Clear Sky Science · ar
تلخيص الأدبيات العلمية باستخدام نماذج لغوية مدعومة بالاستخراج
لماذا متابعة العلم صعبة للغاية
يظهر كل عام ملايين الأوراق العلمية الجديدة على الإنترنت. لا يمكن لأي باحث بشري قراءة كل هذه الأعمال، ومع ذلك قد تكون هناك علاجات طبية هامة، ونتائج حول المناخ، واختراقات تكنولوجية مخبأة في هذا الفيضان من المعلومات. تستكشف هذه المقالة ما إذا كانت أنظمة الذكاء الاصطناعي المتقدمة قادرة على مساعدة العلماء في البحث عبر هذا المحيط من الدراسات وتجميعها في ملخصات واضحة ويمكن الوثوق بها—دون اختلاق معلومات.
نوع جديد من المساعد البحثي
يعرف المؤلفون OpenScholar، نظام ذكاء اصطناعي صمم خصيصًا لقراءة وتلخيص الأدبيات العلمية. على عكس الدردشات العامة، يرتبط OpenScholar ارتباطًا وثيقًا بقاعدة بيانات مفتوحة ضخمة تضم حوالي 45 مليون ورقة بحثية، تسمى OpenScholar DataStore. عندما يطرح الباحث سؤالًا—مثل كيفية تبريد جسيمات معلقة مغناطيسيًا أو أي الأساليب تعمل أفضل لتصوير الدماغ—يبحث النظام أولًا في هذه القاعدة عن مقاطع ذات صلة، ثم يصيغ إجابة مع استشهادات داخل النص، على غرار مقالة مراجعة مكتوبة بشريًا. يكرر هذا الإجراء عدة مرات، منتقدًا ومنقحًا مسوداته لتحسين الوضوح والشمولية وجودة الاستشهادات.
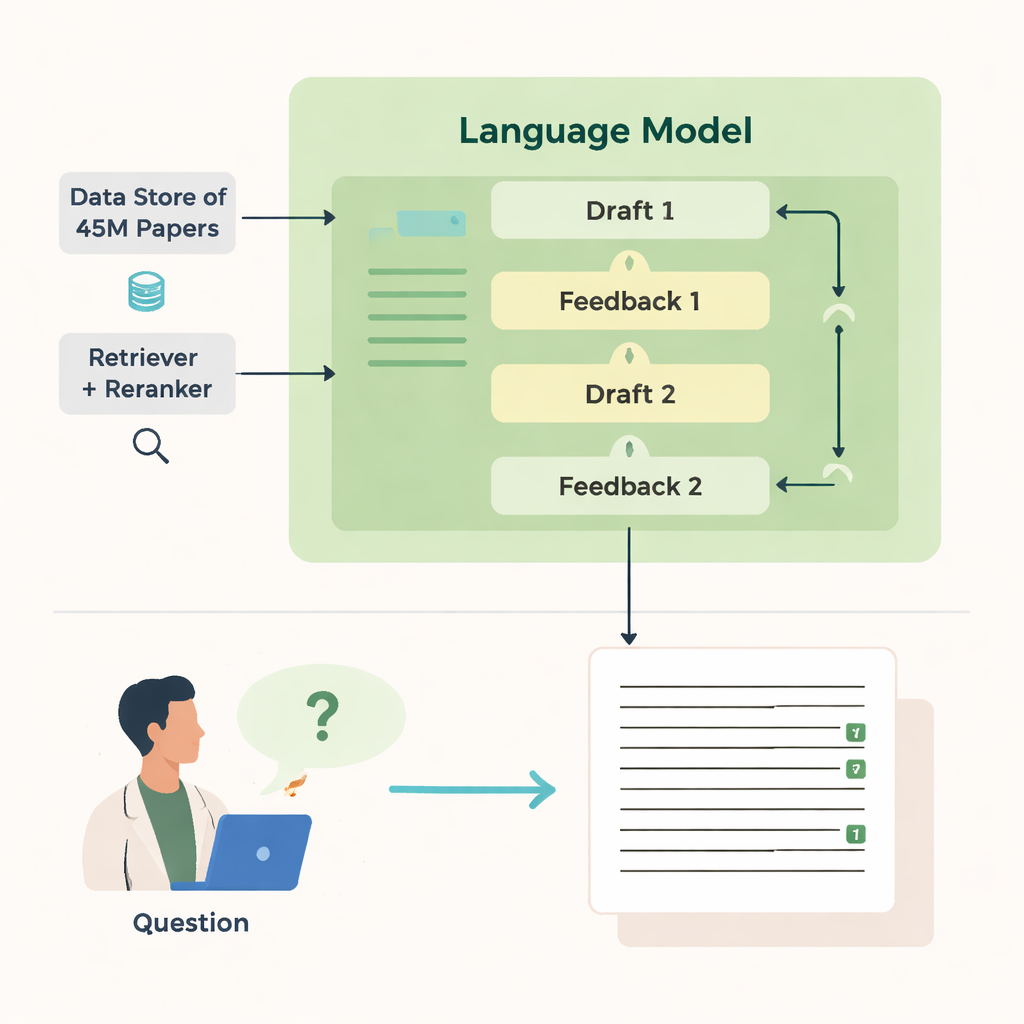
كيف يبحث ويكتب
تكمن قوة OpenScholar في عدة مكونات منسقة. يقوم مكوّن «المسترجع» بمسح تمثيلات نصية محسوبة مسبقًا لملايين المقالات للعثور على مقتطفات واعدة، بينما يعيد «إعادة الترتيب» ترتيب هذه المقتطفات للتركيز على الأكثر صلة. ثم يستخدم النموذج اللغوي هذا الدليل لإنتاج إجابة طويلة مع مراجع مرقمة. بعد المسودة الأولى، يولد النموذج ملاحظات لنفسه—مشيرًا إلى وجهات نظر مفقودة أو بنية ضعيفة أو دلائل هزيلة—وعند الحاجة يبدأ عمليات بحث مستهدفة إضافية. ثم يعيد كتابة الإجابة، مضمِّنًا أوراقًا جديدة ومعدلًا الاستشهادات. فحص نهائي يضمن أن العبارات التي تحتاج دعمًا مدعومة على الأقل بمصدر مسترجع واحد.
وضع الادعاءات والاستشهادات على المحك
لفحص ما إذا كان OpenScholar مفيدًا فعلاً، أنشأ المؤلفون ScholarQABench، معيارًا كبيرًا مصممًا لمحاكاة أسئلة مراجعة الأدبيات الحقيقية. يضم ما يقرب من 3000 سؤال مكتوب من خبراء ومئات الإجابات الطويلة عبر علوم الحاسوب والفيزياء وعلوم الأعصاب والطب الحيوي. والأهم أن هذه الأسئلة عادةً تتطلب قراءة عدة أوراق، لا مجرد ملخص واحد. قيّم الفريق الأنظمة عبر محاور متعددة: الصحة الواقعية، مدى تغطية الإجابات للنقاط الرئيسية، وضوح الكتابة ومدى دقة الاستشهادات في عكس الأوراق الأساسية. جمعوا فحوصًا آلية مع تقييمات مفصلة من خبراء بدرجة دكتوراه الذين قارنوا الإجابات المولدة بالذكاء الاصطناعي مع تلك المكتوبة بشرًا.
التفوق على دردشات قوية ومضاهاة الخبراء
في هذا المعيار، تفوق OpenScholar على كل من النماذج اللغوية القياسية والأدوات الأقدم التي تضيف الاستخراج إلى دردشة عامة. نسخة مدمجة بعثمانية مليارات معلمة، مدرّبة تمامًا على بيانات مفتوحة، أدت أفضل في مهمة تركيب متعددة الأوراق الصعبة من GPT-4o ونظام منافس يُدعى PaperQA2، على الرغم من اعتماد الأخيرين على نماذج ملكية أكبر. نتيجة لافتة كانت معدل اختلاق المراجع لدى الدردشات العادية: في 78–90 بالمئة من الحالات، تضمنت قوائم الاستشهادات أوراقًا غير موجودة أو لا تدعم الادعاءات. بالمقابل، كانت دقة استشهادات OpenScholar تضاهي خبراء بشريين. عندما قارن الخبراء الإجابات مباشرة، فضلوا OpenScholar-8B على الإجابات المكتوبة بخبرة نحو نصف الوقت، وفضلوا خط أنابيب OpenScholar المبني على GPT-4o نحو 70 بالمئة من الوقت، ويرجع ذلك إلى حد كبير لأن الذكاء الاصطناعي غطى دراسات أكثر صلة ونظمها بوضوح.
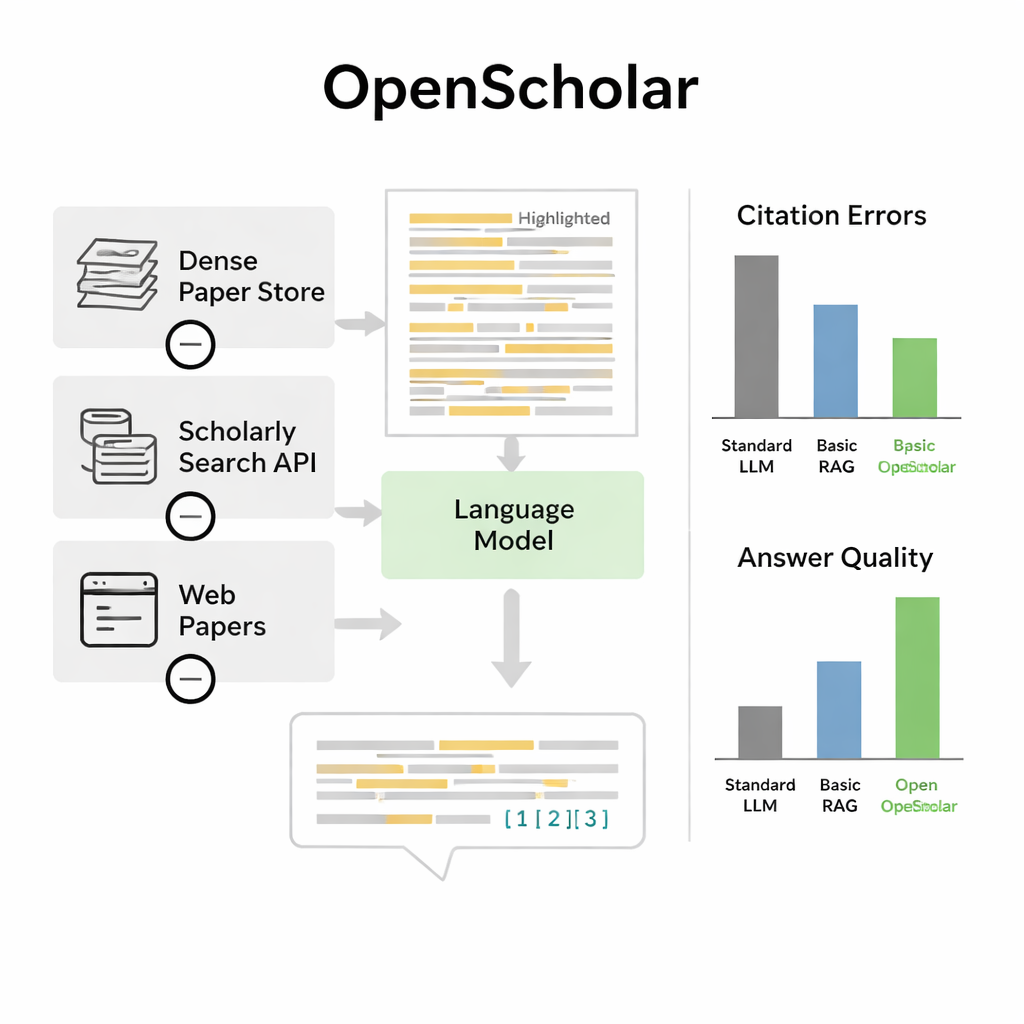
الحدود والتحسينات المستقبلية
رغم هذه المكاسب، يؤكد المؤلفون أن OpenScholar ليس بديلاً عن العلماء. لا يزال النظام قد يغفل الأوراق الأكثر تمثيلاً، أو يبالغ في أهمية أعمال أقل أهمية، أو يقدم أخطاء واقعية، خصوصًا في النماذج الأصغر حجمًا. للمؤشر نفسه حدود أيضًا: يركز أساسًا على علوم الحاسوب والطب الحيوي والفيزياء، والأسئلة المعلّمة بعناية لا تزال قليلة نسبيًا لأن وقت الخبراء مكلف. كما تكافح التقييمات لالتقاط خصال أكثر دقة، مثل ما إذا كانت الاستشهادات تبرز العمل الأساسي حقًا أو ما إذا كانت الإجابة ستوجه تجربة جديدة فعليًا.
ما يعنيه هذا للعلم اليومي
بالنسبة لغير المختصين، الخلاصة الأساسية هي أن الأدوات المصممة بعناية يمكنها بالفعل مساعدة العلماء في الانتقال عبر الأدبيات العلمية بفعالية أكبر، بشرط أن تكون مرتبطة ببيانات حقيقية وتخضع لمعايير صارمة للأدلة والشفافية. يوضح OpenScholar أنه عندما يُبنى نظام ذكاء اصطناعي من الأساس لاسترجاع وفحص واستشهاد الأوراق الحقيقية—وعندما تُختبر أداؤه مقابل خبراء بشريين—فإنه يمكن أن ينتج ملخصات أدبية ليست مقروءة فحسب بل قابلة للتحقق أيضًا. عمليًا، قد تتيح مثل هذه الأدوات للباحثين التركيز أكثر على تصميم التجارب وتفسير النتائج، مع إبقاء البشر في المقام الأول مسؤولين عن الحكم على ما هو صحيح ومهم.
الاستشهاد: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
الكلمات المفتاحية: مراجعة الأدبيات العلمية, نماذج لغوية مدعومة بالاستخراج, OpenScholar, دقة الاستشهادات, أدوات البحث بالذكاء الاصطناعي