Clear Sky Science · ar
نموذج استخراج العلاقات المكانية باللغة الصينية بدمج الميزات الدلالية الجغرافية
تعليم الحواسيب فهم مواقع الأماكن
نصف المواقع يومياً بعبارات بسيطة: مدينة تقع جنوب نهر، حديقة قريبة من جامعة، طريق سريع يمر عبر مقاطعة. تحويل هذا النوع من اللغة اليومية إلى معرفة رقمية دقيقة أمر حيوي للخرائط الذكية وتطبيقات الملاحة والبحث الجغرافي. تقدم هذه الورقة طريقة جديدة تُسمى PURE‑CHS‑Attn تساعد الحواسيب على قراءة النصوص الصينية واستخراج العلاقات المكانية بين الأماكن تلقائياً بدقة أكبر من السابق.
لماذا اللغة المكانية مهمة
العلاقات المكانية هي كلمات وعبارات تخبرنا كيف ترتبط الأماكن في الفضاء، مثل «داخل»، «بجانب»، «شمال»، أو «على بعد 30 كيلومتراً». تشكل هذه العبارات جسراً بين العالم الحقيقي الذي نراه على الخرائط والمفاهيم التي نستخدمها ذهنياً. في نظم المعلومات الجغرافية (GIS)، تقوم هذه العلاقات على تنظيم البيانات والبحث والتحليل. وهي أيضاً مركزية في مجالات أخرى: مثلاً دمج صور الأقمار الصناعية، تتبع الحركة في الفيديو، تخطيط المصانع أو دراسة كيف يؤثر المناخ والتضاريس على التنوع الحيوي. وبما أن كثيراً من هذه المعلومات مكتوب بلغة طبيعية، فوجود أدوات موثوقة تقرأ النص وتستخرج العلاقات المكانية تلقائياً أصبح أمراً متزايد الأهمية.
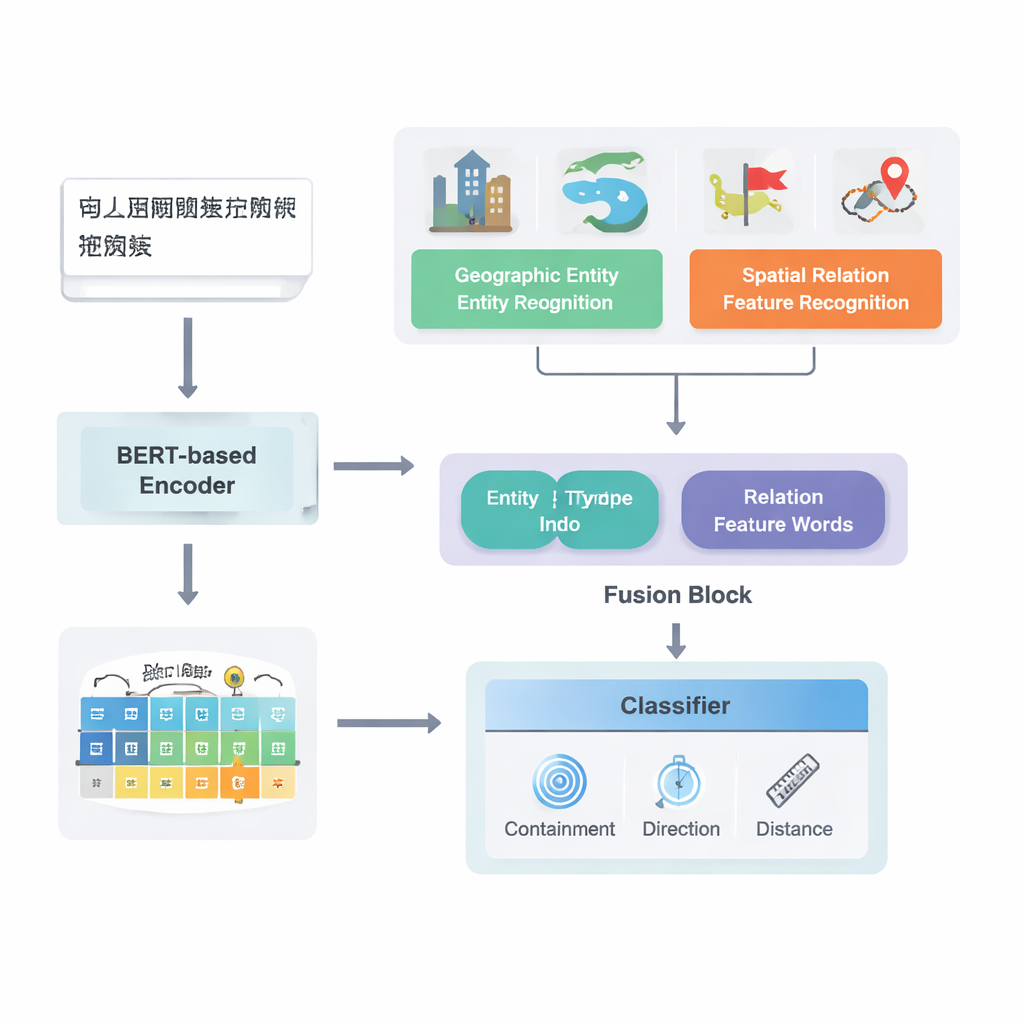
من النص الخام إلى علاقات موضوعة على خريطة
يركز المؤلفون على النصوص الصينية ويبنون على أنبوب تعلم عميق قوي موجود يُعرف باسم PURE. يعمل نموذجهم المحسن PURE‑CHS‑Attn بعدة مراحل. أولاً، يفحص الجمل ليجد كيانات جغرافية مثل جبال، أنهار، مدن ومناطق إدارية، ويصنّف كلّاً منها بنوع (مثلاً سطح أرضي، جسم مائي، مرفق عام، موقع تاريخي أو تقسيم إداري). بعد ذلك، يكشف عن «كلمات ميزات» للعلاقات المكانية مثل «يحدّ»، «يجري عبر»، «جنوب»، أو «قريب من» التي تشير إلى كيفية ارتباط مكانين. يحول نموذج لغوي قوي، BERT‑wwm‑ext، الأحرف في كل جملة إلى متجهات رقمية تلتقط معناها وسياقها. تغذي هذه المتجهات مكونات منفصلة تتعرف على الكيانات وكلمات العلاقة ثم تنقل نتائجها إلى وحدة دمج (fusion).
مزج المعرفة البشرية مع التعلم الآلي
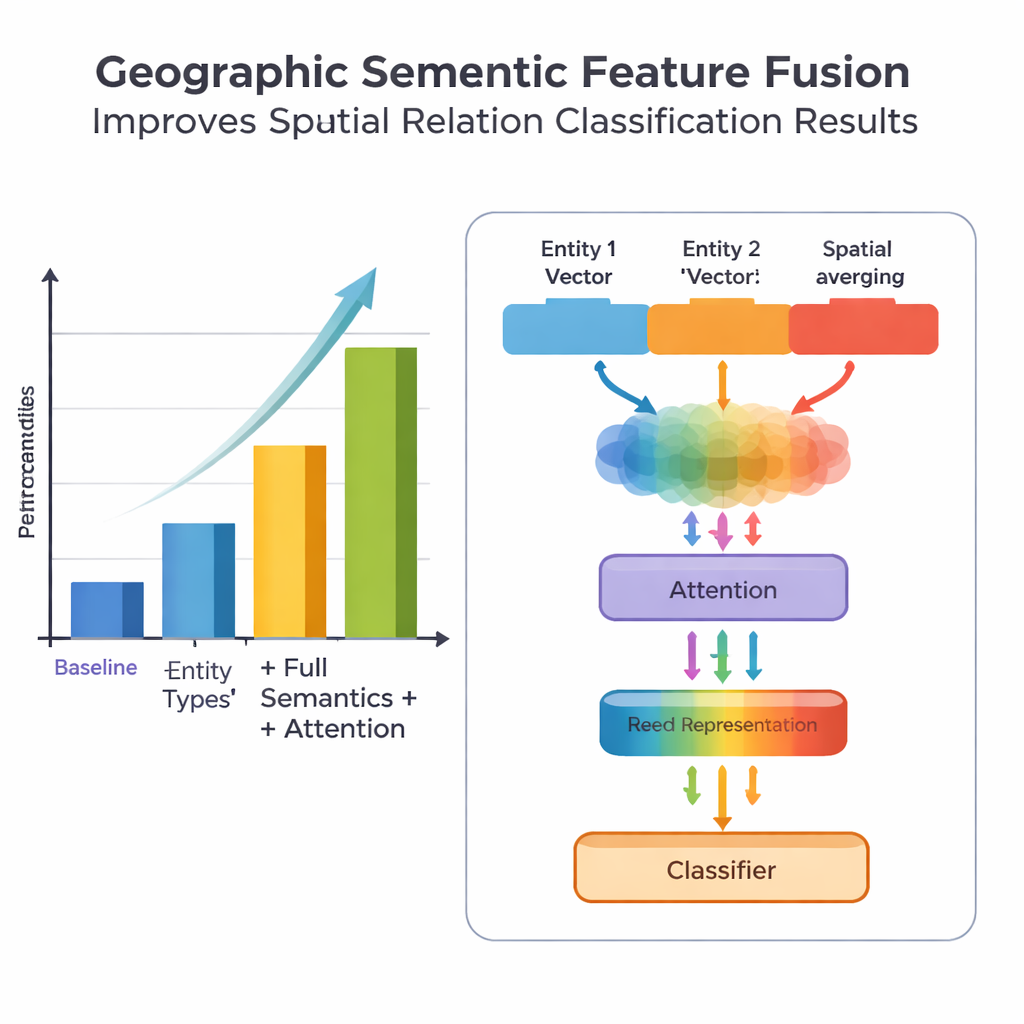
تكمن إحدى حداثات العمل في الطريقة التي يدمج بها المعرفة الجغرافية مع أنماط النص المتعلمة. بدلاً من معاملة كل كلمة على قدم المساواة، يستغل النموذج نوعين من المعلومات الدلالية التي يستخدمها البشر بطبيعة الحال: نوع كل كيان جغرافي والكلمات المكانية التي تربط بينها. تجمع وحدة الدمج أولاً متجهات الكيانين معاً باستخدام أوزان تعتمد على تكرار مشاركة أنواع أماكن مختلفة (مثل منطقتين إداريتين مقابل نهر ومقاطعة) في أنواع علاقات مختلفة. ثم تمزج متجهات كلمات الميزات المكانية. بالإضافة إلى هذا «الدمج الأساسي»، أضاف المؤلفون آلية انتباه تتيح للنموذج التركيز ديناميكياً على أكثر أجزاء توليفة الكيان–الكلمة إفادة. يُمرَّر التمثيل المدمج النهائي إلى مُصنِّف يستطيع تعيين نوع أو أكثر من أنواع العلاقات — طوبولوجية (مثل الاحتواء أو المجاورة)، اتجاهية (شمال، جنوب، إلخ) أو مبنية على المسافة — بين كل زوج من الأماكن في الجملة.
اختبار النموذج
لتقييم منهجهم، جمع الفريق مجموعة بيانات من موسوعة الصين: الجغرافيا الصينية، وعلّموها بعناية، احتوت على 1381 جملة و368 زوجاً من العلاقات المكانية. قارَنوا عدة نسخ من النموذج: خط أساس يستخدم فقط معلومات موقع عامة، نسخة بأنواع كيانات أدق، نسخة تضيف أيضاً كلمات الميزات المكانية، ونموذجهم الكامل PURE‑CHS‑Attn بتصميم الدمج والانتباه الجديد. وفق معايير قياسية للدقة والاستدعاء ومقياس F1، حسّن PURE‑CHS‑Attn الأداء بنحو 7% في الدقة، 6.5% في الاستدعاء و6.7% في F1 مقارنة بالخط الأساسي. كان أقوى خصوصاً في التعرف على العلاقات الطوبولوجية والاتجاهية، وتعامل بشكل أفضل مع أنواع العلاقات النادرة (few‑shot) مقارنة بالنماذج الأبسط. عند مقارنته مع ثلاثة أنظمة حديثة متقدمة، بما في ذلك واحد مبني على نماذج لغوية كبيرة، احتل PURE‑CHS‑Attn المركز الثاني بفارق بسيط بينما يظل أخف وزناً وأسهل نشرًا.
التحديات والاتجاهات المستقبلية
رغم هذه التحسينات، لا يزال النموذج يواجه صعوبة مع علاقات المسافة، خاصة عندما تكون أمثلة التدريب قليلة. يبين المؤلفون أن مجموعة البيانات تحتوي على حالات قليلة جداً من هذا النوع، مما يقيّد ما يمكن لأي طريقة تحتاج بيانات أن تتعلمه. كما ينوّهون إلى أن المتوسط الأعمى لعديد كلمات الميزات المكانية في الجملة قد يدخل ضوضاء، وهو ما تساهم آلية الانتباه في التخفيف منه لكنها لا تحله تماماً. للمستقبل يقترحون مسارين واعدين: توسيع وموازنة بيانات التدريب باستخدام تقنيات التحويل (augmentation)، ودمج الدمج الدلالي الجغرافي مع تقنيات من نماذج اللغة الكبيرة والتعلم المعتمد على التعليمات (prompt‑based learning) لتعزيز الأداء في سيناريوهات قلة البيانات مع الحفاظ على كفاءة النظام.
ما معنى هذا للخريطة اليومية
بعبارات بسيطة، يُعلّم هذا البحث الحواسيب قراءة الأوصاف المكانية في اللغة الصينية بطريقة أقرب إلى الطريقة البشرية، عن طريق الانتباه إلى أنواع الأماكن المذكورة وكيف صيغت علاقاتها بالضبط. يُظهِر نموذج PURE‑CHS‑Attn أن مزج المعرفة الجغرافية المهيكلة مع التعلم العميق الحديث يؤدي إلى استخراج أكثر دقة ومتانة لـ«من أين وإلى أي شيء» من النص. يمهد هذا الطريق لنظم معلومات جغرافية أكثر ذكاءً وتلقائية، ورسومًا معرفية جغرافية أغنى وأدوات أفضل لاستكشاف كيفية وصف الفضاء عبر العلم والسياسة والتواصل اليومي.
الاستشهاد: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
الكلمات المفتاحية: استخراج العلاقات المكانية, الذكاء الاصطناعي الجغرافي, دلالات جغرافية, تنقيب النصوص الصينية, أتمتة نظم المعلومات الجغرافية