Clear Sky Science · ar
موثوقية نماذج اللغة الكبيرة كمساعدين طبيين للعامة: دراسة عشوائية مسجَّلة مسبقًا
لماذا قد لا يكون هاتفك أفضل طبيب أول
يلجأ المزيد من الناس إلى روبوتات المحادثة المدعومة بالذكاء الاصطناعي طلبًا للمساعدة عندما يشعرون بتوعك، على أمل الحصول على إجابات سريعة حول ما إذا كان هناك سبب للقلق، وما الذي قد تعنيه أعراضهم، وما إذا كان ينبغي التوجّه إلى المستشفى. تطرح هذه الدراسة سؤالًا بسيطًا لكنه عاجل: إذا استخدم الأشخاص العاديون نماذج لغوية قوية كمساعدين طبيين في المنزل، هل يتخذون فعلاً قرارات أفضل بشأن صحتهم—أم أن التكنولوجيا قد تُعطي إحساسًا زائفًا بالأمان؟
اختبار الآلات الذكية بحالات شبيهة بالواقع
لاكتشاف ذلك، صمَّم باحثون في المملكة المتحدة عشرة سيناريوهات طبية واقعية، مثل صداع شديد مفاجئ أو صعوبة في التنفس، استنادًا إلى حالات شائعة قد يواجهها الكثيرون منا. اتفق فريق من الأطباء ذوي الخبرة على "الخطوة التالية" الأفضل لكل سيناريو—تتراوح من البقاء في المنزل والعناية الذاتية إلى استدعاء سيارة إسعاف—وسجّلوا الحالات الرئيسية التي ينبغي على شخص حريص أن يأخذها بعين الاعتبار. ثم تم توزيع 1,298 بالغًا من أنحاء المملكة المتحدة عشوائيًا على واحد من أربعة خيارات: استخدام واحد من ثلاثة روبوتات دردشة رائدة، أو استخدام ما يعتمدون عليه عادة في المنزل، مثل البحث على الويب أو الخبرة الشخصية.
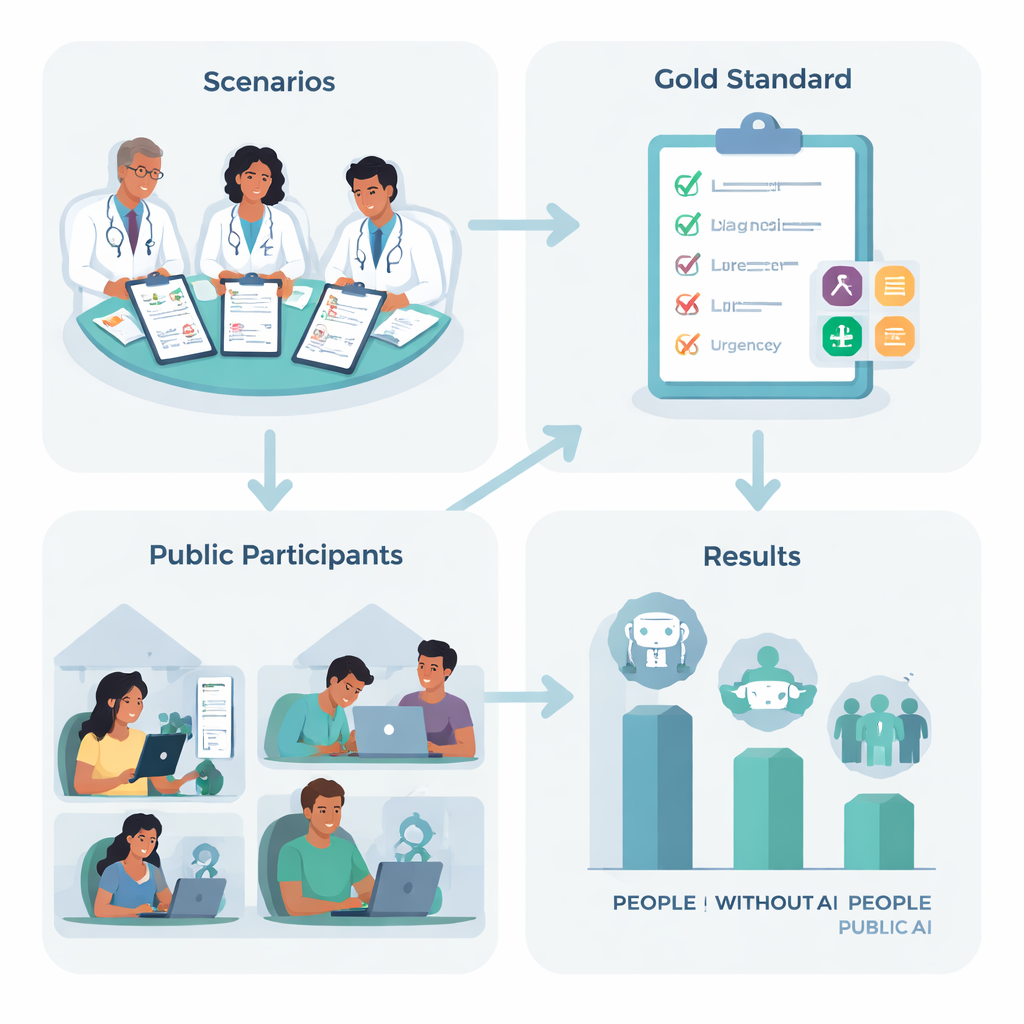
أداء الناس والآلات—منفصلين ومجتمعين
عندما اُختبرت نماذج اللغة بمفردها، عبر تزويدها بوصف الحوادث الكامل وطلب تشخيص وإجراء موصى به مباشرة، قدّمت أداءً ملفتًا. عبر الأنظمة الثلاثة، اقترحوا بشكل صحيح على الأقل حالة طبية ذات صلة في نحو 95% من الحالات واختاروا مستوى الخطورة الصحيح في أكثر من نصف الحالات—أفضل بكثير من التخمين العشوائي. على الورق، بدت هذه الأنظمة مرشحة قوية لإرشاد المرضى القلقين.
عندما تلتقي نصيحة الذكاء الاصطناعي بالناس الحقيقيين
لكن بمجرد دخول المستخدمين العاديين إلى المعادلة، تغيَّرت الصورة. لم يكن المشاركون الذين استخدموا الذكاء الاصطناعي أكثر دقة من مجموعة التحكم في اختيار ما ينبغي فعله لاحقًا، وبدلاً من ذلك كانوا أسوأ في تسمية الحالات الأساسية ذات الصلة. كان الأشخاص في المجموعة غير المعتمدة على الذكاء الاصطناعي أكثر احتمالًا بنحو 1.8 مرة لتحديد حالة صحيحة مقارنة بمن استخدموا روبوتات الدردشة. قلل معظم المشاركين في جميع المجموعات من مدى خطورة الوضع. بعبارة أخرى، لم تساعد إمكانية الوصول إلى نموذج لغوي متقدم الناس على فهم أعراضهم بشكل أفضل، ولم تدفعهم بوضوح نحو خيارات أكثر أمانًا.
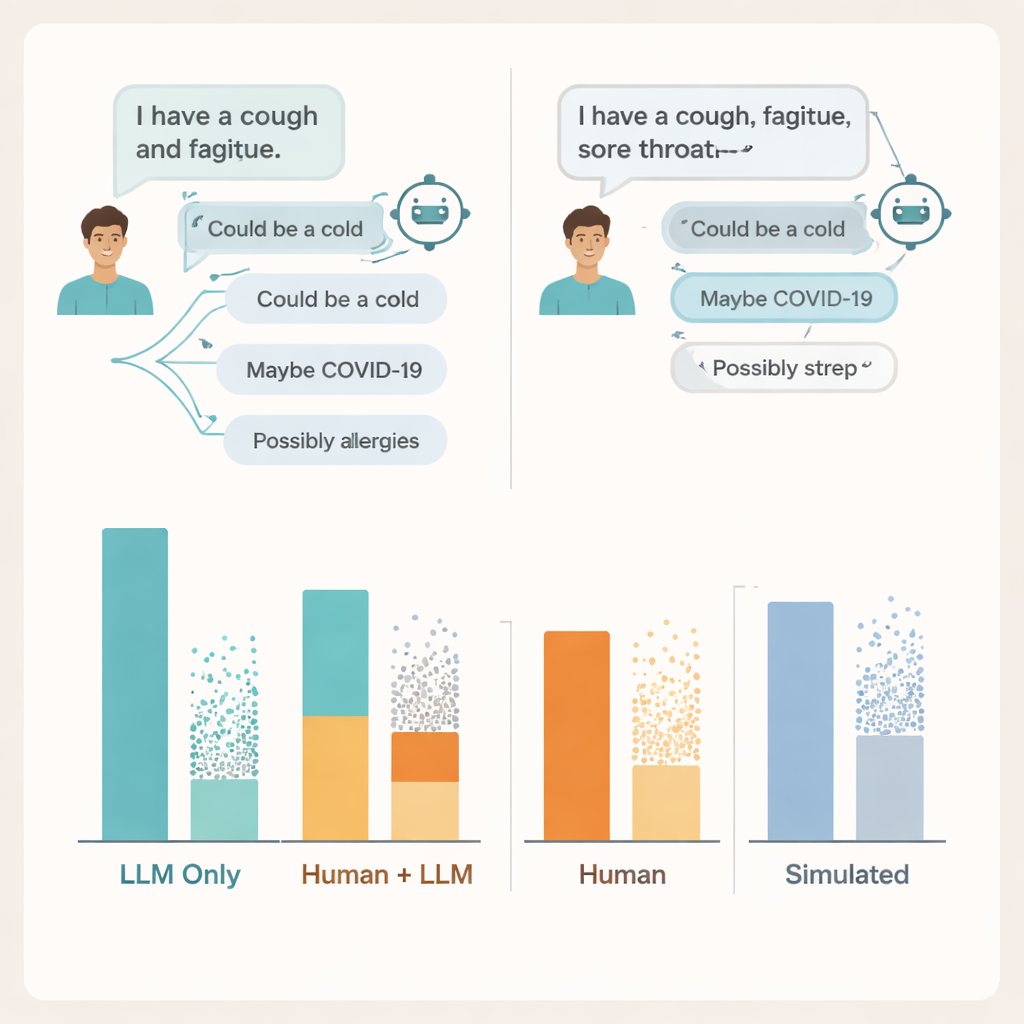
أين تنهار المحادثة
لفهم السبب، غاص الباحثون في نصوص المحادثات الفعلية. ووجدوا مشكلات على جانبي المحادثة. كثير من المستخدمين لم يشاركوا تفاصيل كافية عن أعراضهم حتى يتمكن الذكاء الاصطناعي من تقديم نصيحة موثوقة—تمامًا كما قد يُغفل المرضى معلومات أساسية عند التحدث إلى الطبيب. النماذج نفسها غالبًا ما ذكرت حالة ذات صلة واحدة على الأقل، لكنها أضافت أيضًا عدة احتمالات غير صحيحة أو مُشتتة، وكافح المستخدمون لمعرفة أي الاقتراحات ذات أهمية. في بعض الحالات، أدت أوصاف أعراض شبه متطابقة إلى نصائح مختلفة بشكل حاد من نفس النموذج، مما صعَّب على الناس تكوين شعور واضح بمواضع الثقة فيما يظهر على الشاشة.
لماذا تختزل الاختبارات القياسية المخاطر الحقيقية
قارن الفريق أيضًا هذه النتائج بطريقتين شائعتين لتقييم الذكاء الاصطناعي الطبي: أسئلة امتحانية متعددة الخيارات ومحادثات "مريض" مُحاكاة تمامًا تُجرى بين نموذجين. في كلتا الحالتين، بدت الأنظمة مرة أخرى قوية، محققة أو متجاوزة درجات النجاح المعتادة في أسئلة على غرار الامتحان وأداءً أفضل مع المرضى المحاكين مقارنة بالحالات الحقيقية. ومع ذلك، لم تتطابق الدرجات العالية في الامتحانات والمحادثات المصقولة مع مدى نجاح الأشخاص الحقيقيين عند استخدام نفس الأدوات. يرى المؤلفون أن المقاييس التي تختبر المعرفة بمعزل عن السياق تغفل الطبيعة الفوضوية والهشة للتفاعلات البشرية-الذكاء الاصطناعي الحقيقية.
ماذا يعني هذا للمرضى ونظم الرعاية الصحية
تستنتج الدراسة أنه في الوقت الراهن، ليست نماذج اللغة العامة الحالية جاهزة لتعمل كمستشارين خط أمامي غير مراقبين للجمهور. فهي بالطبع تحتوي على قدر كبير من المعرفة الطبية، لكن هذه المعرفة لا تترجم تلقائيًا إلى خيارات أكثر أمانًا عندما يكتب الأشخاص القلقون أسئلة جزئية ومشوشة في المنزل. إن جعل الذكاء الاصطناعي مفيدًا حقًا في سياقات عالية المخاطر مثل الرعاية الصحية سيتطلّب أكثر من مجرد تحسين درجات الامتحان—سيتطلب تصميمًا دقيقًا، واختبارًا مع مستخدمين حقيقيين متنوعين، وضوابط أشد لطريقة جمع المعلومات وشرحها وبناء الثقة خلال تفاعل المحادثة.
الاستشهاد: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
الكلمات المفتاحية: روبوتات الدردشة الطبية, التشخيص الذاتي, الذكاء الاصطناعي في الرعاية الصحية, اتخاذ قرارات المرضى, نماذج اللغة الكبيرة