Clear Sky Science · ar
مجموعة بيانات باللغة الصينية للتعرّف على الكيانات المسماة للتراث الثقافي غير المادي
لماذا يتطلب حماية التقاليد الحية قراءة ذكية
في كل أنحاء العالم، تواجه التقاليد الحية مثل الموسيقى الشعبية، والحرف اليدوية، والمهرجانات المحلية خطر التلاشي من الحياة اليومية. في الصين، هناك كميات هائلة من النصوص التي تصف هذه الممارسات، لكن معظمها موجود في صفحات ويب طويلة يصعب على الناس — أو الحواسيب — البحث فيها أو تحليلها. تقدم هذه الدراسة مجموعة بيانات دقيقة الصنع باللغة الصينية ونموذج ذكاء اصطناعي متقدم يمكنه تلقائيًا اكتشاف قطع المعلومات الأساسية في تلك النصوص، مثل أسماء الحرف، والحرفيين الرئيسيين، والمواد، والأماكن. معًا، توفر هذه الأدوات سبلًا جديدة للمساعدة في حفظ ودراسة التراث الثقافي غير المادي على نطاق رقمي.
تحويل النص الفوضوي إلى معرفة منظمة
الفكرة الجوهرية وراء العمل هي تقنية تسمى التعرّف على الكيانات المسماة، التي تعلّم الحواسيب تمييز العناصر المهمة في النص: الأشخاص، والمواقع، والأزمنة، والمنظمات، وما إلى ذلك. بالنسبة للتراث الثقافي غير المادي، يعني هذا أيضًا التعرف على أنواع خاصة من الكيانات مثل أسماء مشاريع التراث، وتقنيات الحرف المحددة، والمواد المستخدمة. المشكلة أنَّه، حتى الآن، لم تكن هناك مجموعة بيانات عامة مخصصة لهذا المجال باللغة الصينية، وكانت أنظمة الأغراض العامة تواجه صعوبة مع الأوصاف الحية، والصياغات الشعرية، والتعابير الإقليمية الموجودة في وثائق التراث.
بناء مجموعة مركّزة من نصوص التراث
لسد هذه الفجوة، جمع المؤلفون مجموعة بيانات جديدة اسمُها ICH-NER من الشبكة الرسمية الصينية للتراث الثقافي غير المادي. ركّزوا على المدخلات المتعلقة بالحرف — مثل المنسوجات التقليدية، والسيراميك، والأعمال المعدنية، والنقش — لأن هذه الأوصاف غنية بتفاصيل العمليات والمواد. بعد تنظيف الإشعارات والتكرارات، صمّموا ثماني فئات رئيسية من الكيانات: أسماء عناصر التراث، والمواقع، والأشخاص، والمنظمات، والفترات الزمنية، والجماعات العرقية، والمواد، والحرف. وُسم كل حرف صيني في النصوص برمز بسيط يدل على ما إذا كان ينتمي إلى كيانٍ ما، وإذا كان كذلك فممَّا هو. تحتوي المجموعة في المجمل على 7,779 عينة وأكثر من 21,000 كيان معنَّم، ما يجعلها معيارًا قويًا للأبحاث المستقبلية.
قواعد دقيقة لوضع العلامات المتسقة
نظرًا لغياب نظام تصنيف معياري لهذا النوع من نصوص التراث، صاغ الباحثون أولًا إرشادات مفصّلة استنادًا إلى قوائم التراث الوطنية والوصف الرسمي. أجرَوا مرحلة تجريبية لمعالجة الحالات المعقَّدة، مثل الأماكن التي تُدرَج أيضًا كجزء من أسماء مشاريع، أو العبارات المتداخلة حيث يوجد كيان داخل آخر. ثم قام معلّم واحد مدرَّب بوَسْم مجموعة البيانات بالكامل باستخدام برنامج مفتوح المصدر، مع إعادة مراجعة متكررة للأعمال السابقة لتصحيح التباينات. تنقسم البيانات النهائية إلى مجموعات تدريب وتطوير، مع الاهتمام بالحفاظ على نسب متشابهة من كل نوع كيان ومزيج جيد من المصطلحات والأساليب الكتابية الإقليمية في كلا الجزئين.
تصميم نموذج ذكاء اصطناعي ملائم للغة التراث
إلى جانب مجموعة البيانات، تقترح الدراسة نموذجًا متخصّصًا للتعرّف يركّب عدة مكوّنات ذكاء اصطناعي حديثة. أولًا، يقوم مشفّر لغوي قوي (RoBERTa) بتحويل الحروف الصينية إلى تمثيلات رقمية واعية بالسياق تعكس كيف تُستخدم الكلمات في النص المحيط. بعد ذلك، يتعلّم مكوّن شبكة كولموغوروف–أرنولد أنماطًا خفيّة وغير خطية — مثل كيف تميل مواد معينة إلى الاقتران بتقنيات أو مناطق محددة. ثم يفحص طبقة انتباه ذات رؤوس متعددة العلاقات عبر الجملة بأكملها من زوايا متعددة، وأخيرًا تختار طبقة فك الترميز تسلسل العلامات الأكثر احتمالًا. صُمِّمت هذه البنية للتعامل مع الجمل الطويلة والمعقدة المليئة بالاستعارات والمرجعيات الثقافية متعددة الطبقات.
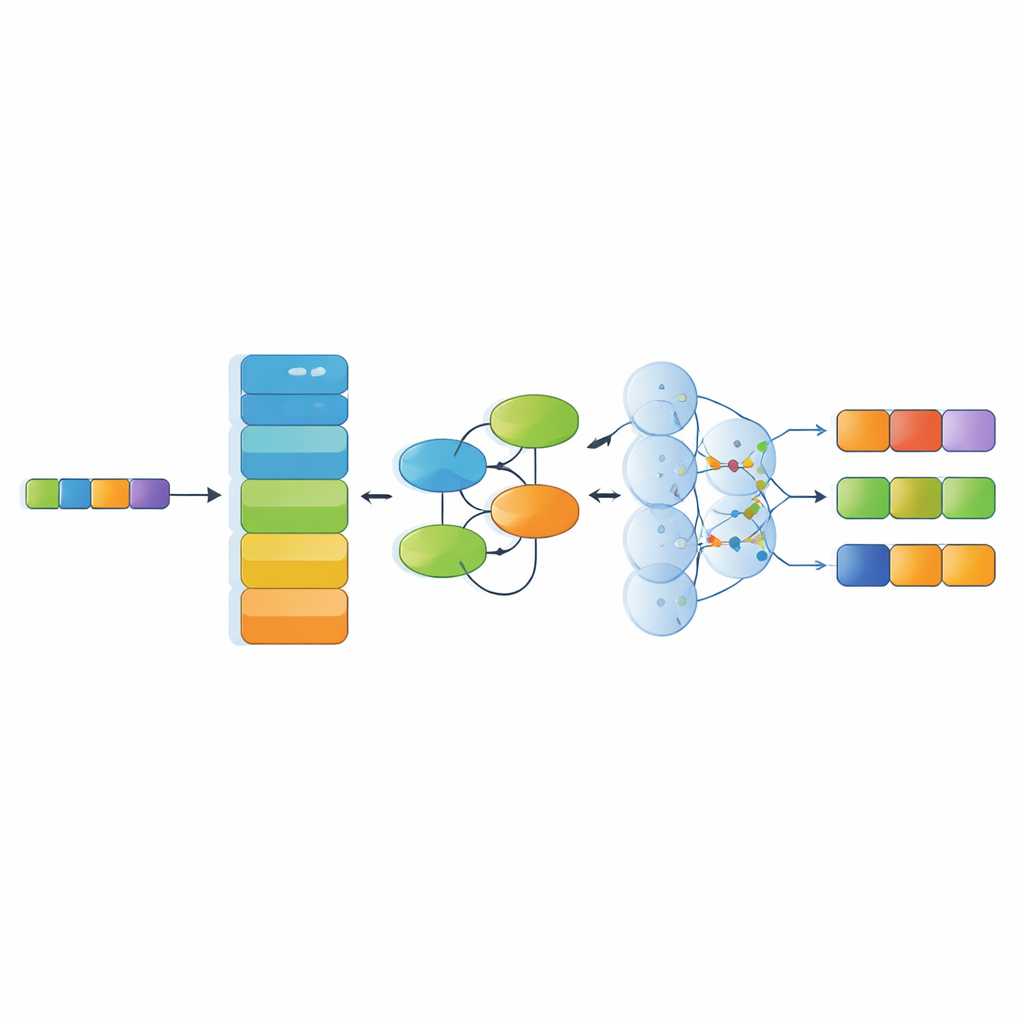
مدى فهم النظام لنصوص التراث
قارن المؤلفون نموذجهم بعدة طرق أساس قوية تُستخدم عادة في أبحاث اللغة، بما في ذلك أنظمة قائمة على الشبكات المتكررة، وبنى الشبكات للمقاطع في النص الصيني، وطريقة حديثة تُعامل الكيانات كسمات تُنقَّح خطوة بخطوة. على مجموعة بيانات ICH-NER، تفوّقت الطرق التي تعتمد على نماذج لغوية مُدرَّبة مسبقًا حديثة بوضوح على النهج الأقدم. حقّق نظامهم المجمّع RoBERTa–KAN–الانتباه–فك الترميز أفضل توازن إجمالي بين الدقّة والاستدعاء، لا سيما للفئات الصعبة مثل المواد، والمنظمات، وتقنيات الحرف، حيث تكون البيانات شحيحة نسبيًا والأوصاف غالبًا معقَّدة أو غامضة.
ماذا يعني هذا للثقافة الحية في عصر الرقمنة
عمليًا، تجعل مجموعة البيانات والنموذج الجديدين من الأسهل على الحواسيب استخراج من وماذا وأين ومتى من الأوصاف الغنية للحرف التقليدية. يمكن أن تغذي هذه المعلومات المهيكلة رسومات معرفية، وخرائط تفاعلية، أو أدوات بحث تساعد الباحثين والمنسقين والجمهور في استكشاف كيفية انتشار التقنيات، وكيف تشكّل عائلات أو مناطق معينة الحرفة، وكيف تتطوّر الممارسات عبر الزمن. ومع أن العمل تقني، فإن أثره إنساني: فهو يقدم طريقة لتحويل الأوصاف المبعثرة والمقيدة بالنص للتقاليد الحية إلى معرفة منظمة يمكن أن تدعم بشكل أفضل حفظ وفهم التراث الثقافي غير المادي.
الاستشهاد: Long, S., Li, W. A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage. Sci Data 13, 335 (2026). https://doi.org/10.1038/s41597-026-06700-x
الكلمات المفتاحية: التراث الثقافي غير المادي, التعرف على الكيانات المسماة, معالجة اللغة الصينية, مجموعات بيانات ثقافية, الحفظ الرقمي