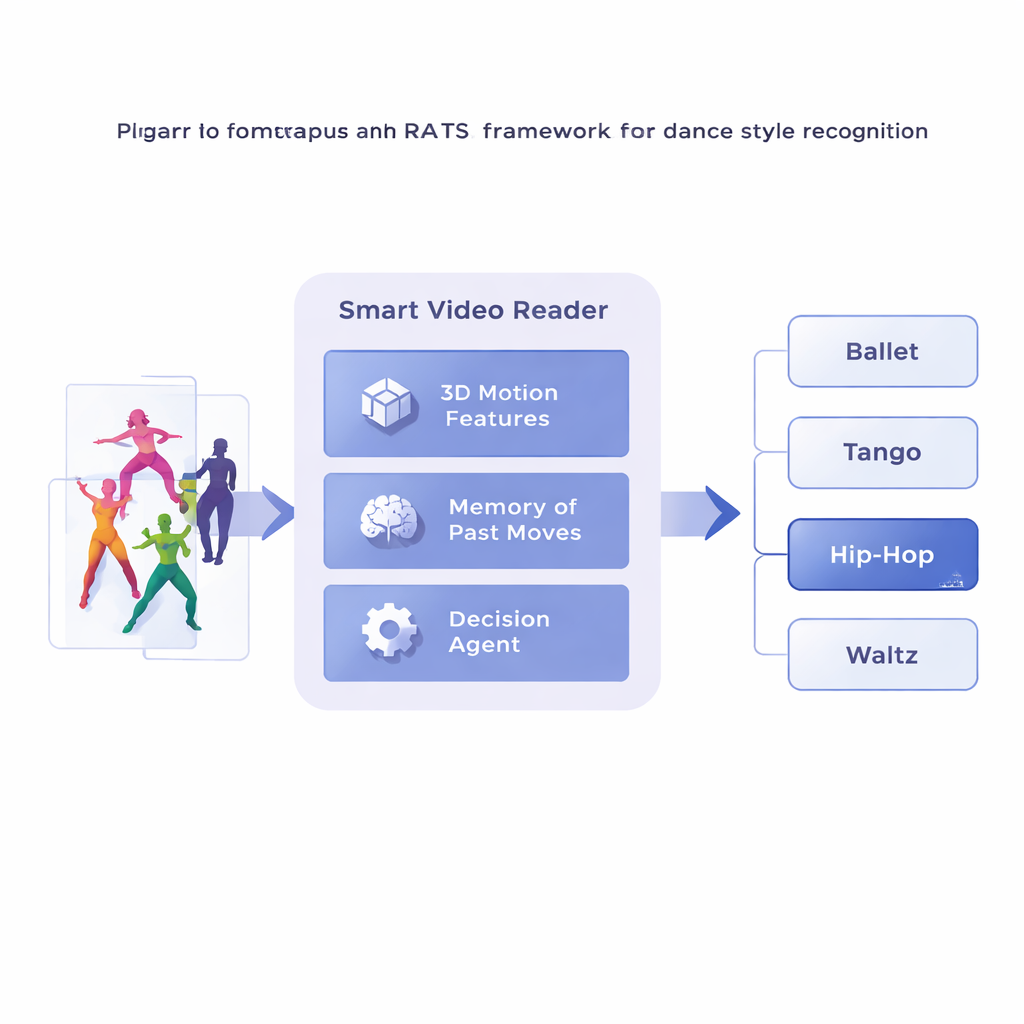
تعلم متى ينظر ومتى يقرّر
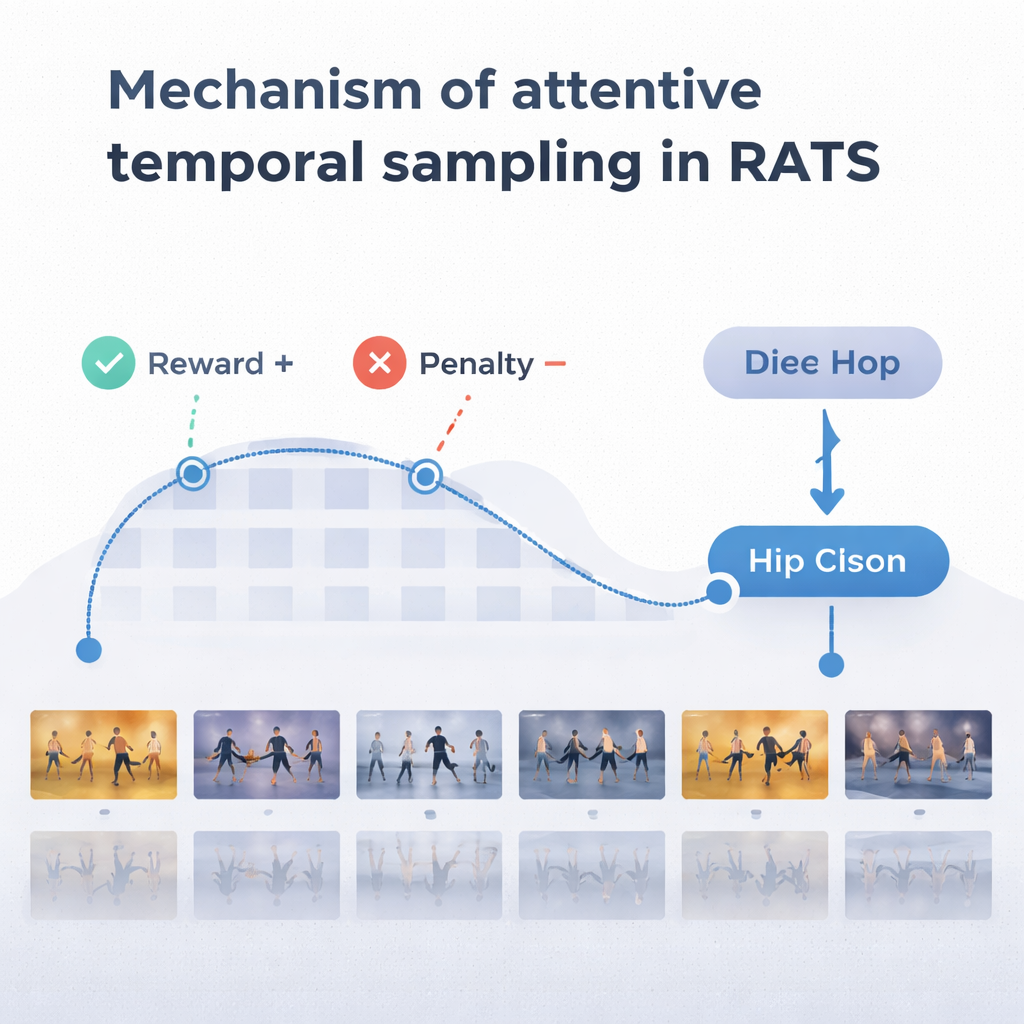
لاتخاذ قرارات معقولة، يعتمد الوكيل على شكل من الذاكرة مستوحاة من كيفية استرجاعنا لكل من الحركة الماضية والناشئة. شبكة متكررة ثنائية الاتجاه تتبع ما «شاهده» النظام بالفعل وكيف ترتبط المقاطع الحالية بتلك التاريخية. عند كل خطوة، يوازن الوكيل بين ثلاثة خيارات: قفزة قصيرة لفحص تفاصيل دقيقة مثل حركة القدم، قفزة أطول لتجاوز الحركة المتكررة، أو التوقف والتصنيف. يُدرَّب النظام بمكافآت وعقوبات: يحصل على درجة إيجابية كبيرة للقرار الصحيح، ودرجة سلبية كبيرة للقرار الخاطئ، وعقوبة صغيرة في كل مرة يقفز فيها إلى الأمام. هذا التوازن يشجع الوكيل على أن يكون دقيقاً وفعالاً في آن واحد—ينتظر حتى يجمع أدلة كافية، لكن دون التجوال طوال مدة الفيديو.
تفوق على مصنّفات الرقص التقليدية
اختبر الفريق RATS على مجموعة Let's Dance، وهي مجموعة تحدٍّ تضم 1000 فيديو تغطي عشرة أنماط، من الفلامنكو والتانغو إلى السوينغ والرقص الميداني. بالمقارنة مع عدة طرق موجودة، بما في ذلك الشبكات العميقة القياسية ونماذج مخصصة للرقص، حقق RATS أعلى دقة — حوالي 92% — وأفضل توازن إجمالي بين الدقة والاستدعاء. كما تبين أنه أفضل إحصائياً من منافسين أقوياء، وليس فرقاً طفيفاً ناجماً عن الصدفة. والأهم أن النظام وصل لهذه النتائج بينما كان يحلل في المتوسط نحو 38% فقط من إطارات الفيديو. أخذ عينات منتظمة كل بضع إطارات كان أسرع لكنه فشل في التقاط اللحظات الحاسمة وخفض الأداء؛ ومعالجة كل إطار كانت أبطأ ومع ذلك أقل دقة من النهج المستهدف.
ما معنى هذا أبعد من حلبة الرقص
لغير المتخصص، الرسالة الأساسية واضحة: يمكن للحواسيب أن تؤدي عملاً أفضل عندما تتعلم أن تكون مشاهدين انتقائيين. بتعليم الذكاء الاصطناعي التركيز على «اللحظات الذهبية» في الزمن، يبيّن هذا العمل أن الآلات يمكنها التعرف على الحركات البشرية المعقدة بدقة أكبر مع استخدام موارد أقل. على الرغم من أن الدراسة تركز على الرقص، إلا أن الفكرة نفسها يمكن أن تساعد الأنظمة في انتقاء العناصر الأساسية في حركات رياضية، لقطات المراقبة، أو أي فيديو طويل تكون فيه الأحداث المهمة قصيرة ومتفرقة. بعبارة أخرى، المشاهدة الأذكى—لا المشاهدة الأكثر—قد تكون مستقبل فهم الفيديو.
الاستشهاد: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
الكلمات المفتاحية: تعرف على الرقص, تحليل الفيديو, التعلم العميق, التعلم المعزز, حركة الإنسان