Clear Sky Science · ar
نموذج تقييم ذكي هجين لتعليم الترجمة الإنجليزية مع BERT وSVM المحسّنين
لماذا تهم تحسينات تصحيح الترجمة
كل عام يقضي معلمو اللغات ساعات طويلة في تصحيح ترجمات الطلاب. قرار ما إذا كانت الجملة «جيدة بما يكفي» عملية بطيئة وذاتية ويمكن أن تختلف اختلافاً كبيراً من معلم لآخر. تبحث هذه الورقة فيما إذا كان الذكاء الاصطناعي يمكنه مشاركة هذا العبء — بتقديم درجات سريعة ومتسقة وإيحاءات حول الأخطاء — دون أن يحل محل المعلم. تقدم دراسة نموذج حاسوبي جديد يسمى BERT-SVM EduScore صُمم خصيصاً لتقييم جودة الترجمات الإنجليزية في سياق تعليمي.
من مطابقة الكلمات السطحية إلى فهم أعمق
لعقود، كانت الحواسيب تقيم الترجمات أساساً بعدّ عدد الكلمات أو العبارات القصيرة المتطابقة مع إجابة مرجعية. أدوات معروفة مثل BLEU أو METEOR تقوم بذلك بسرعة، لكنها تواجه صعوبة مع مرونة اللغة الطبيعية: يمكن لجملتين أن تنقلان المعنى نفسه بصيغ كلامية مختلفة تماماً. في الصف، حيث يجرب الطلاب مرادفات وبُنى جمل متنوعة، قد تعاقب هذه المقاييس القديمة التراكيب المقنّنة الصحيحة وتوفر إرشاداً ضئيلاً حول الأخطاء المحددة. لذلك توجه الباحثون إلى أساليب أحدث تقارن المعاني بدلاً من الكلمات السطحية، باستخدام نماذج لغوية قوية مدرّبة على مجموعات نصية ضخمة.
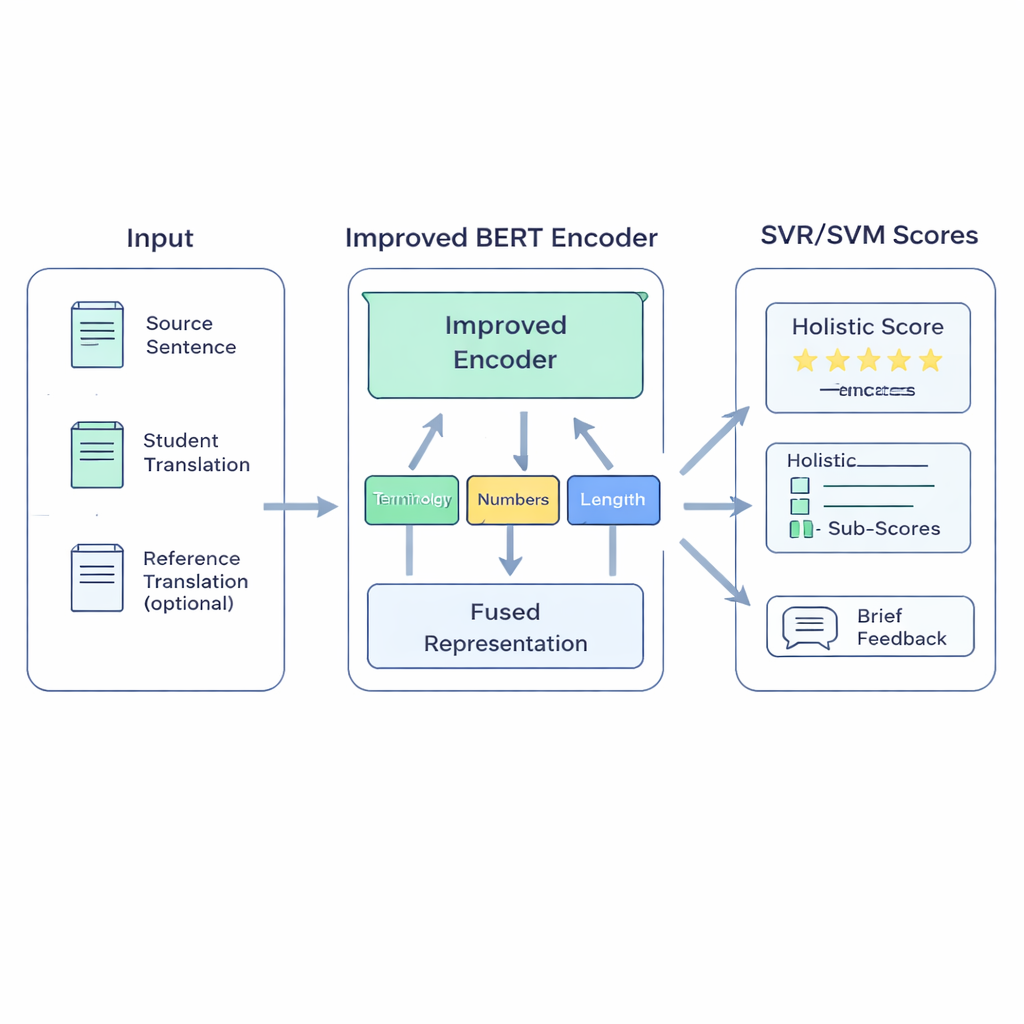
نموذج هجين مصمم للفصول الدراسية
يجمع نظام BERT-SVM EduScore المقترح بين فكرتين: فهم لغوي عميق وإحصاءات كلاسيكية متينة. أولاً، يستخدم نسخة محسنة من نموذج اللغة BERT لقراءة ثلاثة مقاطع نصية: الجملة الأصلية، ترجمة الطالب، وعند توفرها، الترجمة المرجعية. يحول BERT هذه النصوص إلى ملخص رقمي غني يعكس ليس فقط الكلمات الحاضرة، بل مدى تطابق المعاني. إضافة إلى ذلك، يُدرج النظام مجموعة صغيرة من الفحوص التي يصوغها المعلمون بدقة — مثل ما إذا كانت المصطلحات الفنية مترجمة باستمرار، ما إذا تم الحفاظ على الأرقام والوحدات، ما إذا كانت علامات الترقيم مناسبة، وما إذا كان طول الترجمة يتطابق مع الأصل.
كيف يتعلم النظام أن يقوّم مثل المعلم
ثم تُغذى هذه الإشارات إلى آلات الدعم الناقل Support Vector Machines، وهي عائلة من الخوارزميات المعروفة بفعاليتها مع بيانات محدودة. جزء واحد يتنبأ بدرجة إجمالية؛ أجزاء أخرى يمكن أن تولّد درجات منفصلة لمجالات مثل الدقة أو الطلاقة، أو تصنف الترجمات إلى فئات جودة. لمساعدة النموذج على التكيّف مع لغة الطابع الدراسي، أعاد المؤلفون تدريب BERT على نصوص تشبه أعمال الطلاب — نهج يسمى تكييف النطاق. كما صقلوا إحساس BERT بالتشابه والاختلاف بجعله يتدرّب على التمييز بين نسخ جيدة ونسخ سيئة معدلة قليلاً من الجمل. أخيراً، عندما تكون مقاييس تلقائية عالية الجودة مثل COMET أو BLEURT متاحة، يتعلم النظام تقليد بعض أحكامها، مستعيراً نقاط قوتها بينما يبقى موجهًا بتقييمات البشر.
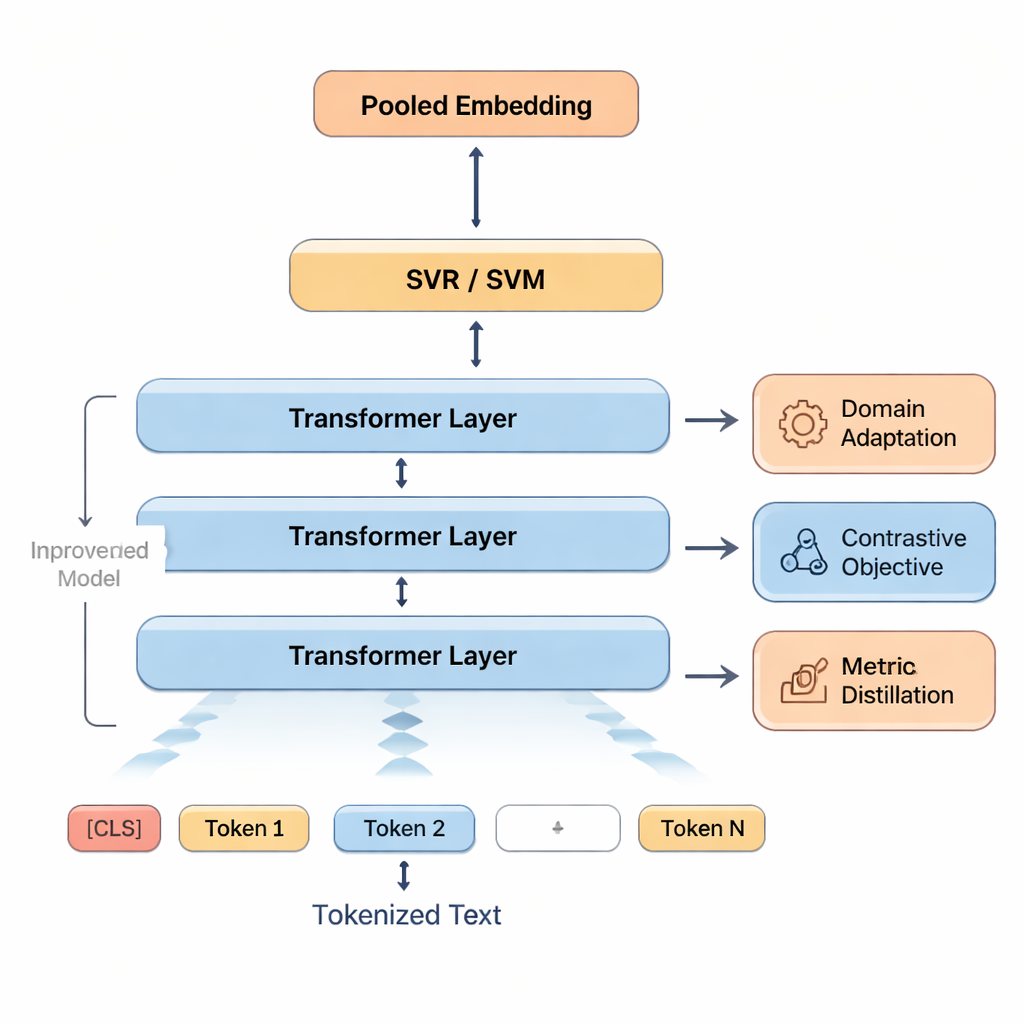
وضع النموذج تحت الاختبار
يقيم الباحثون BERT-SVM EduScore على مجموعة بيانات عامة كبيرة تحتوي على ترجمات آلية بين الإنجليزية والصينية مُقيمة من قبل بشر. وعلى الرغم من أن هذه ليست واجبات طلابية، فإن تقييمات مستوى الجملة تشبه تصحيح الصف وتوفر اختبار ضغط واقعي. تمت مقارنة النظام الجديد مع درجات تقليدية قائمة على الكلمات، ودرجات أحدث قائمة على المعنى، وعدة نماذج عصبية قوية. لم يتطابق مع أحكام البشر فقط — مظهراً اتفاقاً أعلى وأخطاء متوسطة أصغر — بل يعمل أيضاً بسرعة تكفي لمعالجة نحو 44 جملة في الثانية على معدات رسومية قياسية. تُظهر التجارب الدقيقة أن تكييف BERT مع النوع المناسب من النصوص هو العامل الأكثر فاعلية، بينما الحِرَف التعلمية الإضافية تمنح مكاسب ثابتة أصغر دون أن تبطئ النظام بشكل ملحوظ.
ماذا قد يعني ذلك للمعلمين والطلاب
بعبارة مبسطة، تُظهر الدراسة أن هجينة مصممة بعناية تجمع التعلم العميق والأساليب التقليدية يمكن أن تقوّم الترجمات بشكل أكثر موثوقية من الأدوات الآلية الحالية، مع البقاء سريعة بما يكفي للاستخدام الفوري داخل الصف. لا يعد BERT-SVM EduScore بديلاً فورياً للمعلمين البشر: فقد اختُبر فقط على ترجمات آلية، وليس على أعمال طلابية حقيقية، ولم يخضع لتجارب صفية أو اختبارات إنصاف. لكن النتائج توحي بأن مثل هذا النظام قد يساعد قريباً المعلمين بتقديم درجات مستقرة وإبراز المشكلات المحتملة — مثل المصطلحات المترجمة بشكل خاطئ أو الأرقام المفقودة — حتى يتركز التعليق البشري على جوانب أعمق وأكثر إبداعاً من الترجمة.
الاستشهاد: Lin, C. A hybrid intelligent assessment model for English translation education with improved BERT and SVM. Sci Rep 16, 5466 (2026). https://doi.org/10.1038/s41598-026-35042-2
الكلمات المفتاحية: تقييم الترجمة, تعليم اللغة, BERT, آلات الدعم الناقل, تقدير الجودة