Clear Sky Science · ar
نهج تعلمي ومحاكاة متعدد الوسائط للإدراك في أنظمة القيادة الذاتية
سيارات ذاتية القيادة أذكى
تعد السيارات ذاتية القيادة بطرق أكثر أمانًا وحركة مرور أخف، لكنها لن تحقق ذلك إلا إذا تمكنت فعلاً من فهم العالم من حولها. تستعرض هذه الورقة طريقة جديدة لمساعدة المركبات الذاتية على «الرؤية» و«الإحساس» و«التنبؤ» بمحيطها بطريقة أقرب إلى سائق بشري حذر — عبر مزج مستشعرات مختلفة، والاختبار بأمان في نسخة افتراضية من العالم الحقيقي، وجعل قرارات السيارة أكثر شفافية للناس.
رؤية الطريق بعدة «حواس»
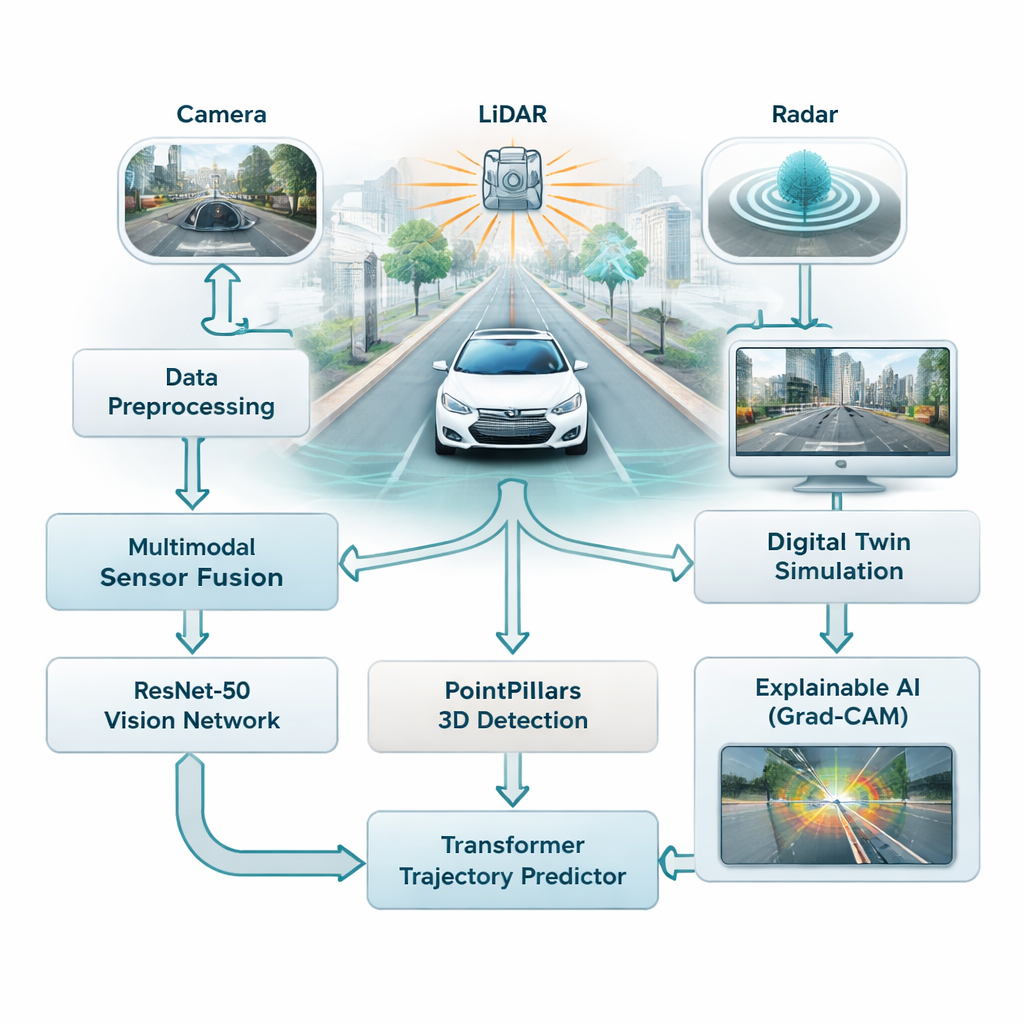
تعتمد معظم أنظمة مساعدة السائق اليوم بصورة كبيرة على الكاميرات، التي تعمل جيدًا في الضوء الجيد لكنها تكافح في الضباب أو المطر أو أثناء الليل. تجمع هذه الدراسة بين ثلاثة أنواع من المستشعرات — كاميرات، وأجهزة مسح ليزرية (LiDAR)، ورادار — حتى لا تعتمد السيارة على مصدر واحد هش للمعلومات. تلتقط الكاميرات ألوانًا وتفاصيل غنية، ويبني LiDAR صورة ثلاثية الأبعاد دقيقة للمشهد، ويظل الرادار موثوقًا في الأحوال الجوية السيئة. يندمج كل مجرى من هذه البيانات في رؤية موحدة لحركة المرور، ما يمنح المركبة فهمًا أكثر اكتمالًا وموثوقية للطرقات والمشاة والمركبات الأخرى.
تعليم السيارة التعرف والتنبؤ
لفهم هذا الكم الكبير من البيانات، يستخدم الإطار عائلتين من نماذج الذكاء الاصطناعي الحديثة. أولًا، شبكة عميقة للصور تُدعى ResNet-50 تفحص صور الكاميرا لالتقاط الوضع العام — مدى ازدحام الطريق، وأين تظهر المسارات، وكيف تم ترتيب المشهد. وفي الوقت نفسه، يقرأ نموذج ثلاثي الأبعاد يُسمى PointPillars سحب نقاط LiDAR لتحديد مواقع المركبات والأجسام الأخرى في ثلاثية الأبعاد. تُغذى هذه الإشارات بعد ذلك إلى محول (Transformer)، وهو نوع من الذكاء الاصطناعي صُمّم أساسًا للغات ويبرع في فهم كيفية تغير الأشياء عبر الزمن. هنا، يتعلم التنبؤ بكيفية تحرك السيارات القريبة والأجسام المتحركة الأخرى خلال الثواني القليلة التالية، مع الأخذ في الاعتبار حركتها السابقة وبنية الطريق.
بناء مضمار اختبار افتراضي آمن
بدلًا من اختبار المواقف الخطرة مباشرة على الطرق العامة، يربط الباحثون نظامهم بتوأم رقمي — نسخة افتراضية لشوارع المدينة الحقيقية مبنية على مجموعة بيانات عامة كبيرة من بوسطن وسنغافورة. في هذا العالم المُحاكى، تُعاد تشغيل حسّاسات السيارة وحركتها ومحيطها وتُعدّل حسب الحاجة، بينما يحاول الذكاء الاصطناعي تتبع الأجسام وتوقع مساراتها المستقبلية. يمكن للنظام تشغيل هذه السيناريوهات «ماذا لو؟» في الزمن الحقيقي، بزمن استجابة أقل من 50 مللي ثانية، مما يتيح للمهندسين استكشاف حالات الحافة مثل الكبح المفاجئ أو الانعطافات الحادة أو التقاطعات المزدحمة دون تعريض أحد للخطر.
إلقاء نظرة داخل «الصندوق الأسود» للذكاء الاصطناعي
من الانتقادات الشائعة للتعلم العميق أنه قد يكون من الصعب فهم سبب اتخاذ النموذج قرارًا معينًا. لمعالجة ذلك، يستخدم الباحثون طريقة تُسمى Grad-CAM، التي تبرز أجزاء الصورة التي أثرت أكثر في مخرج النموذج. تُظهر خرائط الحرارة هذه، على سبيل المثال، ما إذا كانت الشبكة تركز على سيارة أخرى أو مشاة أو علامة مسار عند تقدير المسارات. على الرغم من أن خطوة الشرح هذه تعمل خارج الخط وليست في حلقة الزمن الحقيقي للسيارة، إلا أنها تساعد المهندسين ومراجعي السلامة على التحقق من أن النظام يولي الاهتمام للإشارات الصحيحة، وهو أمر حاسم لبناء الثقة العامة.
ما مدى تحسّن قيادتها؟
عند اختبارها على مئات مشاهد القيادة الحضرية، يكشف الإطار المقترح عن أجسام ثلاثية الأبعاد بدقة ويتنبأ بالحركة بدقة أكبر من قواعد فيزيائية بسيطة تفترض سرعة ثابتة أو تسارعًا ثابتًا. أخطاء التنبؤ — مدى ابتعاد المواقع المتوقعة عن الواقع — أصغر بشكل ملحوظ من تلك الخاصة بهذه النماذج الأساسية وقريبة من نموذج ذكاء اصطناعي متكرر قوي، مع بقائها سريعة بما يكفي للاستخدام في الزمن الحقيقي. تُظهر تجارب دقيقة تقارن تصميمات شبكات مختلفة أن نموذج صورة أعمق وكاشف ثلاثي الأبعاد متوسط العمق يحققان أفضل توازن بين الدقة والسرعة، وأن النظام يمكن نشره على حواسيب متنقلة أصغر بعد ضغط النماذج.
ماذا يعني هذا للسائقين في الحياة اليومية
بالنسبة لغير المختصين، الرسالة هي أن سيارات ذاتية القيادة أكثر أمانًا وموثوقية من المرجح أن تأتي من نهج يمزج مستشعرات متعددة، ويتنبأ بكيفية تطور المشهد، ويُختبر بدقة في عوالم افتراضية واقعية. بدمج الإدراك والتنبؤ والمحاكاة وشرح قابل للفهم البشري في تصميم واحد، تقرب هذه الدراسة المركبات الذاتية من السلوك كشركاء حذرين وشفافين على الطريق بدلًا من آلات غامضة.
الاستشهاد: Almadhor, A., Al Hejaili, A., Alsubai, S. et al. A multimodal learning and simulation approach for perception in autonomous driving systems. Sci Rep 16, 5505 (2026). https://doi.org/10.1038/s41598-026-35095-3
الكلمات المفتاحية: القيادة الذاتية, دمج المستشعرات, تنبؤ المسار, كشف الأجسام ثلاثية الأبعاد, محاكاة التوأم الرقمي