Clear Sky Science · ar
مجموعة بيانات فائقة الدقة لفيديوهات الأوبرا التقليدية الصينية قائمة على دمج تدهور «الواقع+»
إحياء أفلام الأوبرا القديمة
توجد العديد من تسجيلات الأوبرا التقليدية الصينية فقط في شكل مقاطع فيديو هشة ومنخفضة الجودة. الزمن والغبار والنسخ المتكرر طمس الوجوه، وخفف ألوان الأزياء، وملأ المشاهد بضوضاء بصرية. تقدم هذه الورقة طريقة جديدة لتنظيف هذه الفيديوهات رقميًا وتوضيحها، ليس عبر إصلاح كل فيلم يدويًا، بل ببناء مجموعة تدريب متخصصة للذكاء الاصطناعي. الهدف هو مساعدة الحواسيب على تعلّم كيفية تحويل اللقطات المشوشة والمتقادمة إلى صور أوضح وأكثر حيوية، محافظين بذلك على جزء مهم من الذاكرة الثقافية العالمية.
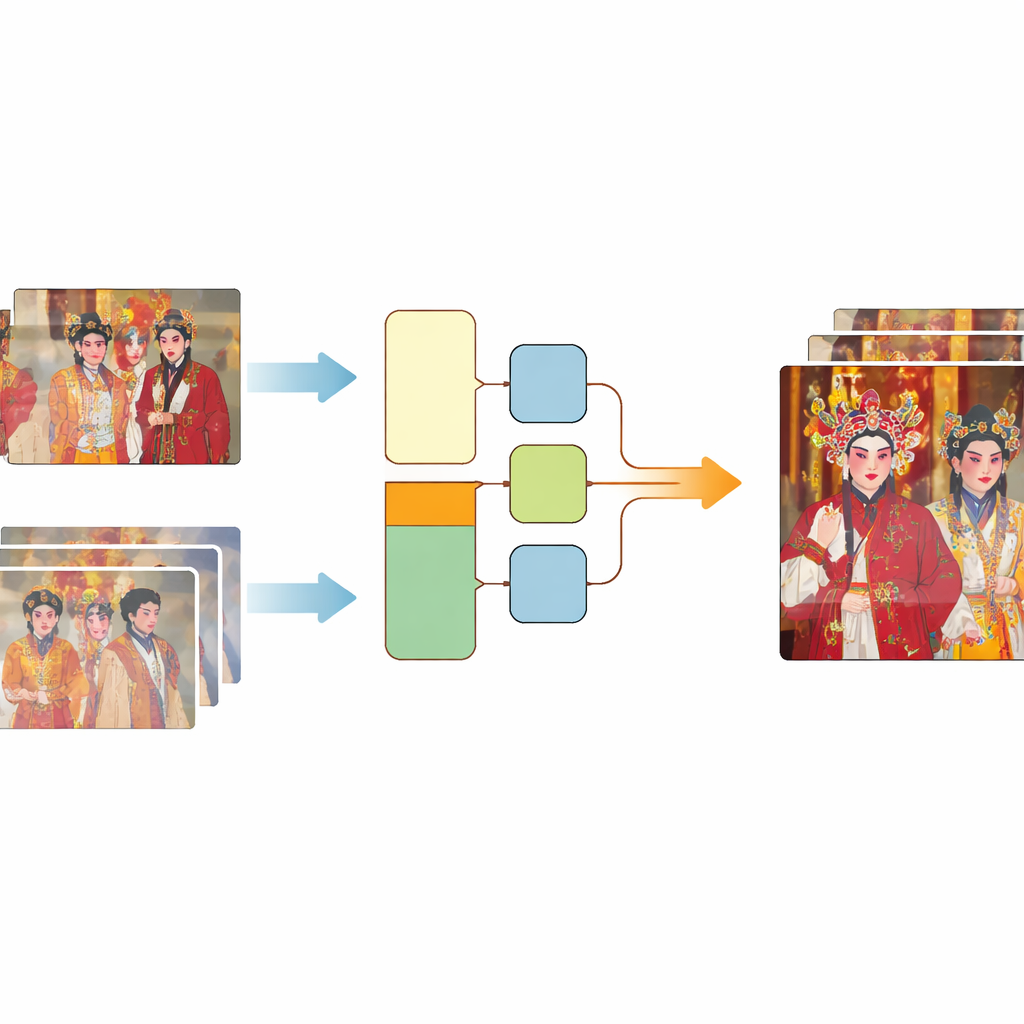
لماذا تبدو فيديوهات الأوبرا القديمة بهذه السوء
أُدرجت الأوبرا التقليدية الصينية، بما في ذلك أنماط مشهورة مثل الأوبرا البكّنية وكونكو، ضمن التراث الثقافي غير المادي للبشرية لدى اليونسكو. ومع ذلك، فإن العديد من الفيديوهات الباقية لهذه العروض خضعت لرحلة طويلة وقاسية. أولاً، أضافت معدات التصوير الأصلية ضبابية وضوضاء كاميرا. ثم تسبب التخزين على شريط أو فيلم أو أقراص خدوشًا، وتشوهات وفقدانًا للبيانات. أخيرًا، أدت النسخ المتكرر والضغط للنشر عبر الإنترنت والنقل الشبكي غير المستقر إلى تشوهات كتلية، ووميض، وحذف إطارات. النتيجة ليست مجرد ضبابية بسيطة، بل خليط معقّد من أنواع مختلفة من التلف، مما يجعل من الصعب على طرق الاستعادة تخمين كيف كان المشهد الأصلي ينبغي أن يبدو.
بناء أزواج من الإطارات المشوشة والواضحة
تدرّب طرق «الفيديو فائقة الدقة» الحديثة الحواسيب على توقع إطار حاد ومفصل من إطار منخفض الجودة. لتعلّم هذه المهارة، تحتاج إلى أمثلة كثيرة حيث يكون الإطار المشوش مطابقًا تمامًا لنفس المشهد بجودة عالية. تعتمد مجموعات التدريب الحالية عادةً إما على تلف مصطنع مبسط أو على لقطات حقيقية ليست مصفوفة بدقة بين النسختين منخفضة وعالية الجودة. أنشأ المؤلفون موردًا جديدًا اسمه CTOVSR بدءًا من أربعة أفلام أوبرا تقليدية استُعيدت احترافيًا من اللفات الأصلية إلى دقة عالية جدًا. ثم عثروا على نسخ بدقة قياسية من نفس العروض نُشرت عبر الإنترنت. خضعت هذه النسخ منخفضة الجودة لكامل عملية التدهور الواقعي، مما يجعلها صور «قبل» مثالية.
محاذاة كل إطار بعناية
لم تكن مطابقة الفيديوهات المستعادة والمتهالكة عملية بسيطة. الاختلافات في معدل الإطارات، اللقطات المفقودة، الشعارات المضافة، الحدود السوداء وتغير نسب العرض إلى الارتفاع تعني أن الطرق الآلية البسيطة لم تنجح. استخرج الفريق المقاطع القابلة للاستخدام ثم نفّذ محاذاة دقيقة ثلاثية المراحل. أولاً، استخدموا أداة مخصصة، eye_comparer، لإصلاح مشاكل التوقيت يدويًا مثل فقدان الإطارات، الإطارات غير المرتبة، و«الإطارات الشبحية» عند انتقال المشاهد. بعد ذلك، تعاملوا مع الفوارق المكانية عبر تراكب الإطارات في برامج تحرير الصور، محاذين المحتوى بدقة وقاطعين الحدود والشعارات والترجمات مع الحفاظ على أكبر قدر ممكن من المشهد. أخيرًا، نفّذوا فحصًا آليًا باستخدام مقياس تشابه، محتفظين فقط بأزواج الإطارات التي كانت شبه متطابقة في البنية. أنتجت هذه العملية 250 زوج تسلسلي عالي الجودة من العالم الحقيقي تغطي مئات الآلاف من الإطارات.
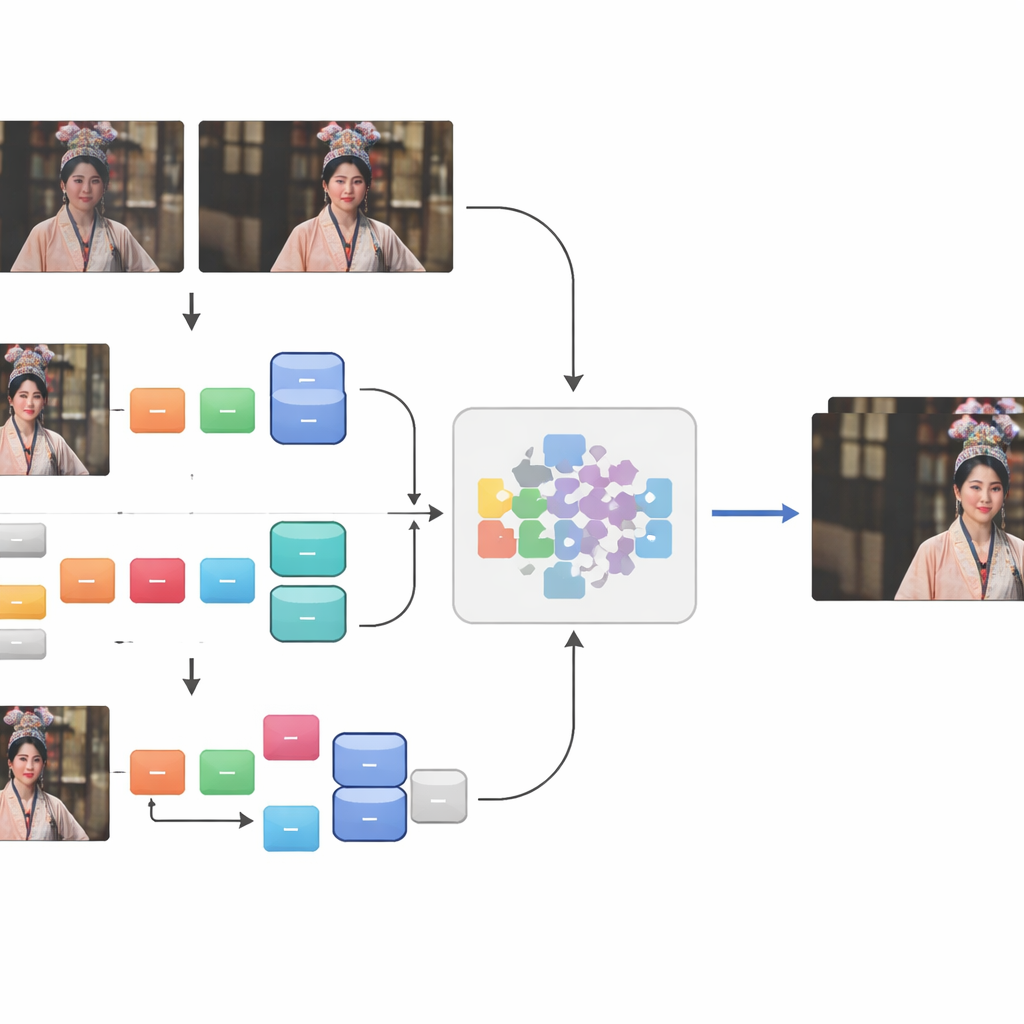
مزج التلف الحقيقي بالاهتراء المحاكى
رغم أن هذه الأزواج المصطفة بعناية التقطت التلف الحقيقي الواقعي، إلا أنها كانت لا تزال قليلة لتغطي تنوّع الطرق التي قد يتدهور بها الفيديو. لتوسيع مادة التدريب، أضاف المؤلفون مكوّنًا ثانيًا: تلفًا اصطناعيًا طُبق على 41 فيديو عالي الوضوح إضافي للأوبرا. قاموا بمحاكاة التلف المكاني—مثل الضبابية والضوضاء—عبر سلسلة مكونة من مرحلتين من خطوات التدهور، والتلف الزمني عن طريق ضغط الفيديوهات مع معيار قديم مستخدم على نطاق واسع يعكس كيفية ترميز العديد من المقاطع عبر الإنترنت تاريخيًا. بدمج هذا الجزء الاصطناعي مع أزواج «الواقع+»، جمعوا مجموعة بيانات CTOVSR التي تحتوي على 900 زوج فيديو منخفض-عالي الجودة مصفوف بدقة، كل منها يدوم 100 إطار ويعرض مجموعة واسعة من الأوبرات والمشاهد وظروف الإضاءة.
إثبات قيمة المجموعة الجديدة
لاختبار ما إذا كانت CTOVSR تساعد فعلاً الحواسيب في استعادة الفيديوهات القديمة، درّب المؤلفون عدة نماذج فائقة الدقة متقدمة باستخدام هذه المجموعة وحدها. قارنوا المخرجات بأساليب تغيير الحجم البسيطة ووجدوا أن النماذج المدربة أنتجت صورًا أوضح بكثير، مع تفاصيل أزياء أكثر حدة، ووضوح أكثر لماكياج الوجوه، وعيوب مرئية أقل. أظهرت دراسة استئصالية أن دمج التلف الحقيقي والاصطناعي كان أفضل بكثير من استخدام أي منهما منفردًا. جرّب الباحثون أيضًا نماذجهم المدربة على لقطات جديدة تمامًا: مقاطع أوبرا متقادمة عُثر عليها عبر الإنترنت وحتى فيديوهات عروض من ثقافات أخرى، مثل الأوبرا الإيطالية والرقص الكلاسيكي الهندي. قيّم المشاهدون المحترفون الإطارات المعززة بتقييمات أعلى بكثير من الأصلية أو النسخ المرفوعة الأساسية، مما يشير إلى أن النماذج المدربة على CTOVSR يمكن أن تعمم خارج المادة المحددة التي تحتويها.
حفظ التراث عبر بيانات أذكى
بعبارة بسيطة، لا تقدّم هذه الورقة خوارزمية استعادة جديدة فحسب؛ بل توفر «مادة تدريب» محضّرة بعناية تحتاجها هذه الخوارزميات لتتعلم. من خلال اقتران نسخ تالفة مع إصدارات عالية الجودة من لقطات الأوبرا التقليدية ثم إثرائها بتآكل محاكى واقعي، تمنح مجموعة بيانات CTOVSR الذكاء الاصطناعي فهمًا أفضل لكيفية تدهور الفيديو القديم وكيف ينبغي أن يبدو عند استعادته. يوفر هذا النهج مسارًا عمليًا ليس فقط لإضفاء حياة بصرية جديدة على الأوبرا التقليدية الصينية، بل أيضًا لحماية العديد من أشكال الفيديو التاريخي التي لا تُعوّض من الاندثار الرقمي.
الاستشهاد: Xi, W., Qin, B., Zhang, Y. et al. A Chinese Traditional Opera Video Super-Resolution Dataset Based on the “Real-world+” Degradation Fusion. Sci Data 13, 387 (2026). https://doi.org/10.1038/s41597-026-06776-5
الكلمات المفتاحية: فائقة الدقة للفيديو, حفظ التراث الرقمي, الأوبرا التقليدية الصينية, استعادة الصور, مجموعات بيانات الفيديو المتدهور