Clear Sky Science · ar
StatLLM: مجموعة بيانات لتقييم أداء نماذج اللغة الكبيرة في التحليل الإحصائي
لماذا يهم هذا لمستخدمي البيانات اليوميين
مع دخول أدوات الذكاء الاصطناعي مثل المساعدات المحادثية إلى العمل اليومي، يطلب منها مزيد من الناس إجراء حسابات، تشغيل تجارب، وتحليل بيانات. لكن عندما يكتب الذكاء الاصطناعي كوداً لدراسة إحصائية—مثل التحقق مما إذا كان علاج طبي جديد فعالاً أو استكشاف بيانات أداء المدارس—كيف نعرف أنه نفذ المهمة بشكل صحيح؟ يقدم هذا البحث StatLLM، مجموعة بيانات عامة مصممة لاختبار مدى قدرة نماذج اللغة الكبيرة على التعامل مع مهام التحليل الإحصائي الحقيقية، مما يمنح الباحثين والممارسين صورة أوضح عن متى يمكن الوثوق بكود مكتوب بواسطة الذكاء الاصطناعي—ومتى يجب التحفّظ.
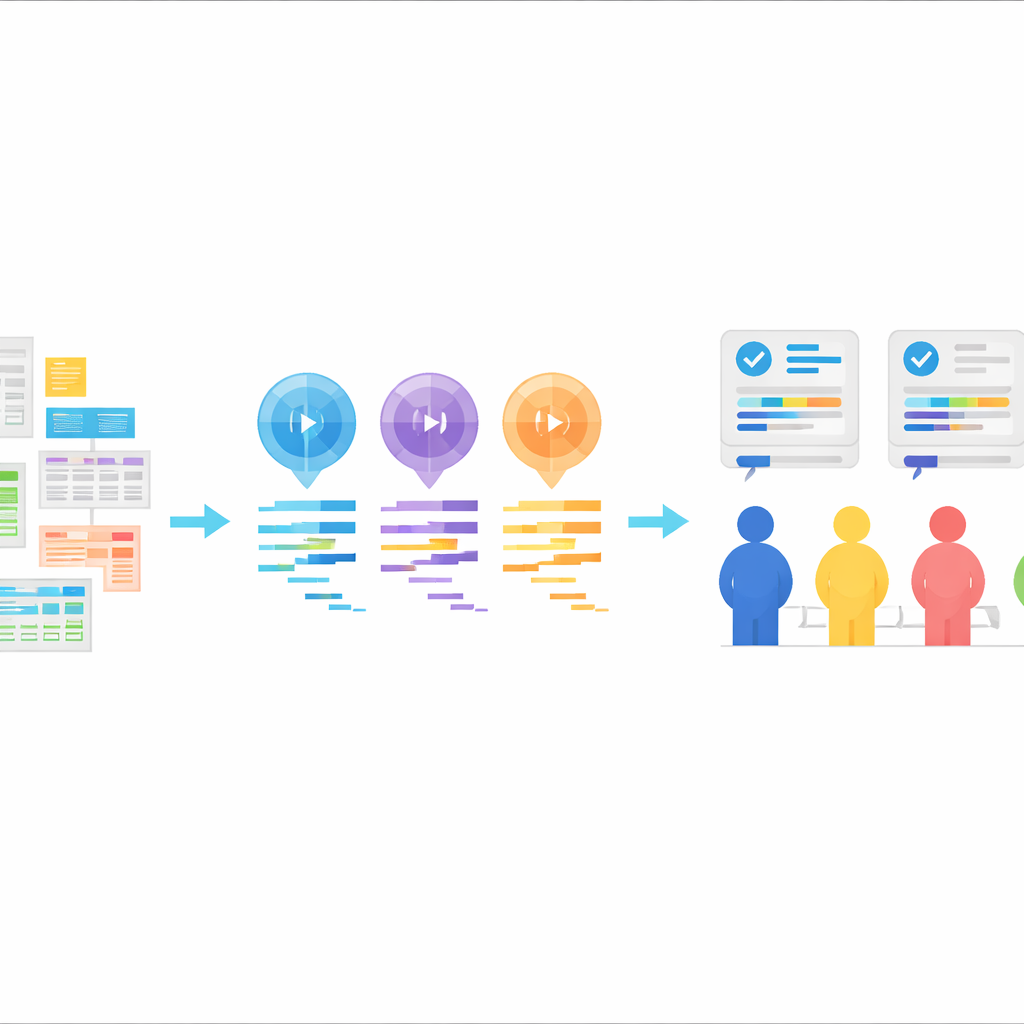
بيئة اختبار جديدة لكود الإحصاء المكتوب بالذكاء الاصطناعي
جوهر StatLLM هو مجموعة مركّبة بعناية من 207 مهام تحليل إحصائي مُستمدة من 65 مجموعة بيانات حقيقية مأخوذة من مجالات مثل التعليم والطب والأعمال والتمويل والهندسة والرياضة. تأتي كل مهمة بوصف بلغة مبسطة للمشكلة، وشرح مفصل لمجموعة البيانات ومتغيراتها، وقطعة قصيرة من كود SAS مكتوبة ومراجعة بواسطة خبراء بشر. تغطي المهام ما قد يتعلمه طالب جامعي قوي أو طالب ماجستير في الإحصاء: من ملخصات ومرئيات بيانات بسيطة إلى الانحدار، تحليل البقاء، وأساليب متقدمة أخرى. هذا يوفر اختباراً واقعياً بأسلوب مقررات دراسية وصناعة لمعرفة ما إذا كانت أدوات الذكاء الاصطناعي قادرة على فهم أسئلة عملية وترجمتها إلى خطوات تحليلية سليمة.
السماح للذكاء الاصطناعي بكتابة الكود، ثم تقييم عمله
باستخدام هذه المهام، طلب المؤلفون من ثلاثة نماذج لغة كبيرة—GPT-3.5 وGPT-4 وLlama‑3.1 70B—توليد كود SAS. تلقى كل نموذج نفس المدخلات: وصف للمهمة، وصف لمجموعة البيانات، ملف البيانات الفعلي، وتعليمات صريحة لإنتاج كود SAS. استُخدمت النماذج بطريقة «صفرية العيّنات» (zero-shot)، بمعنى أنها لم تُعرض أمثلة لكود SAS الصحيح مسبقاً. نُقحت استجاباتها بحيث يبقى الكود فقط دون شروحات. تحاكي هذه الإعدادات نمطاً شائعاً في العالم الحقيقي: يصف المستخدم ما يريد، يعيد الذكاء الاصطناعي كوداً، ثم يُشغل ذلك الكود في حزمة إحصائية.
الخبراء البشريون كالمعيار الذهبي
لمعرفة مدى جودة الكود الذي كتبه الذكاء الاصطناعي فعلاً، نظّم الفريق مراجعة بشرية صارمة. شكّل تسعة مستخدمين ذوي خبرة في SAS ثلاث مجموعات، ركّز كل منها على جانب من الأداء: ما إذا كان الكود نفسه صحيحاً منطقياً وسهل القراءة، وما إذا كان يعمل دون أخطاء، وهل تُجيب المخرجات الناتجة عن السؤال الأصلي بوضوح ودقة. لكل مهمة، خُلطت برامج SAS من النماذج الثلاثة بحيث لم يعرف المقيمون أي نموذج أنتج أي كود. أُعطيت الدرجات على مقياس من خمس نقاط ودمجت في مجموع كلي، مما أتاح رؤية متدرجة لنقاط القوة والضعف عبر مئات أزواج النموذج-المهمة. تجلس الآن هذه التقييمات الخبيرة إلى جانب كل الكود والمهام في مجموعة بيانات StatLLM.
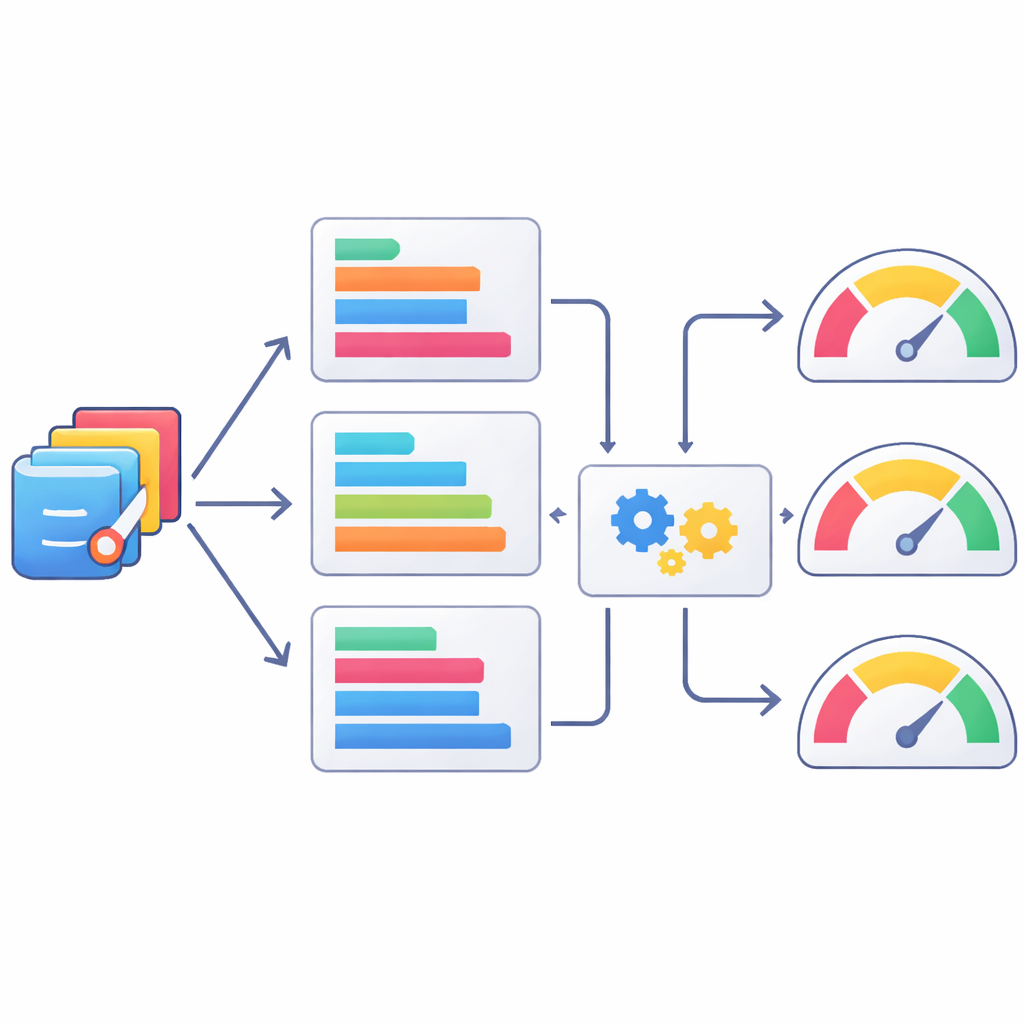
تعليم الآلات أن تحكم على الكود كما يفعل البشر
نظراً لأن المراجعة البشرية بطيئة ومكلفة، استكشف المؤلفون أيضاً مدى قدرة المقاييس الآلية القائمة على النص على أن تكون حكماً تقريبيًا على جودة الكود الإحصائي. قارنوا برامج SAS المولّدة آلياً بالإصدارات المصادق عليها بشرياً باستخدام مجموعة من مقاييس معالجة اللغة الطبيعية المعروفة، ثم تحققوا من مدى توافق هذه الدرجات مع التقييمات البشرية. بعض المقاييس، مثل متغيرات درجة ROUGE التي تتعقب التداخل في تسلسلات قصيرة من الرموز، ارتبطت بتقييمات البشر أفضل من غيرها، لكن كلها كانت متوافقة بشكل متوسط فقط. ثم خطا الفريق خطوة إضافية بتدريب نماذج تعلم آلي للتنبؤ بدرجات البشر من مجموعات هذه المقاييس. حسّنت طرق مثل XGBoost المطابقة مع التقييمات البشرية، لكنها لا تزال بعيدة عن التقاط حكم الخبراء بالكامل، مما يؤكد أن الدرجات الآلية هي، في أحسن الأحوال، بدائل جزئية.
البناء نحو أدوات إحصائية مستقبلية يقودها الذكاء الاصطناعي
خارج نطاق القياس المرجعي، يوضح المؤلفون كيف يمكن لـ StatLLM دعم أدوات واتجاهات بحثية جديدة. لأن كل مهمة موصوفة بمصطلحات عامة، يمكن استخدام نفس المشكلات لاختبار توليد الكود بلغات أخرى مثل R أو Python، أو حتى لدمج كود من لغات متعددة. يبرز البحث نهج التجميع ensemble الذي قد يمزج حلولاً مولّدة متعددة من الذكاء الاصطناعي لزيادة الموثوقية، ويعرض تطبيق R Shiny نموذجي حيث يحمّل المستخدم مجموعة بيانات ووصف المهمة، وينتج نظام الذكاء الاصطناعي تلقائياً كود R ويشغّله. كما توفر StatLLM منصة لتصميم واختبار برامج إحصائية من الجيل التالي تفهم التعليمات بلغة طبيعية مع الالتزام بمعايير واضحة وقابلة للقياس.
ماذا يعني هذا لاستخدام الذكاء الاصطناعي في تحليل البيانات
بالنسبة لغير المتخصصين، الخلاصة الأساسية هي أن الذكاء الاصطناعي قادر بالفعل على كتابة مقتطفات قصيرة من كود الإحصاء—لكن الموثوقية بعيدة عن الضمان، خاصة في المهام التي تتجاوز الأمثلة البسيطة. تقدم StatLLM طريقة شفافة وقابلة لإعادة الاستخدام لرؤية مدى أداء النماذج المختلفة، لتحسين الفحوصات الآلية على عملها، وتصميم أدوات تحليل بيانات أكثر أماناً ومتانة. ومع ظهور نماذج لغة أحدث، يمكن توصيلها بهذا المعيار الحي، مما يبقي الميدان أميناً بشأن ما يمكن وما لا يمكن للذكاء الاصطناعي القيام به بعد في الأعمال الإحصائية الجادة.
الاستشهاد: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
الكلمات المفتاحية: نماذج اللغة الكبيرة, التحليل الإحصائي, تقييم الكود, مجموعة بيانات قياسية, برمجة SAS