Clear Sky Science · ar
مجموعة بيانات Kymata Soto للغة: مجموعة بيانات كهرومغناطيسية دماغية لمعالجة الكلام الطبيعي
الاستماع لكيفية سماع الدماغ للمحادثات الحقيقية
معظم ما نقوله ونسمعه يومياً هو محادثة عفوية، وليس كلمات منفصلة أو جمل مقروءة بعناية. ومع ذلك، اعتمدت الكثير من أبحاث الدماغ المتعلقة باللغة على مهام مصطنعة. تغيّر مجموعة بيانات Kymata Soto هذا الواقع من خلال تقديم مجموعة مفتوحة وغنية من تسجيلات نشاط الدماغ لأشخاص يستمعون ببساطة إلى مناقشات إذاعية حيوية بالإنجليزية والروسية، ما يمنح العلماء نافذة قوية جديدة على كيفية معالجة أدمغتنا للكلام الطبيعي.
مكتبة جديدة لاستجابات الدماغ للكلام الحقيقي
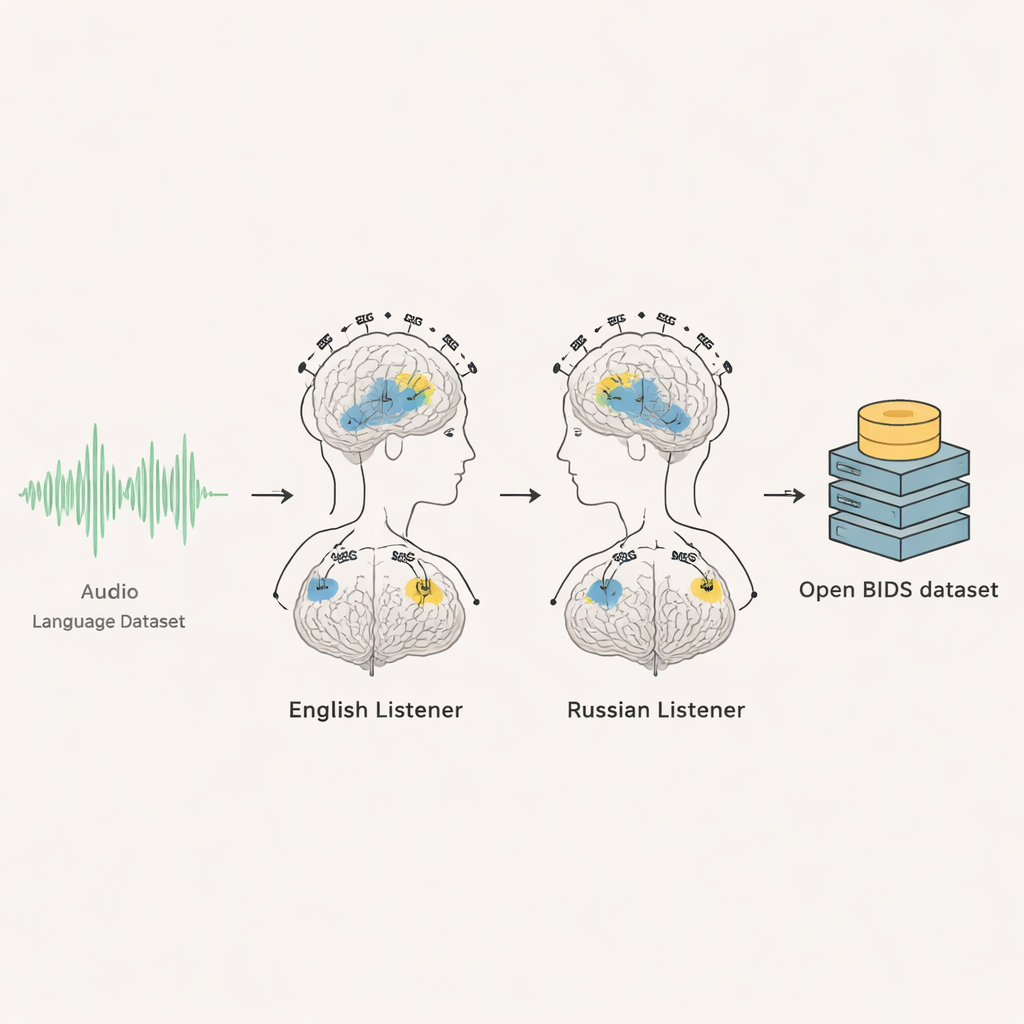
يجمع هذا المشروع طريقتين متقدمتين لتسجيل نشاط الدماغ — تخطيط كهربائية الدماغ (EEG) وتخطيط المجال المغناطيسي للدماغ (MEG) — من 35 بالغاً: 20 متحدثاً أصلياً للإنجليزية و15 متحدثاً أصلياً للروسية. بينما جلسوا بهدوء واستمعوا لحوالي ستة دقائق ونصف من محادثة على طراز الراديو بلغتهم الأم، سُجل نشاط دماغهم ألف مرة في الثانية. سمع كل شخص نفس المقطع الصوتي عدة مرات، مما أتاح للباحثين المتوسط عبر التكرارات وفصل الاستجابات الموثوقة للدماغ عن ضوضاء الخلفية. النتيجة هي سجل مفصل ومقفل زمنياً لكيفية تفاعل الدماغ، لحظة بلحظة، أثناء متابعة الناس لمناقشة تتكشف أمامهم.

محادثات عن الآيس كريم والقهوة
بدلاً من استخدام قصص كلاسيكية أو جمل مصطنعة، اختار الفريق مواضيع يومية وجذابة: تاريخ الآيس كريم للمستمعين الناطقين بالإنجليزية وتاريخ القهوة الكولومبية للمستمعين الناطقين بالروسية. جاء كلا التسجيلين من مناقشات استديو بي بي سي تضم ثلاثة متحدثين (رجلان وامرأة واحدة). حُررت المحادثات لتبلغ حوالي 400 ثانية وعُرضت عند مستويات استماع مريحة عبر سماعات الأذن. بعد كل تكرار، أجاب المشاركون عن سؤال أو سؤالين بسيطين متعددي الاختيارات حول المحتوى — فقط للتأكد من بقائهم متيقظين ومتابعين للقصة، وليس لاختبارهم بصورة صارمة.
تشغيل العينين مع إبقاء العقل منصتاً للصوت
أثناء الاستماع، حدّق المشاركون في علامة زائد مركزية على شاشة. حولها، انجرفت سحب من النقاط الملونة وتغيرت بشكل يبدو عشوائياً. خدمت هذه النقاط المتحركة هدفين: ساعدت في إبقاء نظرات الأشخاص ثابتة، مما يحسّن جودة البيانات، وخلقت أنماطاً محكومة للحركة البصرية واللون يمكن لباحثين آخرين تحليلها لاحقاً. ومن المهم أن هذه النقاط لم تكن متزامنة مع محتوى الكلام، لذا لم «توضح» القصة أو تضف معنى لها، لكنها وفرت خلفية بصرية متسقة يمكن دراستها إلى جانب الأصوات.
من إشارات الدماغ الخام إلى بيانات جاهزة للاستخدام
وثق الباحثون بعناية كل جزء من التجربة ونظموا مجموعة البيانات باستخدام معيار دولي لبيانات الدماغ يسمى BIDS. لكل متطوع، توجد تسجيلات EEG وMEG خام، وعلامات زمنية لبداية الصوت، وفعاليات بصرية ثانية تلو الثانية، ومقاطع تدريبية. كما يقدم الفريق الملفات الصوتية الأصلية، والنصوص الكاملة، وتوقيتاً دقيقاً لبداية كل كلمة وحتى كل صوت منطوق فردي. يتضمنون سكربتات لتمكين الآخرين من إعادة إنتاج المقتطفات الصوتية نفسها تلقائياً. لمجموعة اللغة الإنجليزية، تُشارك صور رنين مغناطيسي دماغية مُجهّلة الهوية بحيث يمكن رسم استجابات الدماغ على تشريح الدماغ الفردي؛ أما لمجموعة اللغة الروسية، فلم يسمح الموافقة بمشاركة صور الرنين المغناطيسي، لذا يُنصح المستخدمون بالاعتماد على قوالب دماغ متوسطة معيارية.
التحقق من أن الإشارات منطقية
للتأكد من مصداقية البيانات علمياً، أجرى المؤلفون تحليلات تحقق ركزت على كيفية تتبع الدماغ لتغيرات شدة الصوت مع الزمن. حوّلوا الصوت إلى عدة أوصاف رياضية لـ«الشدة المتغيرة زمنياً» ثم فحصوا أين ومتى تلاقت استجابات الدماغ مع تلك أنماط الشدة. لكل من المستمعين بالإنجليزية والروسية، أظهر الدماغ أنماط توقيت متشابهة، متوافقة مع ما ورد في أعمال سابقة. هذا التوافق عبر اللغات ومع الدراسات الماضية يعد مؤشراً قوياً على أن التسجيلات نظيفة وموثوقة وجاهزة ليبني عليها الآخرون.
لماذا هذا الأمر مهم لأبحاث الدماغ واللغة المستقبلیة
بالنسبة لغير المتخصصين، الخلاصة الأساسية هي أن مجموعة البيانات هذه تمثل موردًا جديدًا مشتركًا يتيح لفرق بحثية متعددة دراسة كيفية معالجة الكلام العفوي والواقعي في الدماغ. لأنها مفتوحة ومفهرسة بشكل جيد ومسجلة بلغتين مختلفتين، يمكن أن تدعم مشاريع تتراوح من أسئلة أساسية حول كيفية فهمنا للمحادثة، إلى مقارنات بين اللغات، وصولاً إلى جهود طموحة لفك شفرة الكلام مباشرة من نشاط الدماغ. باختصار، مجموعة بيانات Kymata Soto للغة تهدف أقل إلى الإجابة على سؤال واحد محدد وأكثر إلى منح المجتمع العلمي أساساً مشتركاً عالي الجودة لاستكشاف كيف تجعل أدمغتنا منطق المحادثات التي تملأ حياتنا اليومية.
الاستشهاد: Yang, C., Parish, O., Klimovich-Gray, A. et al. Kymata Soto Language Dataset: an electro-magnetoencephalographic dataset for natural speech processing. Sci Data 13, 254 (2026). https://doi.org/10.1038/s41597-026-06579-8
الكلمات المفتاحية: الدماغ واللغة, إدراك الكلام, EEG MEG, محادثة طبيعية, بيانات تصوير عصبي مفتوحة