Clear Sky Science · ar
حساب درجة تشابه الجمل عبر تعلم عميق هجيني مع تركيز خاص على جمل النفي
لماذا معنى الكلمة مهم لتقييم عادل
عندما يجيب الطلاب باستخدام كلماتهم الخاصة، يجب أن تفهم الحواسيب التي تساعد المعلمين في تصحيح هذه الإجابات أكثر من مجرد كلمات مفتاحية مشتركة. كلمة صغيرة مثل "ليس" يمكن أن تقلب معنى الجملة، وإذا أخفقت الأنظمة الآلية في رصد تلك القلْبة، قد يُقيَّم الطلاب بشكل غير عادل. تتناول هذه الورقة تلك المشكلة عبر تصميم طريقة جديدة للحواسيب لمقارنة معاني الجمل مع إيلاء اهتمام خاص لكيفية تغيير كلمات النفي لمعنى ما يُقال.
تحدي كلمات صغيرة لها تأثير كبير
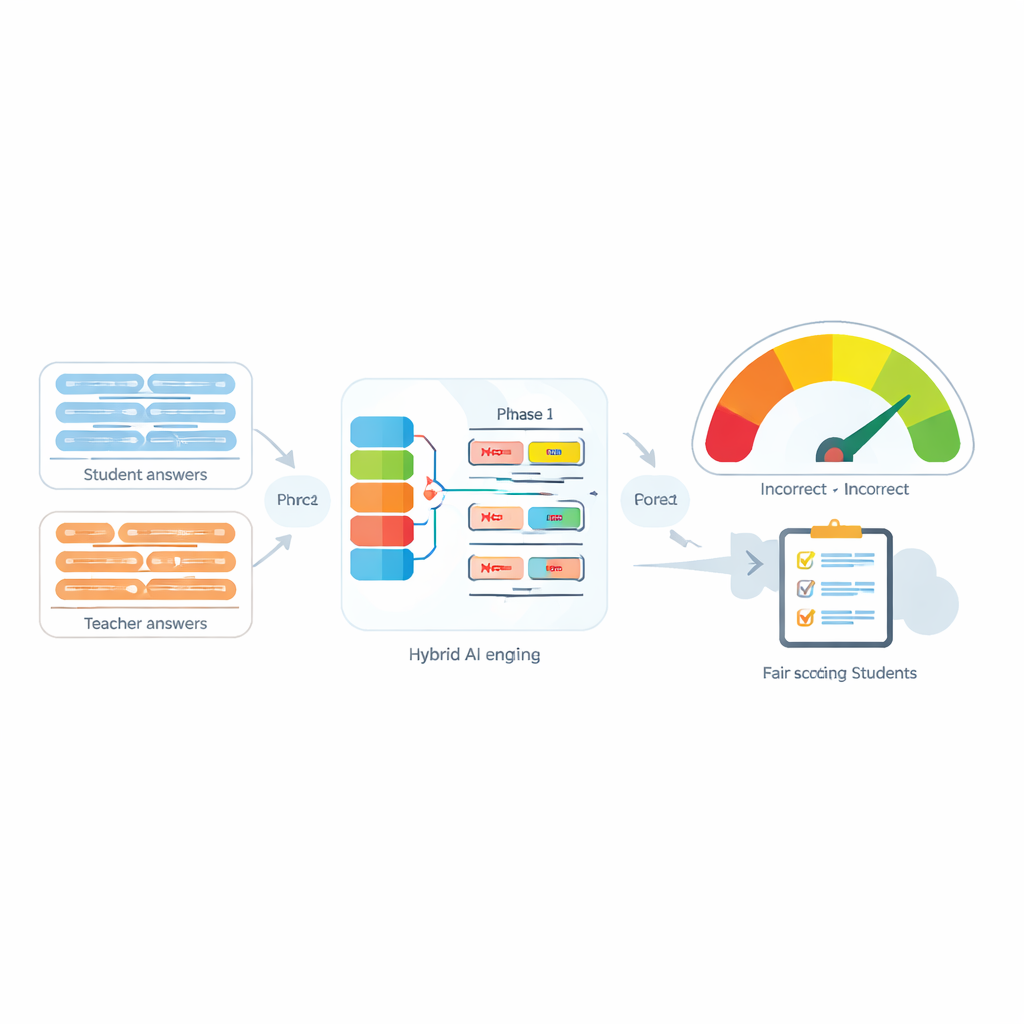
تُستخدم أنظمة التقييم الآلي بصورة متزايدة لتخفيف عبء العمل عن المعلمين عبر مقارنة إجابة الطالب بإجابة نموذجية. تقوم العديد من الأدوات الحديثة بذلك بتحويل كل جملة إلى "بصمة" رقمية ثم قياس مدى قرب هذه البصمات من بعضها. تعمل هذه الأدوات بشكل مرضٍ عندما لا يوجد نفي، لكنها غالباً ما تفشل عند ظهور كلمات مثل "ليس" أو "أبداً" أو "لا". على سبيل المثال، قد تبدو للجهاز "الطريقة دقيقة" و"الطريقة ليست دقيقة" متشابهتين بصورة مدهشة، رغم أنهما تعنيان عكس بعضهما. يبيّن المؤلفون أن ليس وجود النفي فحسب، بل أيضاً عدد كلمات النفي ومواقعها في الجملة، يمكن أن يغيّر المعنى المقصود تماماً.
بناء مجموعة بيانات تُعلّم التفصيلية
لتدريب نظام يفهم النفي حقاً، احتاج المؤلفون أولاً إلى بيانات تُبرز هذه الحالات المعقدة. أنشأوا مجموعة بيانات تشابه-الجمل-ذات-النفي، التي تحتوي على 8,575 زوجاً من الجمل من أربعة مجالات في علوم الحاسوب: نظم التشغيل، قواعد البيانات، شبكات الحاسوب، وتعلم الآلة. لكل زوج، عيّن البشر درجة تشابه تأخذ النفي بعين الاعتبار. تسجل مجموعة البيانات أيضاً عدد كلمات النفي في كل جملة ونوع نمط النفي المتبع، مثل وجود "ليس" واحد، أو عدد زوجي أو فردي من أدوات النفي، أو حالات أكثر تعقيداً حيث يتفاعل النفي مع كلمات ربط مثل "لأن" أو "لكن". تمنح هذه الوسوم التفصيلية النموذج تلميحات صريحة عن كيفية تشكيل النفي للمعنى.
محرك هجيني يجمع وجهات نظر متعددة
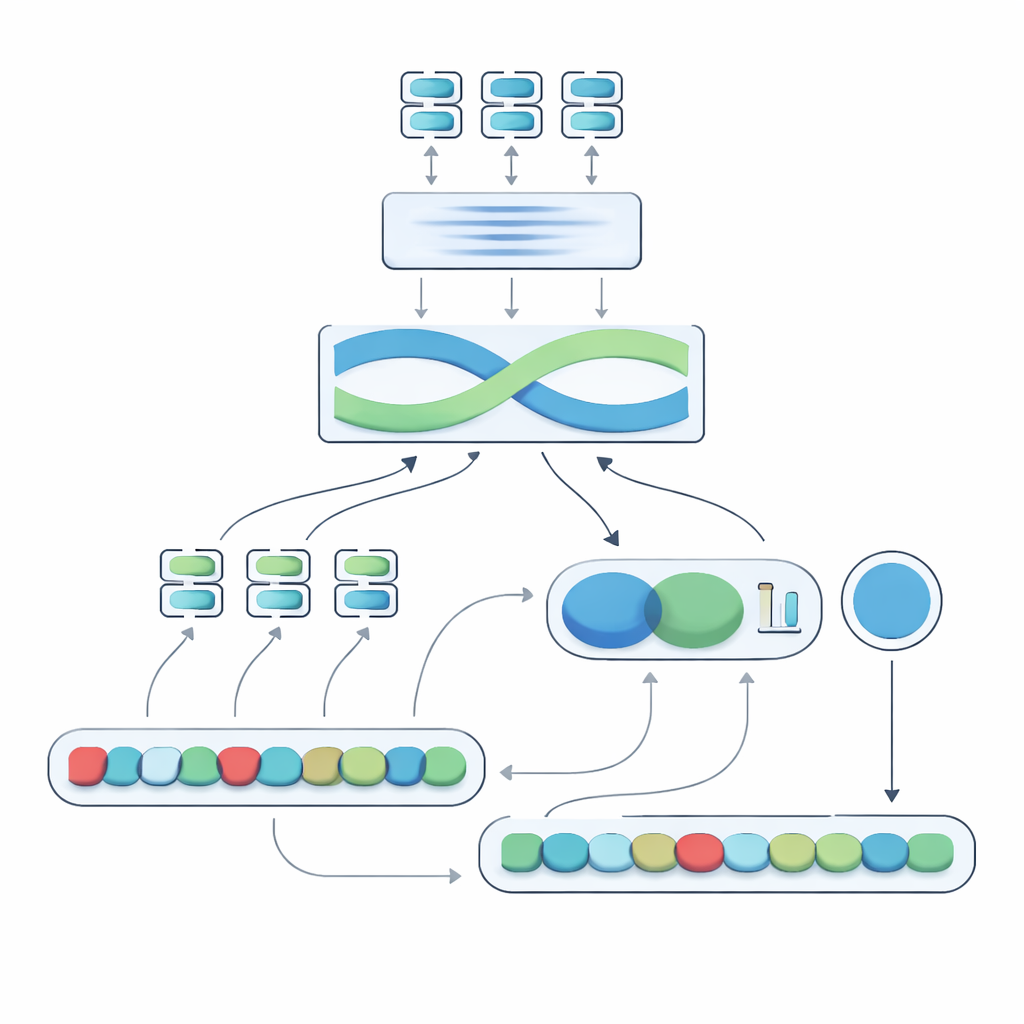
جوهر النظام المقترح، المسمّى مقيس-التشابه-المحاذي-للنفي، هو محرك ذو مرحلتين. في المرحلة الأولى، يمرّر النظام كل جملة عبر عدة نماذج لغوية مختلفة، كل منها يلتقط جوانب مختلفة قليلاً من المعنى. تُدمج مخرجاتها ثم تُمرَّر عبر شبكة متكررة ثنائية الاتجاه تنظر إلى الجملة ككل، آخذة بعين الاعتبار ترتيب الكلمات والسياق المحلي. ينتج عن هذا ملخّص مضغوط لكل جملة يكون أكثر ملاءمة للأساليب الدقيقة، بما في ذلك مواضع كلمات النفي بالنسبة للكلمات الأخرى.
تعليم النموذج أن يشعر بتأثير النفي
في المرحلة الثانية، يقارن النظام ملخّصي الجمل ويضيف معلومات صريحة عن النفي. يفحص مدى اختلاف الملخّصين ومدى تداخلهما، ويجمع تلك الإشارات مع ثلاث ميزات بسيطة: فرق عدد كلمات النفي، ما إذا كانت الجمل تحتوي أعداداً فردية أو زوجية من أدوات النفي (ما قد يعكس المعنى أو يلغي النفي)، وما إذا كان النفي يظهر في مواضع متقاربة نسبياً. تُدمَج كل هذه الدلائل في شبكة تنبؤ صغيرة تُنتج درجة تشابه من 0 إلى 100. عند تدريبها نهاية إلى نهاية على مجموعة البيانات المُنقّحة، تصبح هذه الدرجة حسّاسة للطريقة التي يعيد بها النفي تشكيل المعنى بدلاً من اعتبار "ليس" مجرد كلمة أخرى.
مدى أداء المقيس الجديد عملياً
لاختبار منهجهم، قيّم المؤلفون النظام على كل من مجموعة البيانات المخصصة لديهم وعلى معيار شائع الاستخدام لقياس تشابه الجمل. بالمقارنة مع خطوط أساس قوية معتمدة على المحولات (ترانسفورمر) تستخدم طرقاً قياسية، حقق المقيس الجديد خطأ تنبؤ أقل وجودة تصنيف أعلى بكثير، مع درجة F1 تقارب 0.97. في أمثلة مختارة بعناية، يعطي درجات تشابه منخفضة عندما يقلب النفي المعنى بوضوح ودرجات عالية عندما يُلغى النفي المزدوج فعلياً، في حين تميل النماذج المنافسة إلى المبالغة في تقدير التشابه. تؤكد دراسة النزع (ablation) أن المكوّنَين الرئيسيين—الطبقة المتكررة الواعية للتسلسل والميزات الصريحة للنفي—مهمان لهذا التحسّن في الأداء.
ماذا يعني هذا للطلاب والأدوات المستقبلية
بالنسبة للقارئ العادي، الخلاصة واضحة: طريقة قولنا "ليس" مهمة، ويمكن تعليم الآلات أن تنتبه لذلك. من خلال مزج نماذج لغوية متعددة، والمعالجة السياقية، والعدّ والمواضع البسيطة لكلمات النفي، يقدم المقيس المقترح طريقة أكثر عدلاً وموثوقية للحكم على ما إذا كانت جملتان تعنيان الشيء نفسه فعلاً. يمكن أن يساعد هذا أنظمة التصحيح الآلي على تجنّب أخطاء جسيمة، مثل معاملة "غير مسموح" كأنها "مسموح". وعلى الرغم من أن الطريقة أكثر استهلاكاً للحوسبة ولا تزال مركزة على مجالات تقنية، فإنها تشير إلى أدوات مستقبلية تلتقط المنطق الدقيق للغة اليومية بشكل أفضل، مما يجعل تقنيات اللغة الآلية أكثر ذكاءً ومصداقية.
الاستشهاد: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
الكلمات المفتاحية: تشابه الجمل, النفي في اللغة, التقييم الآلي, معالجة اللغة الطبيعية, نماذج التعلم العميق