Clear Sky Science · ar
تقييم ChatGPT-4o وGemini لإدارة النقرس: تحليل مقارن بناءً على إرشادات EULAR
لماذا تهمُّ الدردشات الذكية والمفاصل المؤلمة
النقرس، وهو شكل مؤلم من التهاب المفاصل الذي غالباً ما يصيب إصبع القدم الكبير، يزداد شيوعاً في أنحاء العالم. لدى الأطباء بالفعل إرشادات واضحة ومبنية على الأدلة حول كيفية تشخيصه وعلاجه، ومع ذلك لا يزال الكثير من المرضى لا يحصلون على الرعاية المثالية. وفي الوقت نفسه، بدأت دردشات الذكاء الاصطناعي القوية مثل ChatGPT-4o وGemini تظهر في العيادات، مما يطرح سؤالاً بسيطاً لكنه حاسم: هل يمكن لهذه الأدوات أن تقدم نصائح آمنة ومتوافقة مع الإرشادات حول النقرس، أم أنها قد تضِّل الأطباء والمرضى؟
التحقق من مدى التزام الدردشات بقواعد اللعبة
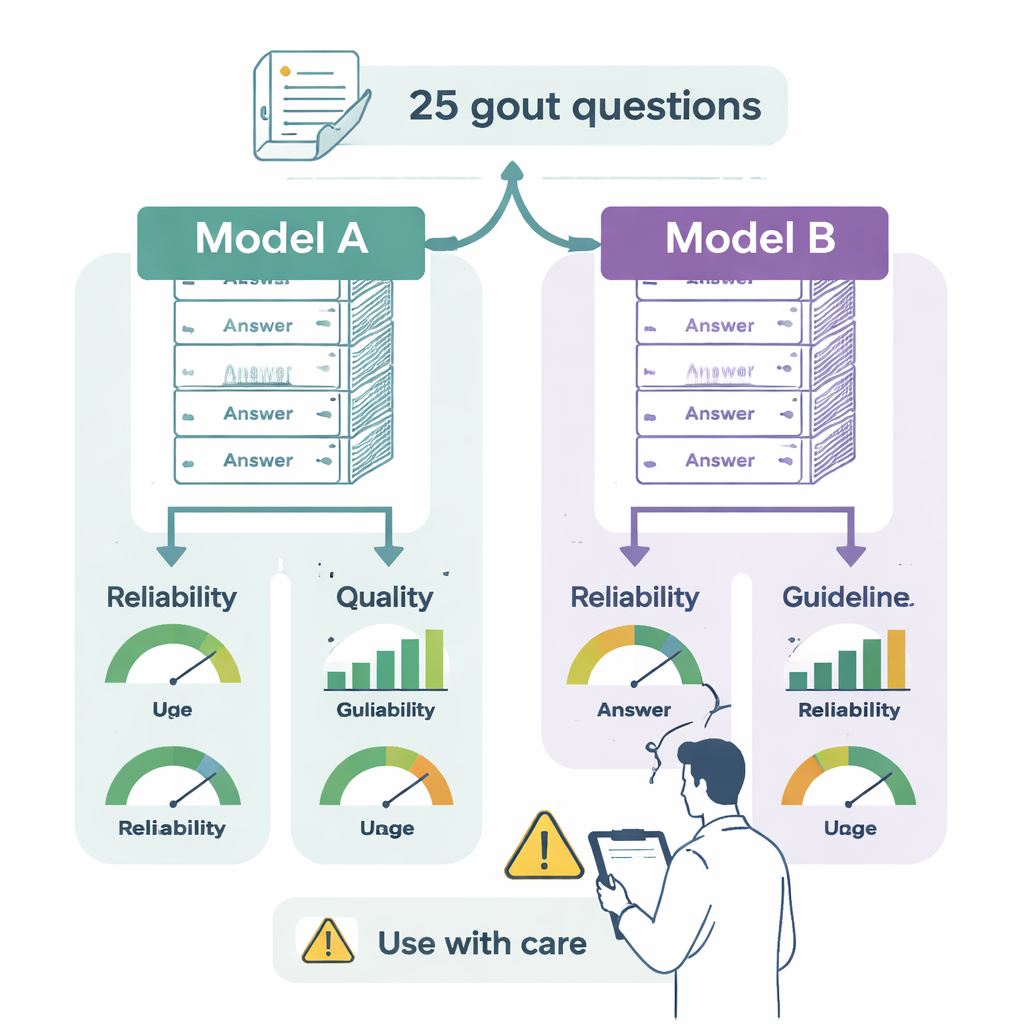
سعى الباحثون لاختبار نموذجي لغة رائدين—ChatGPT-4o وGemini 2.0 Flash—مقابل الإرشادات الأوروبية الرسمية (EULAR) للنقرس. قام اثنان من الاختصاصيين بتحويل 25 توصية أساسية من الإرشادات إلى أسئلة على نمط الأطباء حول قضايا العالم الحقيقي: كيفية تشخيص النقرس، متى يُبدأ علاج خافض للبول (uratelowering)، كيفية إدارة النوبات الحادة، ما هي الأهداف المتوقعة في فحوصات الدم، وكيف ينبغي تعديل نمط الحياة أو الأدوية الأخرى. طُرحت الأسئلة نفسها على كلا النظامين في جلسات منفصلة ومعزولة حتى لا تؤثر الإجابات السابقة على الجديدة.
كيف سوِّغت الإجابات
قيَّم كل إجابة طبيبان متمرسان في النقرس، لم يكونا على علمٍ بأي نموذج أنتج النص. قيَّما ثلاث نواحٍ. أولاً، الموثوقية: هل تبدو الإجابة متوازنة وموضوعية وجديرة بالثقة، أم أنها تحذف حقائق مهمة أو تبالغ في الفوائد؟ ثانياً، الجودة: هل الإجابة واضحة ومنظمة جيداً ومفيدة للاختصاصي عند اتخاذ القرار؟ ثالثاً، التوافق مع الإرشادات: هل تطابق ما توصي به EULAR فعلاً، أم تتفق جزئياً مع وجود فجوات، أم تتعارض مباشرة مع القواعد؟ كما فحص الفريق مدى سهولة قراءة الإجابات باستخدام اختبارات مقروئية معيارية تُقدِّر مستوى التعليم المطلوب لفهم النص.
ChatGPT أم Gemini: من الأفضل؟
قدمت كلتا الدردشتين إجابات عموماً معقولة وواضحة في الصياغة، وكلاهما ذكر القرّاء غالباً بضرورة استشارة ممارس صحي. لكن برزت اختلافات مهمة. تطابق ChatGPT-4o تماماً مع إرشادات النقرس في 76% من الحالات وقدم إجابات صحيحة إلى حد كبير لكنها غير مكتملة في 20% أخرى، مع وجود إجابة واحدة فقط تحمل خطأ طبياً واضحاً. أما Gemini فكان متوافقاً تماماً في 48% من الإجابات وجزئياً صحيح وغير مكتمل في 32%. وما هو أكثر إثارة للقلق، أن 12% من إجاباته مزجت أفكاراً صحيحة مع معلومات خاطئة، و8% تعارضت صراحة مع الإرشادات—على سبيل المثال، الاقتراح باستخدام واسع لفئة قوية من مضادات الالتهاب (مثبطات IL‑1) حيث تقتصر EULAR على حالات مختارة وصعبة العلاج، أو التشجيع على بدء خافضات حمض اليوريك أثناء نوبة حادة، وهو مجال ينصح فيه الخبراء بمزيد من الحذر.
مقروء، لكن القراءة ليست سهلة
فيما يتعلق بالأسلوب، كان النظامان متشابهان بشكل مفاجئ. على مقاييس قراءة متعددة، أنتج كلاهما نصوصاً تتطلب تعليمًا بمستوى الجامعة على الأقل لفهمها بسهولة. قد يكون ذلك مقبولاً لأطباء الاختصاص، لكنه معقَّد للغاية بالنسبة لغالبية المرضى. ولم يقدّم أي من النموذجين مراجع أو روابط للمصادر إلا إذا طُلب ذلك بشكلٍ صريح، مما يصعّب التحقق من مصدر المعلومات. تم تقييم اتفاق المقيمين مع بعضهم البعض بأنه جيد إلى ممتاز، مما يشير إلى أن التقييم كان متسقاً وأن الاختلافات بين الدردشتين كانت حقيقية وليست مسألة رأي فردي.
ماذا يعني هذا للأشخاص الذين يعيشون مع النقرس
بشكل عام، تشير الدراسة إلى أن الدردشات المتقدمة يمكن أن تكون مساعدات مفيدة للأطباء الذين يديرون حالات النقرس، لكنها ليست جاهزة للعمل بمفردها. كان ChatGPT-4o أكثر موثوقية وأكثر شمولية وأكثر وفاءً بإرشادات الخبراء من Gemini، ومع ذلك قد تكون أخطاؤه النادرة ذات تأثير عندما تتعلق الأمور بالأدوية والسلامة. تحدثت الأداتان بمستوى معقد جداً لمعظم المرضى وافتقدتا الشفافية المدمجة حول مصادر المعلومات. يجادل المؤلفون، في الوقت الراهن، بأن يُنظر إلى الذكاء الاصطناعي كأداة داعمة واعدة يمكن أن تساعد الأطباء والمعلمين—ولكن فقط عندما تُتحقق نصائحه مقابل الإرشادات المحدثة وحكم الخبراء، لا سيما في حالات مثل النقرس حيث يمكن لتفاصيل الجرعات الصغيرة وقرارات التوقيت أن تُحدث فرقاً كبيراً في الألم والضرر طويل الأمد وجودة الحياة.
الاستشهاد: Meral, H.B., Kolak, E. Evaluation of ChatGPT-4o and Gemini for gout management: a comparative analysis based on EULAR guidelines. Sci Rep 16, 4831 (2026). https://doi.org/10.1038/s41598-026-35166-5
الكلمات المفتاحية: النقرس, الإرشادات السريرية, الذكاء الاصطناعي, نماذج اللغة الكبرى, الروماتيزم